多通道(比如RGB三通道)卷积过程
今天一个同学问 卷积过程好像是对 一个通道的图像进行卷积, 比如10个卷积核,得到10个feature map, 那么输入图像为RGB三个通道呢,输出就为 30个feature map 吗, 答案肯定不是的, 输出的个数依然是 卷积核的个数。 可以查看常用模型,比如lenet 手写体,Alex imagenet 模型, 每一层输出feature map 个数 就是该层卷积核的个数。
对于单通道图像,若利用10个卷积核进行卷积计算,可以得到10个特征图;若输入为多通道图像,则输出特征图的个数依然是卷积核的个数(10个)。
1、 一通道单个卷积核卷积过程
2、 一通道 多个卷积核卷积过程
一个卷积核得到的特征提取是不充分的,我们可以添加多个卷积核,比如32个卷积核,可以学习32种特征。在有多个卷积核时,如下图所示:输出就为32个feature map
3、 多通道的多个卷积核
下图展示了在四个通道上的卷积操作,有两个卷积核,生成两个通道。其中需要注意的是,四个通道上每个通道对应一个卷积核,先将w2忽略,只看w1,那么在w1的某位置(i,j)处的值,是由四个通道上(i,j)处的卷积结果相加然后再取激活函数值得到的。 所以最后得到两个feature map, 即输出层的卷积核核个数为 feature map 的个数。
所以,在上图由4个通道卷积得到2个通道的过程中,参数的数目为4×2×2×2个,其中4表示4个通道,第一个2表示生成2个通道,最后的2×2表示卷积核大小。
图片:假设图片的宽度为width:W,高度为height:H,图片的通道数为D,一般目前都用RGB三通道D=3,为了通用性,通道数用D表示;
卷积核:卷积核大小为K*K,由于处理的图片是D通道的,因此卷积核其实也就是K*K*D大小的,因此,对于RGB三通道图像,在指定kernel_size的前提下,真正的卷积核大小是kernel_size*kernel_size*3。
对于D通道图像的各通道而言,是在每个通道上分别执行二维卷积,然后将D个通道加起来,得到该位置的二维卷积输出,对于RGB三通道图像而言,就是在R,G,B三个通道上分别使用对应的每个通道上的kernel_size*kernel_size大小的核去卷积每个通道上的W*H的图像,然后将三个通道卷积得到的输出相加,得到二维卷积输出结果。因此,若有M个卷积核,可得到M个二维卷积输出结果,在有padding的情况下,能保持输出图片大小和原来的一样,因此是output(W,H,M)。
下面的图动态形象地展示了三通道图像卷积层的计算过程:
下面是常见模型, 理解一下 每层feature map 个数,为上一层卷积核的个数
下图即为Alex的CNN结构图。需要注意的是,该模型采用了2-GPU并行结构,即第1、2、4、5卷积层都是将模型参数分为2部分进行训练的。在这里,更进一步,并行结构分为数据并行与模型并行。数据并行是指在不同的GPU上,模型结构相同,但将训练数据进行切分,分别训练得到不同的模型,然后再将模型进行融合。而模型并行则是,将若干层的模型参数进行切分,不同的GPU上使用相同的数据进行训练,得到的结果直接连接作为下一层的输入。
上图模型的基本参数为:
输入:224×224大小的图片,3通道
第一层卷积:5×5大小的卷积核96个,每个GPU上48个。
第一层max-pooling:2×2的核。
第二层卷积:3×3卷积核256个,每个GPU上128个。
第二层max-pooling:2×2的核。
第三层卷积:与上一层是全连接,3*3的卷积核384个。分到两个GPU上个192个。
第四层卷积:3×3的卷积核384个,两个GPU各192个。该层与上一层连接没有经过pooling层。
第五层卷积:3×3的卷积核256个,两个GPU上个128个。
第五层max-pooling:2×2的核。
第一层全连接:4096维,将第五层max-pooling的输出连接成为一个一维向量,作为该层的输入。
第二层全连接:4096维
Softmax层:输出为1000,输出的每一维都是图片属于该类别的概率。
4 DeepID网络结构
DeepID网络结构是香港中文大学的Sun Yi开发出来用来学习人脸特征的卷积神经网络。每张输入的人脸被表示为160维的向量,学习到的向量经过其他模型进行分类,在人脸验证试验上得到了97.45%的正确率,更进一步的,原作者改进了CNN,又得到了99.15%的正确率。
如下图所示,该结构与ImageNet的具体参数类似,所以只解释一下不同的部分吧。
上图中的结构,在最后只有一层全连接层,然后就是softmax层了。论文中就是以该全连接层作为图像的表示。在全连接层,以第四层卷积和第三层max-pooling的输出作为全连接层的输入,这样可以学习到局部的和全局的特征。
下面讲一下,caffe中的实现。

Caffe中的卷积计算是将卷积核矩阵和输入图像矩阵变换为两个大的矩阵A与B,然后A与B进行矩阵相乘得到结果C(利用GPU进行矩阵相乘的高效性),三个矩阵的说明如下:
(1)在矩阵A中
M为卷积核个数,K=k*k,等于卷积核大小,即第一个矩阵每行为一个卷积核向量(是将二维的卷积核转化为一维),总共有M行,表示有M个卷积核。
(2)在矩阵B中
N=((image_h + 2*pad_h – kernel_h)/stride_h+ 1)*((image_w +2*pad_w – kernel_w)/stride_w + 1)
image_h:输入图像的高度
image_w:输入图像的宽度
pad_h:在输入图像的高度方向两边各增加pad_h个单位长度(因为有两边,所以乘以2)
pad_w:在输入图像的宽度方向两边各增加pad_w个单位长度(因为有两边,所以乘以2)
kernel_h:卷积核的高度
kernel_w:卷积核的宽度
stride_h:高度方向的滑动步长;
stride_w:宽度方向的滑动步长。
因此,N为输出图像大小的长宽乘积,也是卷积核在输入图像上滑动可截取的最大特征数。
K=k*k,表示利用卷积核大小的框在输入图像上滑动所截取的数据大小,与卷积核大小一样大。
(3)在矩阵C中
矩阵C为矩阵A和矩阵B相乘的结果,得到一个M*N的矩阵,其中每行表示一个输出图像即feature map,共有M个输出图像(输出图像数目等于卷积核数目)
(在Caffe中是使用src/caffe/util/im2col.cu中的im2col和col2im来完成矩阵的变形和还原操作)
举个例子(方便理解):
假设有两个卷积核为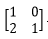 与
与 ,因此M=2,kernel_h=2,kernel_w=2,K= kernel_h * kernel_w=4
,因此M=2,kernel_h=2,kernel_w=2,K= kernel_h * kernel_w=4
输入图像矩阵为 ,因此image_h=3,image_w=3,令边界扩展为0即pad_h=0,pad_w=0,滑动步长为1,即stride_h=1,stride_w=1
,因此image_h=3,image_w=3,令边界扩展为0即pad_h=0,pad_w=0,滑动步长为1,即stride_h=1,stride_w=1
故N=[(3+2*0-2)/1+1]*[ (3+2*0-2)/1+1]=2*2=4
A矩阵(M*K)为 (一行为一个卷积核),B矩阵(K*N)为
(一行为一个卷积核),B矩阵(K*N)为 (B矩阵的每一列为一个卷积核要卷积的大小)
(B矩阵的每一列为一个卷积核要卷积的大小)
A 矩阵的由来:::
B矩阵的由来:(caffe 有 imtocol.cpp代码,专门用于实现)
C=A*B=*=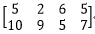
C中的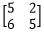 与
与 分别为两个输出特征图像即feature map。验证了 有几个卷积核就有几个feature map
分别为两个输出特征图像即feature map。验证了 有几个卷积核就有几个feature map
在Caffe源码中,src/caffe/util/math_functions.cu(如果使用CPU则是src/util/math_functions.cpp)中的caffe_gpu_gemm()函数,其中有两个矩阵A(M*K)
与矩阵 B(K*N),大家可以通过输出M、K、N的值即相应的矩阵内容来验证上述的原理,代码中的C矩阵与上述的C矩阵不一样,代码中的C矩阵存储的是偏置bias,
是A 与B相乘后得到M*N大小的矩阵,然后再跟这个存储偏置的矩阵C相加完成卷积过程。如果是跑Mnist训练网络的话,可以看到第一个卷积层卷积过程中,
M=20,K=25,N=24*24=576。
(caffe中涉及卷积具体过程的文件主要有:src/caffe/layers/conv_layer.cu、src/caffe/layers/base_conv_layer.cpp、 src/caffe/util/math_functions.cu、src/caffe/util/im2col.cu)
另外大家也可以参考知乎上贾扬清大神的回答,帮助理解http://www.zhihu.com/question/28385679
(对于他给出的ppt上的C表示图像通道个数,如果是RGB图像则通道数为3,对应于caffe代码中的变量为src/caffe/layers/base_conv_layer.cpp中
函数forward_gpu_gemm中的group_)
贾扬清的PPT如下:
下面看这个就简单多了, im2col.cpp 的代码也好理解了