Linux性能优化-综合案例
目录
Docker中的Tomcat
服务器时不时丢包
内核线程CPU利用率高
服务器吞吐量下降
Docker中的Tomcat
运行
docker run --name tomcat --cpus 0.1 -m 512M -p 8080:8080 -itd feisky/tomcat:8查看日志
docker logs ee579b51fb74 -f
11-Mar-2019 04:23:08.358 INFO [localhost-startStop-1]
org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory
[/usr/local/tomcat/webapps/docs] has finished in [409] ms
11-Mar-2019 04:23:08.450 INFO [localhost-startStop-1]
org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory
[/usr/local/tomcat/webapps/manager]
11-Mar-2019 04:23:08.854 INFO [localhost-startStop-1]
org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory
[/usr/local/tomcat/webapps/manager] has finished in [404] ms
11-Mar-2019 04:23:08.953 INFO [main] org.apache.coyote.AbstractProtocol.start Starting
ProtocolHandler ["http-nio-8080"]
11-Mar-2019 04:23:09.649 INFO [main] org.apache.coyote.AbstractProtocol.start Starting
ProtocolHandler ["ajp-nio-8009"]
11-Mar-2019 04:23:10.051 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in
17201 ms
访问网页
curl http://localhost:8080/
。。。
1: <%
2: byte data[] = new byte[256*1024*1024];
3: out.println("Hello, wolrd!");
4: %>
。。。进入容器中查看Java内容设置,free结果
docker exec tomcat java -XX:+PrintFlagsFinal -version | grep HeapSize
uintx ErgoHeapSizeLimit = 0 {product}
uintx HeapSizePerGCThread = 87241520 {product}
uintx InitialHeapSize := 16777216 {product}
uintx LargePageHeapSizeThreshold = 134217728 {product}
uintx MaxHeapSize := 260046848 {product}
openjdk version "1.8.0_181"
OpenJDK Runtime Environment (build 1.8.0_181-8u181-b13-2~deb9u1-b13)
OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
docker exec tomcat free -m
total used free shared buff/cache available
Mem: 985 221 162 0 601 623
Swap: 0 0 0因为无法重现案例中的情况,这里就简单总结一下最后的结论
- 容器设置的内容大小,但容器内运行的Java看不到这个参数,容器内的Java程序读取系统的物理内存,于是设置了很大的内存,会导致OOM,或者内存换入换出
- 确保设置容器资源限制的同时,配置好JVM的资源选项(如堆内存等),如果升级到JDK10可以自动解决此问题
- 有时候一开始图省事,资源限制用的是默认值(容器可以100%的使用物理机资源),等容器增长上来时就会出现各
- 种异常问题,根据就是某个应用资源使用过高导致整台机器短期内无法响应
- 碰到容器化的应用程序性能时,依然可以使用在物理机器上的那一套方式,但容器性能分析有些区别
- 容器本身通过cgroups进行资源隔离,在分析时要考虑cgroups对应用程序的影响
- 容器的文件系统,网络协议等跟主机隔离,虽然在容器外面,也可以分析容器的行为,但进入容器的命名空间内部更方便排查
- 容器的运行可能还会依赖其他组件,如葛总网络插件(如CNI),存储插件(如CSI),设备插件(如GPU)等,让容器的性能分析更加复杂,在分析容器性能时不要忘记考虑他们对性能的影响
服务器时不时丢包
容器化后对性能的影响
- cgroups会影响容器应用的运行
- iptables中的NAT,会影响容器的网络性能
- 叠加文件系统,会影响应用的I/O性能等
启动环境
docker run --name nginx --hostname nginx --privileged -p 8080:8080 -itd feisky/nginx:drop执行hping3测试服务器
hping3 -c 10 -S -p 8080 【服务端IP】
HPING 【服务端IP】 (eth0 【服务端IP】): S set, 40 headers + 0 data bytes
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=2 win=0 rtt=2.4 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=8 win=0 rtt=2.2 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=9 win=0 rtt=2.6 ms
--- 【服务端IP】 hping statistic ---
10 packets transmitted, 3 packets received, 70% packet loss
round-trip min/avg/max = 2.2/2.4/2.6 ms
hping3 -c 10 -S -p 8080 localhost
HPING localhost (lo 127.0.0.1): S set, 40 headers + 0 data bytes
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=8080 flags=SA seq=0 win=65495 rtt=0.1 ms
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=8080 flags=SA seq=1 win=65495 rtt=0.1 ms
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=8080 flags=SA seq=2 win=65495 rtt=0.1 ms
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=8080 flags=SA seq=3 win=65495 rtt=0.1 ms
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=8080 flags=SA seq=4 win=65495 rtt=0.1 ms
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=8080 flags=SA seq=5 win=65495 rtt=0.1 ms
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=8080 flags=SA seq=6 win=65495 rtt=0.1 ms
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=8080 flags=SA seq=7 win=65495 rtt=0.1 ms
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=8080 flags=SA seq=8 win=65495 rtt=0.1 ms
len=44 ip=127.0.0.1 ttl=64 DF id=0 sport=8080 flags=SA seq=9 win=65495 rtt=0.1 ms
--- localhost hping statistic ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 0.1/0.1/0.1 ms在回忆下两台主机之间的数据包收发流程
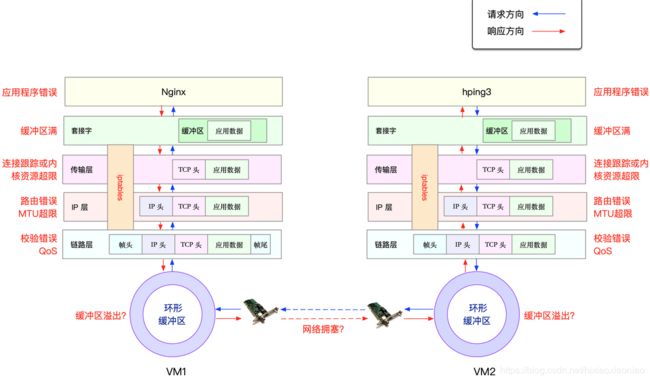
进入nginx后台操作
netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 100 290 0 68 0 162 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0 LRU上述参数的解释
- RX-RO,RX-ERR 表示接收时的总包数,总错误数
- RX-DRP,RX-OVR 表示进入Ring Buffer后因其他原因(如内存不足)导致的丢包数,及Ring Buffer溢出的丢包数
- TX-OK,TX-ERR 表示发送时的总包数,总错误数
- TX-DRP,TX-OVR,表示发送时Ring Buffer的丢包,和溢出数
由于Docker容器的虚拟网卡,实际上是一对veth pair一端接入容器中作用eth0,另一端在主机中接入docker0网桥中,
veth驱动并没有实现网络统计的功能,所以使用ethtool -S命令,无法得到网卡接收发送数据的汇总信息
查看tc配置规则,显示有30%的丢包率
tc -s qdisc show dev eth0
qdisc netem 8001: root refcnt 2 limit 1000 loss 30%
Sent 9199 bytes 163 pkt (dropped 83, overlimits 0 requeues 0)
backlog 0b 0p requeues 0删除tc规则
tc qdisc del dev eth0 root netem loss 30%再看ping3仍然有丢包
hping3 -c 10 -S -p 8080 【服务端IP】
HPING 【服务端IP】 (eth0 【服务端IP】): S set, 40 headers + 0 data bytes
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=0 win=0 rtt=2.6 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=1 win=0 rtt=1.9 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=3 win=0 rtt=2.3 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=7 win=0 rtt=2.3 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=9 win=0 rtt=2.4 ms
--- 【服务端IP】 hping statistic ---
10 packets transmitted, 5 packets received, 50% packet loss
round-trip min/avg/max = 1.9/2.3/2.6 ms再看网络和传输层
还是用netstat命令,查看网络和传输层的接收,发送,丢包,错误情况
netstat -s
Ip:
Forwarding: 1 //开启转发
153 total packets received //总收包数
0 forwarded //转发包数
0 incoming packets discarded //接收包数
106 incoming packets delivered //接收的数据包
126 requests sent out //发出的数据包
21 outgoing packets dropped
Icmp:
0 ICMP messages received //收到的ICMP包
0 input ICMP message failed //收到的ICMP失败数
ICMP input histogram:
0 ICMP messages sent //ICMP发送数
0 ICMP messages failed //ICMP失败数
ICMP output histogram:
Tcp:
3 active connection openings //主动连接数
0 passive connection openings //被动连接数
0 failed connection attempts //失败连接尝试数
0 connection resets received //接收的连接重置数
0 connections established //建立连接数
105 segments received //已接收报文数
123 segments sent out //已发送报文数
30 segments retransmitted //重传报文数
2 bad segments received //错误报文数
89 resets sent //发出的连接重置数
Udp:
1 packets received
0 packets to unknown port received
0 packet receive errors
18 packets sent
0 receive buffer errors
0 send buffer errors
UdpLite:
TcpExt:
1 TCP sockets finished time wait in fast timer
0 packet headers predicted
6 acknowledgments not containing data payload received
1 predicted acknowledgments
TCPSackRecovery: 1
3 congestion windows recovered without slow start after partial ack
TCPLostRetransmit: 11
2 timeouts in loss state
2 fast retransmits
TCPTimeouts: 27 //超时数
TCPLossProbes: 3
TCPSackRecoveryFail: 1
TCPDSACKRecv: 2
2 connections aborted due to timeout
TCPSpuriousRTOs: 1
TCPSackShiftFallback: 3
TCPRetransFail: 10
TCPRcvCoalesce: 1
TCPOFOQueue: 3
TCPChallengeACK: 2
TCPSYNChallenge: 2
TCPSynRetrans: 4 //SYN重传数
TCPOrigDataSent: 15
TCPDelivered: 17
IpExt:
InOctets: 8060
OutOctets: 7137
InNoECTPkts: 155
InECT0Pkts: 1netstat汇总了IP,ICMP,TCP,UDP等各种协议的收发统计信息,还包括了丢包,错误,重传数等
查看主机的内核连接跟综述,确定不是连接数量导致的
sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 1024
[root@iz2zege42v3jtvyj2oecuzz ~]# sysctl net.netfilter.nf_conntrack_count
net.netfilter.nf_conntrack_count = 7再看iptables
它是基于Netfilter框架,通过一系列规则,对网络数据包进行过滤(如防火墙)和修改(NAT)
这些iptables规则,统一管理在一系列的表中,包括filter(用于过滤),nat(用于NAT),mangle(修改分组数据),
raw(用于原始数据包)
而每张表又可以包括一系列的链,用于对iptables规则进行分组管理
对于丢包问题,可能是被filter表中的规则给丢弃了
docker exec -it nginx bash
iptables -nvL
Chain INPUT (policy ACCEPT 128 packets, 6456 bytes)
pkts bytes target prot opt in out source destination
63 3224 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 139 packets, 7657 bytes)
pkts bytes target prot opt in out source destination
51 2772 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981这里有两条DROP规则的统计不是0,分别是INPUT和OUTPUT,它们使用的是statistic模块,进行随机30%的丢包
另外匹配规则是对于所有的源和目标IP删除这些规则
root@nginx:/# iptables -t filter -D INPUT -m statistic --mode random --probability 0.30 -j DROP
root@nginx:/# iptables -t filter -D OUTPUT -m statistic --mode random --probability 0.30 -j DROP
root@nginx:/# iptables -nvL
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination 再用hping3测试一下
hping3 -c 10 -S -p 8080 【服务端IP】
HPING 【服务端IP】 (eth0 【服务端IP】): S set, 40 headers + 0 data bytes
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=0 win=0 rtt=10.7 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=1 win=0 rtt=2.6 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=2 win=0 rtt=3.1 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=3 win=0 rtt=2.9 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=4 win=0 rtt=3.5 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=5 win=0 rtt=2.6 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=6 win=0 rtt=8.5 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=7 win=0 rtt=2.8 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=8 win=0 rtt=2.0 ms
len=40 ip=【服务端IP】 ttl=63 DF id=0 sport=8080 flags=RA seq=9 win=0 rtt=3.1 ms
--- 【服务端IP】 hping statistic ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 2.0/4.2/10.7 ms抓包看一下
tcpdump -i docker0 -nn port 8080
10:03:29.907668 IP 【客户端IP】.40452 > 172.18.0.2.8080: Flags [S], seq 3081661064, win 64240, options [mss 1460,sackOK,TS val 634980266 ecr 0,nop,wscale 7], length 0
10:03:29.907700 IP 172.18.0.2.8080 > 【客户端IP】.40452: Flags [R.], seq 0, ack 3081661065, win 0, length 0TCP的SYN包过去之后,就直接返回了RST包,连接被拒绝了
容器中的链路层发现有丢包
docker exec -it nginx bash
root@nginx:/# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 100 419 0 68 0 261 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0 LRUhping的SYN包可以接收,因为这个TCP包很小,而正常的HTTP包很大,MTU又很小所以被拒绝了,调整一下MTU即可
ifconfig eth0 mtu 1500注意,最后容器需要重新改成这样启动,否则发送的数据包都会返回RST的
docker run --name nginx --hostname nginx --privileged -p 80:80 -itd feisky/nginx:drop
curl http://【服务端IP】/
Welcome to nginx!
Welcome to nginx!
If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.
For online documentation and support please refer to
nginx.org.
Commercial support is available at
nginx.com.
Thank you for using nginx.
内核线程CPU利用率高
Linux在启动过程中,有三个特殊进程,也就是PID最小的三个进程
- 0号进程是 idle进程,是系统创建的第一个进程,它在初始化1号和2号进程后,演变为空闲进程,当CPU上没有其他任务执行时,就会运行它
- 1号进程为init进程,通常是systemd进程,在用户态运行,用来管理其他用户态进程
- 2号进程为kthreadd进程,在内核态运行,用来管理内核线程
要查找内核线程,从2号进程开始,查找它的子孙进程,核心线程名称都在括号中
ps -f --ppid 2 -p 2
UID PID PPID C STIME TTY TIME CMD
root 2 0 0 Feb20 ? 00:00:00 [kthreadd]
root 3 2 0 Feb20 ? 00:00:00 [rcu_gp]
root 4 2 0 Feb20 ? 00:00:00 [rcu_par_gp]
root 6 2 0 Feb20 ? 00:00:00 [kworker/0:0H-kb]
root 8 2 0 Feb20 ? 00:00:00 [mm_percpu_wq]
root 9 2 0 Feb20 ? 00:00:04 [ksoftirqd/0]
root 10 2 0 Feb20 ? 00:02:26 [rcu_sched]
root 11 2 0 Feb20 ? 00:00:04 [migration/0]
root 13 2 0 Feb20 ? 00:00:00 [cpuhp/0]
root 14 2 0 Feb20 ? 00:00:00 [kdevtmpfs]
root 15 2 0 Feb20 ? 00:00:00 [netns]
root 16 2 0 Feb20 ? 00:00:00 [kauditd]
root 17 2 0 Feb20 ? 00:00:00 [khungtaskd]
root 18 2 0 Feb20 ? 00:00:00 [oom_reaper]
root 19 2 0 Feb20 ? 00:00:00 [writeback]
root 20 2 0 Feb20 ? 00:00:00 [kcompactd0]
root 21 2 0 Feb20 ? 00:00:00 [ksmd]
root 22 2 0 Feb20 ? 00:00:06 [khugepaged]
root 23 2 0 Feb20 ? 00:00:00 [crypto]
root 24 2 0 Feb20 ? 00:00:00 [kintegrityd]
root 25 2 0 Feb20 ? 00:00:00 [kblockd]
root 26 2 0 Feb20 ? 00:00:00 [tpm_dev_wq]
root 27 2 0 Feb20 ? 00:00:00 [md]
root 28 2 0 Feb20 ? 00:00:00 [edac-poller]
root 29 2 0 Feb20 ? 00:00:00 [devfreq_wq]
root 30 2 0 Feb20 ? 00:00:00 [watchdogd]
root 34 2 0 Feb20 ? 00:00:02 [kswapd0]
root 121 2 0 Feb20 ? 00:00:00 [kthrotld]
root 122 2 0 Feb20 ? 00:00:00 [acpi_thermal_pm]
root 123 2 0 Feb20 ? 00:00:00 [kmpath_rdacd]
root 124 2 0 Feb20 ? 00:00:00 [kaluad]
root 125 2 0 Feb20 ? 00:00:00 [nvme-wq]
root 126 2 0 Feb20 ? 00:00:00 [nvme-reset-wq]
root 127 2 0 Feb20 ? 00:00:00 [nvme-delete-wq]
root 128 2 0 Feb20 ? 00:00:00 [ipv6_addrconf]
root 129 2 0 Feb20 ? 00:00:00 [kstrp]
root 145 2 0 Feb20 ? 00:00:00 [charger_manager]
root 313 2 0 Feb20 ? 00:00:00 [ata_sff]
root 315 2 0 Feb20 ? 00:00:00 [scsi_eh_0]
root 316 2 0 Feb20 ? 00:00:00 [scsi_tmf_0]
root 317 2 0 Feb20 ? 00:00:00 [scsi_eh_1]
root 318 2 0 Feb20 ? 00:00:00 [scsi_tmf_1]
root 320 2 0 Feb20 ? 00:00:00 [ttm_swap]
root 337 2 0 Feb20 ? 00:00:06 [kworker/0:1H-kb]
root 349 2 0 Feb20 ? 00:00:04 [jbd2/vda1-8]
root 350 2 0 Feb20 ? 00:00:00 [ext4-rsv-conver]
root 11517 2 0 Mar17 ? 00:00:00 [kworker/u2:2-ev]
root 13537 2 0 08:45 ? 00:00:00 [kworker/0:0-ata]
root 14349 2 0 09:01 ? 00:00:00 [kworker/0:4-ata]
root 14591 2 0 09:06 ? 00:00:00 [kworker/0:1-eve]
root 32604 2 0 Mar16 ? 00:00:00 [kworker/u2:1-ev]查找所有带[ ] 的进程
ps -ef | grep "\[.*\]"
root 3 2 0 Feb20 ? 00:00:00 [rcu_gp]
root 4 2 0 Feb20 ? 00:00:00 [rcu_par_gp]
root 6 2 0 Feb20 ? 00:00:00 [kworker/0:0H-kb]
root 8 2 0 Feb20 ? 00:00:00 [mm_percpu_wq]
root 9 2 0 Feb20 ? 00:00:04 [ksoftirqd/0]
root 10 2 0 Feb20 ? 00:02:26 [rcu_sched]
root 11 2 0 Feb20 ? 00:00:04 [migration/0]
root 13 2 0 Feb20 ? 00:00:00 [cpuhp/0]
root 14 2 0 Feb20 ? 00:00:00 [kdevtmpfs]
root 15 2 0 Feb20 ? 00:00:00 [netns]
root 16 2 0 Feb20 ? 00:00:00 [kauditd]
root 17 2 0 Feb20 ? 00:00:00 [khungtaskd]
root 18 2 0 Feb20 ? 00:00:00 [oom_reaper]
root 19 2 0 Feb20 ? 00:00:00 [writeback]
root 20 2 0 Feb20 ? 00:00:00 [kcompactd0]
root 21 2 0 Feb20 ? 00:00:00 [ksmd]
root 22 2 0 Feb20 ? 00:00:06 [khugepaged]
root 23 2 0 Feb20 ? 00:00:00 [crypto]
root 24 2 0 Feb20 ? 00:00:00 [kintegrityd]
root 25 2 0 Feb20 ? 00:00:00 [kblockd]
root 26 2 0 Feb20 ? 00:00:00 [tpm_dev_wq]
root 27 2 0 Feb20 ? 00:00:00 [md]
root 28 2 0 Feb20 ? 00:00:00 [edac-poller]
root 29 2 0 Feb20 ? 00:00:00 [devfreq_wq]
root 30 2 0 Feb20 ? 00:00:00 [watchdogd]
root 34 2 0 Feb20 ? 00:00:02 [kswapd0]
root 121 2 0 Feb20 ? 00:00:00 [kthrotld]
root 122 2 0 Feb20 ? 00:00:00 [acpi_thermal_pm]
root 123 2 0 Feb20 ? 00:00:00 [kmpath_rdacd]
root 124 2 0 Feb20 ? 00:00:00 [kaluad]
root 125 2 0 Feb20 ? 00:00:00 [nvme-wq]
root 126 2 0 Feb20 ? 00:00:00 [nvme-reset-wq]
root 127 2 0 Feb20 ? 00:00:00 [nvme-delete-wq]
root 128 2 0 Feb20 ? 00:00:00 [ipv6_addrconf]
root 129 2 0 Feb20 ? 00:00:00 [kstrp]
root 145 2 0 Feb20 ? 00:00:00 [charger_manager]
root 313 2 0 Feb20 ? 00:00:00 [ata_sff]
root 315 2 0 Feb20 ? 00:00:00 [scsi_eh_0]
root 316 2 0 Feb20 ? 00:00:00 [scsi_tmf_0]
root 317 2 0 Feb20 ? 00:00:00 [scsi_eh_1]
root 318 2 0 Feb20 ? 00:00:00 [scsi_tmf_1]
root 320 2 0 Feb20 ? 00:00:00 [ttm_swap]
root 337 2 0 Feb20 ? 00:00:06 [kworker/0:1H-kb]
root 349 2 0 Feb20 ? 00:00:04 [jbd2/vda1-8]
root 350 2 0 Feb20 ? 00:00:00 [ext4-rsv-conver]
root 11517 2 0 Mar17 ? 00:00:00 [kworker/u2:2-ev]
root 13537 2 0 08:45 ? 00:00:00 [kworker/0:0-ata]
root 14349 2 0 09:01 ? 00:00:00 [kworker/0:4-ata]
root 14591 2 0 09:06 ? 00:00:00 [kworker/0:1-eve]
root 14811 14782 0 09:09 pts/1 00:00:00 grep --color=auto \[.*\]
root 32604 2 0 Mar16 ? 00:00:00 [kworker/u2:1-ev]
在性能分析时常见的内核线程如下
- ksoftirqd,用来处理软中断的内核线程
- kswapd0,用于内存回收
- sworker,用于执行诶和工作队列,分为绑定CPU(名称格式为kworker/CPU:ID)和未绑定CPU(格式kworker/uPOOL:ID)
- migration,在负载均衡过程中,把进程迁移到CPU上,每个CPU都有一个migration内核线程
- jdb2/sda1-8,JDB是Journaling Block Device的缩写,用来为文件系统提供日志功能,以保证数据的完整性,名称中
- 的sda1-8,表示磁盘分区名称和设备号,每个使用了ext4文件系统的磁盘分区,都会有一个jbd2内核线程
- pdflush,用于将内存中的脏页(被修改过,但还未写入磁盘的文件页)写入磁盘(已在3.10种合并入了kworker中)
启动一个案列的nginx
docker run -itd --name=nginx -p 8080:8080 nginx访问测试一下
curl http://172.18.0.4/
Welcome to nginx!
Welcome to nginx!
If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.
For online documentation and support please refer to
nginx.org.
Commercial support is available at
nginx.com.
Thank you for using nginx.
top发现,软中断比较高
top - 08:48:40 up 12:19, 3 users, load average: 0.26, 0.10, 0.07
Tasks: 100 total, 4 running, 95 sleeping, 1 stopped, 0 zombie
%Cpu(s): 16.6 us, 30.7 sy, 0.0 ni, 35.7 id, 0.0 wa, 0.0 hi, 17.0 si, 0.0 st
KiB Mem : 1014908 total, 63864 free, 723444 used, 227600 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 107796 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+COMMAND
5688 root 20 0 21348 992 784 R 36.3 0.1 0:39.86 hping3
5734 root 20 0 21348 992 784 R 25.0 0.1 0:00.75 hping3
5709 root 20 0 155088 5884 4536 S 0.7 0.6 0:00.07 sshd
3 root 20 0 0 0 0 S 0.3 0.0 0:00.60 ksoftirqd/0 负责软中断的进程是 ksoftirqd/0,但是一般的命令对这种内核态进程是无效的
#pstack 3 没结果
pstack 3
cat /proc/9/stack
[] rcu_gp_kthread+0x349/0x710
[] kthread+0xd1/0xe0
[] ret_from_fork_nospec_end+0x0/0x39
[] 0xffffffffffffffff
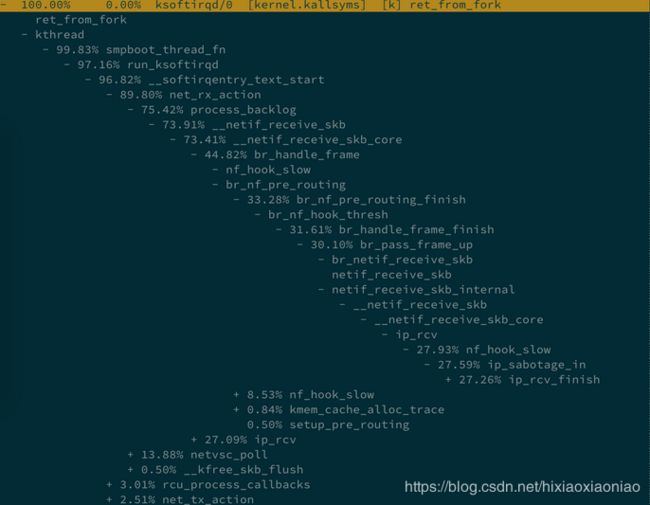
案例中给出的CPU消耗调用链如下
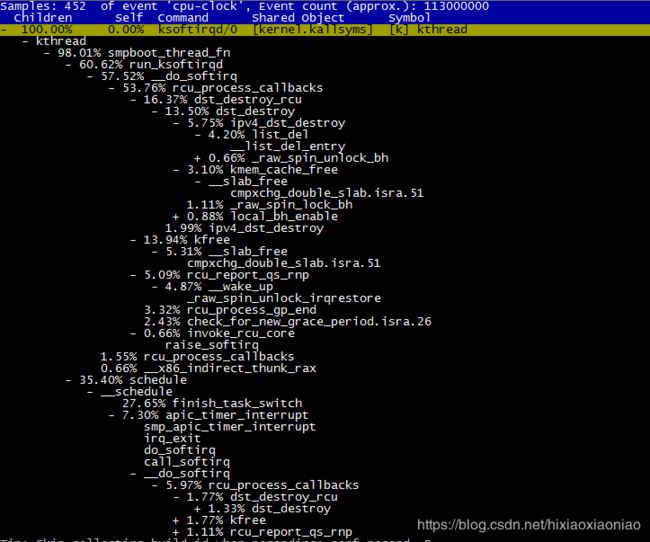
可能是机器原因,我的机器上的调用链如下,是花在了CPU调度上了
但通过这些函数,大致看出它的调用栈过程。
- net_rx_action 和 netif_receive_skb,表明这是接收网络包(rx 表示 receive)。
- br_handle_frame ,表明网络包经过了网桥(br 表示 bridge)。
- br_nf_pre_routing ,表明在网桥上执行了 netfilter 的 PREROUTING(nf 表示 netfilter)。而我们已经知道 PREROUTING 主要用来执行 DNAT,所以可以猜测这里有 DNAT 发生。
- br_pass_frame_up,表明网桥处理后,再交给桥接的其他桥接网卡进一步处理。比如,在新的网卡上接收网络包、执行 netfilter 过滤规则等等。
- docker 会自动为容器创建虚拟网卡、桥接到 docker0 网桥并配置 NAT 规则。这一过程,如下图所示:

借助火焰图,通过矢量图的形式,可以更直观的查看汇总结果
下面是针对mysql的火焰图示例
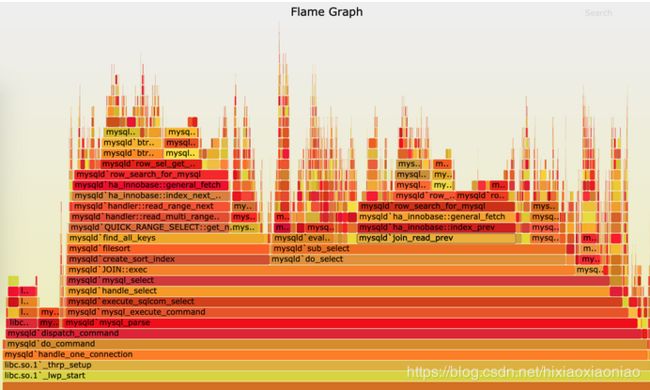
这张图看起来像是跳动的火焰,因此也就被称为火焰图。最重要的是区分清楚横轴和纵轴的含义。
- 横轴表示采样数和采样比例。一个函数占用的横轴越宽,就代表它的执行时间越长。同一层的多个函数,则是按照字母来排序。
- 纵轴表示调用栈,由下往上根据调用关系逐个展开。换句话说,上下相邻的两个函数中,下面的函数,是上面函数的父函数。这样,调用栈越深,纵轴就越高。
另外,要注意图中的颜色,并没有特殊含义,只是用来区分不同的函数。
火焰图是动态的矢量图格式,所以它还支持一些动态特性。比如,鼠标悬停到某个函数上时,就会自动显示这个函数的采样数和采样比例。当用鼠标点击函数时,火焰图就会把该层及其上的各层放大,方便观察这些处于火焰图顶部的调用栈的细节。
上面 mysql 火焰图的示例,就表示了 CPU 的繁忙情况,这种火焰图也被称为 on-CPU 火焰图。如果我们根据性能分析的目标来划分,火焰图可以分为下面这几种。
- on-CPU 火焰图:表示 CPU 的繁忙情况,用在 CPU 使用率比较高的场景中。
- off-CPU 火焰图:表示 CPU 等待 I/O、锁等各种资源的阻塞情况。
- 内存火焰图:表示内存的分配和释放情况。
- 热 / 冷火焰图:表示将 on-CPU 和 off-CPU 结合在一起综合展示。
- 差分火焰图:表示两个火焰图的差分情况,红色表示增长,蓝色表示衰减。差分火焰图常用来比较不同场景和不同时期的火焰图,以便分析系统变化前后对性能的影响情况。
安装火焰图
git clone https://github.com/brendangregg/FlameGraph
安装好工具后,要生成火焰图,其实主要需要三个步骤:
- 执行 perf script ,将 perf record 的记录转换成可读的采样记录;
- 执行 stackcollapse-perf.pl 脚本,合并调用栈信息;
- 执行 flamegraph.pl 脚本,生成火焰图。
也可以用管道来执行
perf record -a -g -p 3 -- sleep 30
perf script -i /root/test/perf.data | ./stackcollapse-perf.pl -all | ./flamegraph.pl > ksoftirqd.svg
执行成功后,使用浏览器打开 ksoftirqd.svg
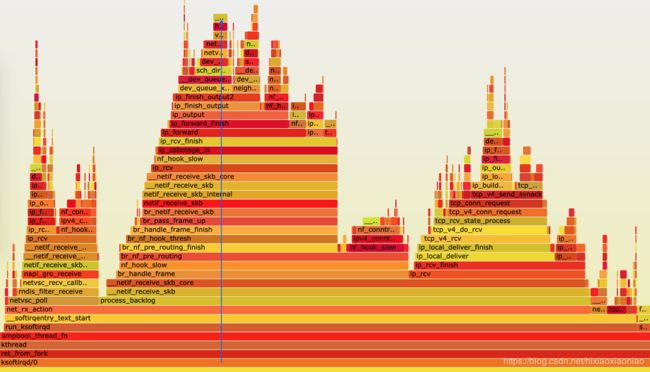
根据火焰图原理,这个图应该从下往上看,沿着调用栈中最宽的函数来分析执行次数最多的函数。
这儿看到的结果,其实跟刚才的 perf report 类似,中间这一团火就是最需要我们关注的地方。
可以得到跟刚才 perf report 中一样的结果:
- 最开始,还是 net_rx_action 到 netif_receive_skb 处理网络收包;
- 然后, br_handle_frame 到 br_nf_pre_routing ,在网桥中接收并执行 netfilter 钩子函数;
- 再向上, br_pass_frame_up 到 netif_receive_skb ,从网桥转到其他网络设备又一次接收。
不过最后,到了 ip_forward 这里,已经看不清函数名称了。需要点击 ip_forward,展开最上面这一块调用栈:
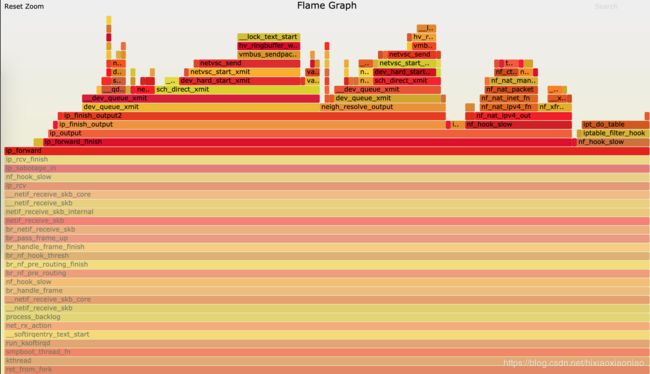
这样,就可以进一步看到 ip_forward 后的行为,也就是把网络包发送出去。
这个流程中的网络接收、网桥以及 netfilter 调用等,都是导致软中断 CPU 升高的重要因素,也就是影响网络性能的潜在瓶颈。
在理解这个调用栈时要注意。从任何一个点出发、纵向来看的整个调用栈,其实只是最顶端那一个函数的调用堆栈,
而非完整的内核网络执行流程。
另外,整个火焰图不包含任何时间的因素,所以并不能看出横向各个函数的执行次序。
服务器吞吐量下降
docker run --name nginx --network host --privileged -itd feisky/nginx-tp
docker run --name phpfpm --network host --privileged -itd feisky/php-fpm-tp
curl http://[nginx的IP]/
Hello World!
wrk --latency -c 1000 http://【nginx的IP】
Running 10s test @ http://【nginx的IP】
2 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 85.61ms 230.19ms 1.96s 91.33%
Req/Sec 368.17 198.62 1.60k 90.91%
Latency Distribution
50% 3.23ms
75% 6.70ms
90% 215.92ms
99% 1.24s
3697 requests in 10.06s, 785.30KB read
Socket errors: connect 970, read 0, write 0, timeout 8
Requests/sec: 367.61
Transfer/sec: 78.09KB
每秒369次请求,还有错误
继续观察30分钟
wrk --latency -c 1000 -d 1800 http://【nginx的IP】
ss -s
Total: 162 (kernel 226)
TCP: 155 (estab 10, closed 142, orphaned 0, synrecv 0, timewait 141/0), ports 0
Transport Total IP IPv6
* 226 - -
RAW 0 0 0
UDP 6 5 1
TCP 13 12 1
INET 19 17 2
FRAG 0 0 0
建立连接的只有10个,剩下的都是close和timewait状态
内核中的连接跟踪模块,有可能导致timewait问题,docker使用的iptables,就会使用连接跟踪来管理NAT
dmesg | tail
nf_conntrack:nf_conntrack:table full,dropping packet
但我的dmesg中却没有这种信息,
查看内核选项,连接跟踪数的最大限制,以及当前连接跟踪数
sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 200
sysctl net.netfilter.nf_conntrack_count
net.netfilter.nf_conntrack_count = 155
把连接跟踪数调大
sysctl -w net.netfilter.nf_conntrack_max=1048576
案例中出现了连接跟踪满了的情况,调大之后nginx每秒请求数就上去了,我这里没有
查看了网卡流量,快到顶了,可能是我这个机器性能不行带宽有限导致的
案列中显示的是nginx出现499错误,也就就是服务端还没来得及响应,客户端就关闭了
因为带宽有限,我这里没看到
docker logs nginx --tail 3
47.93.18.8 - - [27/Mar/2019:00:35:40 +0000] "GET / HTTP/1.1" 200 22 "-" "-" "-"
47.93.18.8 - - [27/Mar/2019:00:35:40 +0000] "GET / HTTP/1.1" 200 22 "-" "-" "-"
47.93.18.8 - - [27/Mar/2019:00:35:40 +0000] "GET / HTTP/1.1" 200 22 "-" "-" "-"
php容器出现了很多错误,提示超过了最大子进程数
docker logs phpfpm --tail 5
[27-Mar-2019 00:21:30] WARNING: [pool www] server reached max_children setting (5), consider raising it
[27-Mar-2019 00:32:38] WARNING: [pool www] server reached max_children setting (5), consider raising it
[27-Mar-2019 00:34:15] WARNING: [pool www] server reached max_children setting (5), consider raising it
[27-Mar-2019 00:34:59] WARNING: [pool www] server reached max_children setting (5), consider raising it
[27-Mar-2019 00:35:33] WARNING: [pool www] server reached max_children setting (5), consider raising it
停止旧容器,启动新的镜像
docker rm -f nginx phpfpm
docker run --name nginx --network host --privileged -itd feisky/nginx-tp:1
docker run --name phpfpm --network host --privileged -itd feisky/php-fpm-tp:1
wrk --latency -c 1000 http://[nginx的IP]
Running 10s test @ http://[nginx的IP]
2 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 81.46ms 226.29ms 1.84s 91.59%
Req/Sec 372.21 181.93 1.42k 92.93%
Latency Distribution
50% 3.12ms
75% 5.18ms
90% 209.37ms
99% 1.21s
3717 requests in 10.06s, 789.53KB read
Socket errors: connect 978, read 0, write 0, timeout 7
Requests/sec: 369.39
Transfer/sec: 78.46KB