Linux内存管理之SLAB分配器
注:本文讲述的SLAB相关代码是基于Linux内核v4.7,代码网址。
1、SLAB分配器的由来
在讲SLAB分配器之前先说两个概念: 内部碎片和外部碎片。
外部碎片指的是还没有被分配出去(不属于任何进程)但由于太小而无法分配给申请内存空间的新进程的内存空闲区域。外部碎片是除了任何已分配区域或页面外部的空闲存储块。这些存储块的总和可以满足当前申请的长度要求,但是由于它们的地址不连续或其他原因,使得系统无法满足当前申请。简单示例如下图:

如果某进程现在需要向操作系统申请地址连续的32K内存空间,注意是地址连续,实际上系统中当前共有10K+23K=33K空闲内存,但是这些空闲内存并不连续,所以不能满足进程的请求。这就是所谓的外部碎片,造成外部碎片的原因主要是进程或者系统频繁的申请和释放不同大小的一组连续页框。Linux操作系统中为了尽量避免外部碎片而采用了伙伴系统(Buddy System)算法。
内部碎片就是已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间;内部碎片是处于区域内部或页面内部的存储块,占有这些区域或页面的进程并不使用这个存储块,而在进程占有这块存储块时,系统无法利用它。直到进程释放它,或进程结束时,系统才有可能利用这个存储块。简单示例如下图:

某进程向系统申请了3K内存空间,系统通过伙伴系统算法可能分配给进程4K(一个标准页面)内存空间,导致剩余1K内存空间无法被系统利用,造成了浪费。这是由于进程请求内存大小与系统分配给它的内存大小不匹配造成的。由于伙伴算法采用页框(Page Frame)作为基本内存区,适合于大块内存请求。在很多情况下,进程或者系统申请的内存都是4K(一个标准页面)的,依然采用伙伴算法必然会造成系统内存的极大浪费。为满足进程或者系统对小片内存的请求,对内存管理粒度更小的SLAB分配器就产生了。(注:Linux中的SLAB算法实际上是借鉴了Sun公司的Solaris操作系统中的SLAB模式)
2、SLAB分配器简介
SLAB分配器实际上是建立在伙伴系统算法之上的,SLAB分配器使用的内存空间是通过伙伴算法进行分配的,只不过SLAB对这些内存空间实现了自己的算法进而对小块内存进行管理。
在讲解SLAB原理前,我们考虑下面场景:如果一个应用程序经常使用某一种类型的对象,或者说频繁的创建、回收某一种类型的对象,那我们是不是可以尝试将这类对象单独存放起来,当进程不在使用时,我们暂时先不回收,等应用程序再使用时,我们把之前应该回收的对象在拿出来,只不过重新构造一下对象,这样我们就减少了一次释放、申请内存的操作了。
注:下文说明的缓存指的并不是真正的缓存,真正的缓存指的是硬件缓存,也就是我们通常所说的L1 cache、L2 cache、L3 cache,硬件缓存是为了解决快速的CPU和速度较慢的内存之间速度不匹配的问题,CPU访问cache的速度要快于内存,如果将常用的数据放到硬件缓存中,使用时CPU直接访问cache而不用再访问内存,从而提升系统速度。下文中的缓存实际上是用软件在内存中预先开辟一块空间,使用时直接从这一块空间中去取,是SLAB分配器为了便于对小块内存的管理而建立的。
3、SLAB分配器原理
3.1 SLAB相关说明
(1)SLAB与伙伴(Buddy)算法
伙伴系统的相关介绍可以参加其他博客。在伙伴系统中,根据用户请求,伙伴系统算法会为用户分配2^order个页框,order的大小从0到11。在上文中,提到SLAB分配器是建立在伙伴系统之上的。简单来说,就是用户进程或者系统进程向SLAB申请了专门存放某一类对象的内存空间,但此时SLAB中没有足够的空间来专门存放此类对象,于是SLAB就像伙伴系统申请2的幂次方个连续的物理页框,SLAB的申请得到伙伴系统满足之后,SLAB就对这一块内存进行管理,用以存放多个上文中提到的某一类对象。
(2)SLAB与对象
对象实际上指的是某一种数据类型。一个SLAB只针对一种数据类型(对象)。为了提升对对象的访问效率,SLAB可能会对对象进行对齐。
(3)SLAB与per-CPU缓存
为了提升效率,SLAB分配器为每一个CPU都提供了每CPU数据结构struct array_cache,该结构指向被释放的对象。当CPU需要使用申请某一个对象的内存空间时,会先检查array_cache中是否有空闲的对象,如果有的话就直接使用。如果没有空闲对象,就像SLAB分配器进行申请。
3.2 SLAB相关数据结构
注意,本节说明的SLAB代码是基于Linux内核v4.7版本,代码网址。
SLAB分配器把对象分组放进高速缓存。每个高速缓存都是同种类型对象的一种“储备”。包含高速缓存的主内存区被划分为多个SLAB,每个SLAB由一个或多个连续的页框组成,这些页框中既包含已分配的对象,页包含空闲的对象。
在Linux内核中,SLAB高速缓存用struct kmem_cache表示,源代码网址,其定义如下:
/*SLAB分配器高速缓存*/
struct kmem_cache {
/*每CPU高速缓存指针,每一个CPU都会有一个该结构,其中存放了空闲对象*/
struct array_cache __percpu *cpu_cache;
/* 1) Cache tunables. Protected by slab_mutex */
/*要转移进本地高速缓存或者从本地高速缓存中转移出去的对象的数量*/
unsigned int batchcount;
/*本地高速缓存中空闲对象的最大数目*/
unsigned int limit;
/*是否存在CPU共享的高速缓存*/
unsigned int shared;
/*对象对齐之后所占字节,也就是对象本身大小+为对齐对象而填充的字节*/
unsigned int size;
/*size的倒数*/
struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */
/*描述高速缓存永久属性的一组标志*/
unsigned int flags; /* constant flags */
/*每一个SLAB中包含的对象的个数*/
unsigned int num; /* # of objs per slab */
/* 3) cache_grow/shrink */
/*一个单独SLAB中包含的连续页框数目的对数 order of pgs per slab (2^n) */
unsigned int gfporder;
/* 分配页框时传递给伙伴系统的一组标识*/
gfp_t allocflags;
/*SLAB使用的颜色的数量*/
size_t colour;
/*SLAB中基本对齐偏移,当新SLAB着色时,偏移量的值需要乘上这个基本对齐偏移量,理解就是1个偏移量等于多少个B大小的值*/
unsigned int colour_off;
/* 空闲对象链表放在外部时使用,其指向的SLAB高速缓存来存储空闲对象链表 */
struct kmem_cache *freelist_cache;
/* 空闲对象链表的大小 */
unsigned int freelist_size;
/* SLAB中存放的对象的构造函数*/
void (*ctor)(void *obj);
/* 4) cache creation/removal */
/*高速缓存的名称*/
const char *name;
/*高速缓存描述符的双向链表指针*/
struct list_head list;
int refcount;
/*SLAB中存放的对象的大小*/
int object_size;
int align;
/* 5) statistics */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
#ifdef CONFIG_DEBUG_SLAB_LEAK
atomic_t store_user_clean;
#endif
/*对象间的偏移*/
int obj_offset;
#endif /* CONFIG_DEBUG_SLAB */
#ifdef CONFIG_MEMCG
struct memcg_cache_params memcg_params;
#endif
#ifdef CONFIG_KASAN
struct kasan_cache kasan_info;
#endif
#ifdef CONFIG_SLAB_FREELIST_RANDOM
void *random_seq;
#endif
/*一个节点高速缓存的指针数组,数组中的每一个元素指向每一个NUMA节点的高速缓存*/
struct kmem_cache_node *node[MAX_NUMNODES];
};
在struct kmem_cache结构体中,struct array_cache __percpu *cpu_cache和struct kmem_cache_node *node[MAX_NUMNODES]这两个属性比较重要。array_cache针对的是每一个CPU的SLAB高速缓存,kmem_cache_node是针对每一个NUMA节点的SLAB高速缓存。其中,struct kmem_cache_node结构体定义如下:源代码网址
/*NUMA节点高速缓存*/
struct kmem_cache_node {
/*自旋锁*/
spinlock_t list_lock;
#ifdef CONFIG_SLAB
/*包含空闲对象和非空闲对象的SLAB描述符双向循环链表*/
struct list_head slabs_partial;
/*不包含空闲对象的SLAB描述符双向循环链表*/
struct list_head slabs_full;
/*只包含空闲对象的SLAB描述符的双向循环链表*/
struct list_head slabs_free;
unsigned long free_objects;
unsigned int free_limit;
/*下一个被分配的SLAB的颜色*/
unsigned int colour_next;
/*本NUMA节点内被多个CPU所共享的本地高速缓存指针*/
struct array_cache *shared;
struct alien_cache **alien; /* on other nodes */
/*两次缓存收缩时的间隔*/
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};在struct kmem_cache_node结构体中,有三个比较重要的属性:slabs_partial、slabs_full、slabs_free,其中slabs_partial指向只有部分对象被使用的slab的描述符的链表,slabs_full指向所有对象都被使用的slab的描述符的链表,slabs_free指向所有对象都没有被使用的slab的描述符的链表。
有关slab的描述符,其定义是在struct page中,相关代码如下:源代码网址
struct page {
/* First double word block */
/*页描述符相关字段,与页框有关的一组标志*/
unsigned long flags;
union {
/*页描述符相关字段*/
struct address_space *mapping;
/*与SLAB描述符有关,指向SLAB中第一个对象的地址*/
void *s_mem; /* slab first object */
atomic_t compound_mapcount; /* first tail page */
/* page_deferred_list().next -- second tail page */
};
/* Second double word */
struct {
union {
pgoff_t index; /* Our offset within mapping. */
/*与SLAB描述符相关,指向SLAB中空闲对象链表*/
void *freelist; /* sl[aou]b first free object */
/* page_deferred_list().prev -- second tail page */
};
union {
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
/* Used for cmpxchg_double in slub */
unsigned long counters;
#else
unsigned counters;
#endif
struct {
union {
atomic_t _mapcount;
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
int units; /* SLOB */
};
/*
* Usage count, *USE WRAPPER FUNCTION*
* when manual accounting. See page_ref.h
*/
atomic_t _refcount;
};
unsigned int active; /* SLAB */
};
};
/*
* Third double word block
*
* WARNING: bit 0 of the first word encode PageTail(). That means
* the rest users of the storage space MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union {
/*有多重用途,在SLAB中表示加入到kmem_cache中的SLAB描述符链表中*/
struct list_head lru;
struct dev_pagemap *pgmap;
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
#ifdef CONFIG_64BIT
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
#else
short int pages;
short int pobjects;
#endif
};
struct rcu_head rcu_head; /* Used by SLAB
* when destroying via RCU
*/
/* Tail pages of compound page */
struct {
unsigned long compound_head; /* If bit zero is set */
/* First tail page only */
#ifdef CONFIG_64BIT
unsigned int compound_dtor;
unsigned int compound_order;
#else
unsigned short int compound_dtor;
unsigned short int compound_order;
#endif
};
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && USE_SPLIT_PMD_PTLOCKS
struct {
unsigned long __pad;
pgtable_t pmd_huge_pte; /* protected by page->ptl */
};
#endif
};
/* Remainder is not double word aligned */
union {
unsigned long private;
#if USE_SPLIT_PTE_PTLOCKS
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
#endif
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
};
#ifdef CONFIG_MEMCG
struct mem_cgroup *mem_cgroup;
#endif
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_KMEMCHECK
/*
* kmemcheck wants to track the status of each byte in a page; this
* is a pointer to such a status block. NULL if not tracked.
*/
void *shadow;
#endif
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
}在struct page结构体中,与SLAB有关的比较重要的两个属性:s_mem和freelist,其中s_mem指向slab中的第一个对象的地址(或者已经被分配或者空闲)。freelist指向空闲对象链表。
在struct kmem_cache结构体中有一个属性cpu_cache,cpu_cache是一个指向数组的指针,每个数组项都对应系统中的一个CPU,每个数组项都包含了一个指向struct array_cache的指针,其定义如下:源代码网址
struct array_cache {
/*保存了per-CPU缓存中可使用对象的指针的个数*/
unsigned int avail;
/*保存的对象的最大的数量*/
unsigned int limit;
/*如果per-CPU列表中保存的最大对象的数目超过limit值,内核会将batchcount个对象返回到slab*/
unsigned int batchcount;
/*从per—CPU缓存中移除一个对象时,此值将被设置为1,缓存收缩时,此时被设置为0.这使得内核能够确认在缓存上一次
收缩之后是否被访问过,也是缓存重要性的一个标志*/
unsigned int touched;
/*一个伪指针数组,指向per-CPU缓存的对象*/
void *entry[];
};说了这么多,你可能不太清楚上面的这些结构体到底都什么关系。为了更好的理解上面这些结构体之间的关系,请看下面的这幅图:
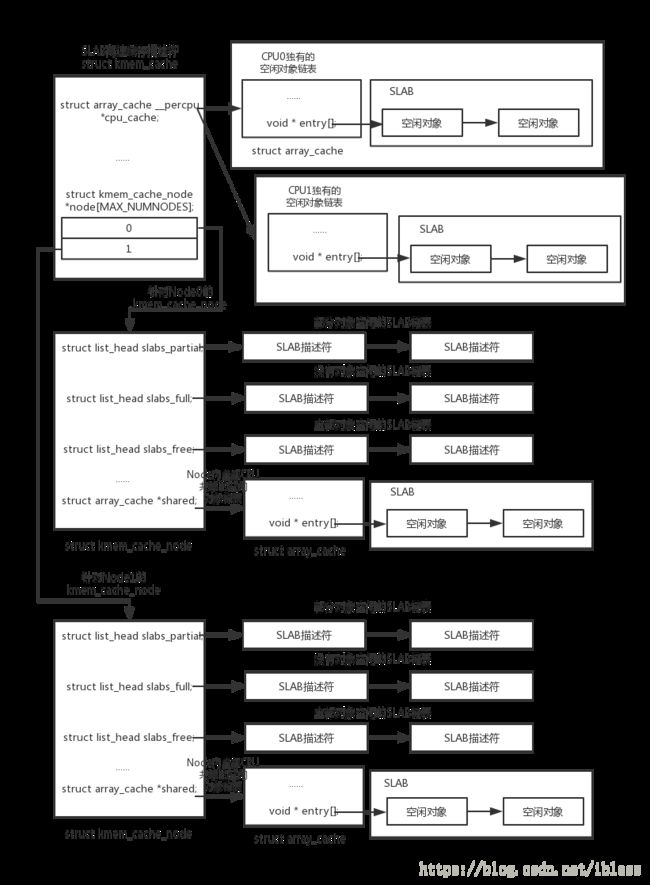
具体的流程可以参考博客:https://blog.csdn.net/lukuen/article/details/6935068,请读者一定要看一下这篇博客。
3.3 SLAB与分区页框分配器
先介绍一下分区页框分配器,分区页框分配器用于处理对连续页框组的内存分配请求。其中有一些函数和宏请求页框,一般情况下,它们都返回第一个所分配的页的线性地址,如果分配失败,则返回NULL。这些函数简介如下:
alloc_pages(gfp_mask,order):请求2^order个连续的页框,他返回第一个所分配页框的描述符的地址。分配失败则返回NULL。
__get_free_pages(gfp_mask,order):与函数alloc_pages(gfp_mask,orser)类似,但是此函数返回第一个所分配页的线性地址。
__free_pages(page,order):该函数先检查page指向的页描述符,如果该页框未被保留(PG_reserved标志位为
0),就把描述符的count字段值减1。如果count字段的值变为0,就假定从与page对应的页框开始的2^order个连续的页框不再被使用。在这种情况下该函数释放页框。
free_pages(addr,order):类似于__free_pages(),但是它接收的参数为要释放的第一个页框的线性地址addr。当SLAB分配器创建新的SLAB时,需要依靠分区页框分配器来获得一组连续的空闲页框。为了达到此目的,需要调用kmem_getpages()函数,函数定义如下:源代码网址
static struct page *kmem_getpages(struct kmem_cache *cachep, gfp_t flags,int nodeid)其中,参数cachep指向需要额外页框的高速缓存的高速缓存描述符(请求页框的个数存放在cache->gfporder字段中的order决定),flags说明如何请求页框,nodeid指明从哪个NUMA节点的内存中请求页框。与kmem_getpages()函数相对的是kmem_freepages(),kmem_freepages()函数可以释放分配给slab的页框。kmem_freepages()函数定义如下:源代码网址
static void kmem_freepages(struct kmem_cache *cachep, struct page *page)3.4 SLAB与高速缓存
创建新的slab缓存需要调用函数kmem_cache_create()。该函数定义如下:源代码网址
/*
* kmem_cache_create - Create a cache.
* @name: A string which is used in /proc/slabinfo to identify this cache.
* @size: The size of objects to be created in this cache.
* @align: The required alignment for the objects.
* @flags: SLAB flags
* @ctor: A constructor for the objects.
*
* Returns a ptr to the cache on success, NULL on failure.
* Cannot be called within a interrupt, but can be interrupted.
* The @ctor is run when new pages are allocated by the cache.
*
* The flags are
*
* %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)
* to catch references to uninitialised memory.
*
* %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check
* for buffer overruns.
*
* %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware
* cacheline. This can be beneficial if you're counting cycles as closely
* as davem.
*/
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void *));kmem_cache_create()函数在调用成功时返回一个指向所构造的高速缓存的指针,失败则返回NULL。
与kmem_cache_create()函数相对应的是销毁高速缓存的函数kmem_cache_destroy(),该函数定义如下:源代码网址
void kmem_cache_destroy(struct kmem_cache *s)
{
LIST_HEAD(release);
bool need_rcu_barrier = false;
int err;
if (unlikely(!s))
return;
get_online_cpus();
get_online_mems();
kasan_cache_destroy(s);
mutex_lock(&slab_mutex);
s->refcount--;
if (s->refcount)
goto out_unlock;
err = shutdown_memcg_caches(s, &release, &need_rcu_barrier);
if (!err)
err = shutdown_cache(s, &release, &need_rcu_barrier);
if (err) {
pr_err("kmem_cache_destroy %s: Slab cache still has objects\n",
s->name);
dump_stack();
}
out_unlock:
mutex_unlock(&slab_mutex);
put_online_mems();
put_online_cpus();
release_caches(&release, need_rcu_barrier);
}
EXPORT_SYMBOL(kmem_cache_destroy);需要注意的是:kmem_cache_destroy()函数销毁的高速缓存中应该只包含未使用对象,如果一个高速缓存中含有正在使用的对象时调用kmem_cache_destroy()函数将会失败,从kmem_cache_destroy()函数的源代码中我们很容易看出。
下面看一个有关这两个函数使用的示例:源代码网址
#define KSM_KMEM_CACHE(__struct, __flags) kmem_cache_create("ksm_"#__struct,\
sizeof(struct __struct), __alignof__(struct __struct),\
(__flags), NULL)
static int __init ksm_slab_init(void)
{
rmap_item_cache = KSM_KMEM_CACHE(rmap_item, 0);
if (!rmap_item_cache)
goto out;
stable_node_cache = KSM_KMEM_CACHE(stable_node, 0);
if (!stable_node_cache)
goto out_free1;
mm_slot_cache = KSM_KMEM_CACHE(mm_slot, 0);
if (!mm_slot_cache)
goto out_free2;
return 0;
out_free2:
kmem_cache_destroy(stable_node_cache);
out_free1:
kmem_cache_destroy(rmap_item_cache);
out:
return -ENOMEM;
}
static void __init ksm_slab_free(void)
{
kmem_cache_destroy(mm_slot_cache);
kmem_cache_destroy(stable_node_cache);
kmem_cache_destroy(rmap_item_cache);
mm_slot_cache = NULL;
}上面的代码很简单,就是建立和销毁rmap_item、mm_slot、stable_node三种数据类型的高速缓存。
3.5 SLAB与SLAB的对象
创建完成某一种数据类型或者某一种对象的高速缓存之后,我们可以从该对象的高速缓存中分配与释放对象。其中,kmem_cache_alloc()函数用于从特定的缓存中获取对象,该函数定义如下:源代码网址
/**
* kmem_cache_alloc - Allocate an object
* @cachep: The cache to allocate from.
* @flags: See kmalloc().
*
* Allocate an object from this cache. The flags are only relevant
* if the cache has no available objects.
*/
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *ret = slab_alloc(cachep, flags, _RET_IP_);
kasan_slab_alloc(cachep, ret, flags);
trace_kmem_cache_alloc(_RET_IP_, ret,
cachep->object_size, cachep->size, flags);
return ret;
}
EXPORT_SYMBOL(kmem_cache_alloc);从函数的名称、参数、返回值、注释中,我们很容易知道kmem_cache_alloc()函数从给定的slab高速缓存中获取一个指向空闲对象的指针。实际上,进行获取空闲对象的时候,会先从per-CPU缓存中也就是array_cache中查找空闲对象,如果没有则会从kmem_cache_node中获取空闲对象,如果也没有则需要利用伙伴算法分配新的连续页框,然后从新的页框中获取空闲对象。从kmem_cache_alloc()到大致的调用链如下:
kmem_cache_alloc()——>slab_alloc()——>__do_cache_alloc()——>____cache_alloc()——>cpu_cache_get()(这里实际上是从array_cache中获取空闲对象)——>cache_alloc_refill()(这里会在array_cache中没有空闲对象时执行)——>cpu_cache_get()(经过cache_alloc_refill()的执行基本保证array_cache中有空闲对象)——>返回可用空闲对象
对cache_alloc_refill()函数执行步骤分解如下:
cache_alloc_refill()——>尝试从被一个NUMA节点所有CPU共享的缓冲中获取空闲对象(源代码注释中写道:See if we can refill from the shared array),如果有则返回可用对象,refill结束——>从kmem_cache_node中的slab中获取空闲对象,有则返回,没有就执行下一步——>kmem_getpages()
而kmem_cache_free()函数用于从特定的缓存中释放对象,函数定义如下:源代码网址
/**
* kmem_cache_free - Deallocate an object
* @cachep: The cache the allocation was from.
* @objp: The previously allocated object.
*
* Free an object which was previously allocated from this
* cache.
*/
void kmem_cache_free(struct kmem_cache *cachep, void *objp)
{
unsigned long flags;
cachep = cache_from_obj(cachep, objp);
if (!cachep)
return;
local_irq_save(flags);
debug_check_no_locks_freed(objp, cachep->object_size);
if (!(cachep->flags & SLAB_DEBUG_OBJECTS))
debug_check_no_obj_freed(objp, cachep->object_size);
__cache_free(cachep, objp, _RET_IP_);
local_irq_restore(flags);
trace_kmem_cache_free(_RET_IP_, objp);
}
EXPORT_SYMBOL(kmem_cache_free);释放对象与分配对象的过程类似,不再赘述。
3.6 SLAB着色
同一硬件高速缓存行可以映射RAM中很多不同的内存块。相同大小的对象倾向于存放在硬件高速缓存内相同的偏移量处。在不同的SLAB内具有相同偏移量的度下行最终很有可能映射在同一硬件高速缓存行中。高速缓存的硬件可能因此而花费内存周期在同一高速缓存行与RAM内存单元之间来来往往传送这两个对象,而其他的硬件高速缓存行并未充分使用(以上语句出自《深入理解Linux内核》第三版第334页)。SLAB分配器为了降低硬件高速缓存的这种行为,采用了SLAB着色(slab coloring)的策略。所谓着色,简单来说就是给各个slab增加不同的偏移量,设置偏移量的过程就是着色的过程。通过着色尽量使得不同的对象对应到硬件不同的高速缓存行上,以最大限度的利用硬件高速缓存,提升系统效率。
3.7 普通与专用高速缓存
高速缓存(指的不是硬件高速缓存)被在SLAB中被分成两种类型:普通和专用。普通高速缓存只由SLAB分配器用于自己的目的,而专用高速缓存由内核的其余部分使用。专用的高速缓存是由kmem_cache_create()函数创建的,由kmem_cache_destroy()函数撤销,用于存放对象(或具体数据类型),普通高速缓存是系统初始化期间调用keme_cache_init()建立的。普通高速缓存中分配和释放空间使用kmalloc()和kfree()函数。下面是kmem_cache_init()函数的源代码:源代码网址
/*
* Initialisation. Called after the page allocator have been initialised and
* before smp_init().
*/
void __init kmem_cache_init(void)
{
int i;
BUILD_BUG_ON(sizeof(((struct page *)NULL)->lru) <
sizeof(struct rcu_head));
kmem_cache = &kmem_cache_boot;
if (!IS_ENABLED(CONFIG_NUMA) || num_possible_nodes() == 1)
use_alien_caches = 0;
for (i = 0; i < NUM_INIT_LISTS; i++)
kmem_cache_node_init(&init_kmem_cache_node[i]);
/*
* Fragmentation resistance on low memory - only use bigger
* page orders on machines with more than 32MB of memory if
* not overridden on the command line.
*/
if (!slab_max_order_set && totalram_pages > (32 << 20) >> PAGE_SHIFT)
slab_max_order = SLAB_MAX_ORDER_HI;
/* Bootstrap is tricky, because several objects are allocated
* from caches that do not exist yet:
* 1) initialize the kmem_cache cache: it contains the struct
* kmem_cache structures of all caches, except kmem_cache itself:
* kmem_cache is statically allocated.
* Initially an __init data area is used for the head array and the
* kmem_cache_node structures, it's replaced with a kmalloc allocated
* array at the end of the bootstrap.
* 2) Create the first kmalloc cache.
* The struct kmem_cache for the new cache is allocated normally.
* An __init data area is used for the head array.
* 3) Create the remaining kmalloc caches, with minimally sized
* head arrays.
* 4) Replace the __init data head arrays for kmem_cache and the first
* kmalloc cache with kmalloc allocated arrays.
* 5) Replace the __init data for kmem_cache_node for kmem_cache and
* the other cache's with kmalloc allocated memory.
* 6) Resize the head arrays of the kmalloc caches to their final sizes.
*/
/* 1) create the kmem_cache */
/*
* struct kmem_cache size depends on nr_node_ids & nr_cpu_ids
*/
create_boot_cache(kmem_cache, "kmem_cache",
offsetof(struct kmem_cache, node) +
nr_node_ids * sizeof(struct kmem_cache_node *),
SLAB_HWCACHE_ALIGN);
list_add(&kmem_cache->list, &slab_caches);
slab_state = PARTIAL;
/*
* Initialize the caches that provide memory for the kmem_cache_node
* structures first. Without this, further allocations will bug.
*/
kmalloc_caches[INDEX_NODE] = create_kmalloc_cache("kmalloc-node",
kmalloc_size(INDEX_NODE), ARCH_KMALLOC_FLAGS);
slab_state = PARTIAL_NODE;
setup_kmalloc_cache_index_table();
slab_early_init = 0;
/* 5) Replace the bootstrap kmem_cache_node */
{
int nid;
for_each_online_node(nid) {
init_list(kmem_cache, &init_kmem_cache_node[CACHE_CACHE + nid], nid);
init_list(kmalloc_caches[INDEX_NODE],
&init_kmem_cache_node[SIZE_NODE + nid], nid);
}
}
create_kmalloc_caches(ARCH_KMALLOC_FLAGS);
}上面的代码结合下面的图,获取会更容易理解一些:
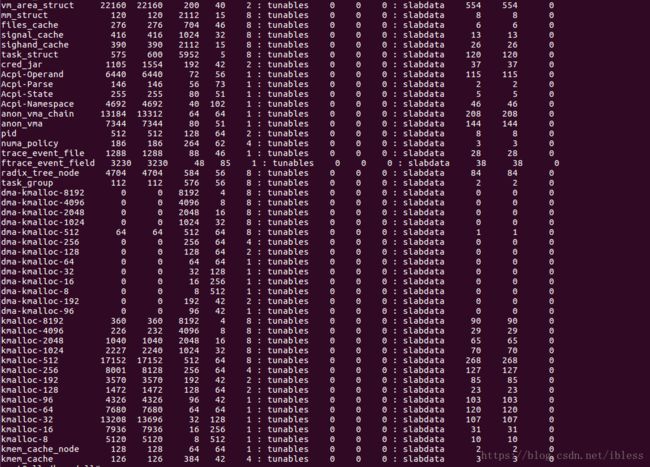
在Linux中使用 sudo cat /proc/slabinfo就可以得到上面的信息,每一列的含义如下:
![]()
下面我们重点介绍kmalloc()函数,其源代码如下:源代码网址
/**
* kmalloc - allocate memory
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate.
*
* kmalloc is the normal method of allocating memory
* for objects smaller than page size in the kernel.
*
* The @flags argument may be one of:
*
* %GFP_USER - Allocate memory on behalf of user. May sleep.
*
* %GFP_KERNEL - Allocate normal kernel ram. May sleep.
*
* %GFP_ATOMIC - Allocation will not sleep. May use emergency pools.
* For example, use this inside interrupt handlers.
*
* %GFP_HIGHUSER - Allocate pages from high memory.
*
* %GFP_NOIO - Do not do any I/O at all while trying to get memory.
*
* %GFP_NOFS - Do not make any fs calls while trying to get memory.
*
* %GFP_NOWAIT - Allocation will not sleep.
*
* %__GFP_THISNODE - Allocate node-local memory only.
*
* %GFP_DMA - Allocation suitable for DMA.
* Should only be used for kmalloc() caches. Otherwise, use a
* slab created with SLAB_DMA.
*
* Also it is possible to set different flags by OR'ing
* in one or more of the following additional @flags:
*
* %__GFP_COLD - Request cache-cold pages instead of
* trying to return cache-warm pages.
*
* %__GFP_HIGH - This allocation has high priority and may use emergency pools.
*
* %__GFP_NOFAIL - Indicate that this allocation is in no way allowed to fail
* (think twice before using).
*
* %__GFP_NORETRY - If memory is not immediately available,
* then give up at once.
*
* %__GFP_NOWARN - If allocation fails, don't issue any warnings.
*
* %__GFP_REPEAT - If allocation fails initially, try once more before failing.
*
* There are other flags available as well, but these are not intended
* for general use, and so are not documented here. For a full list of
* potential flags, always refer to linux/gfp.h.
*/
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
#ifndef CONFIG_SLOB
if (!(flags & GFP_DMA)) {
int index = kmalloc_index(size);
if (!index)
return ZERO_SIZE_PTR;
return kmem_cache_alloc_trace(kmalloc_caches[index],
flags, size);
}
#endif
}
return __kmalloc(size, flags);
}函数参数中的size表示请求分配的字节数,需要注意的是kmalloc()函数分配的是连续的物理内存。
与kmalloc()函数相对的是kfree()函数,其定义如下:源代码网址
/**
* kfree - free previously allocated memory
* @objp: pointer returned by kmalloc.
*
* If @objp is NULL, no operation is performed.
*
* Don't free memory not originally allocated by kmalloc()
* or you will run into trouble.
*/
void kfree(const void *objp)
{
struct kmem_cache *c;
unsigned long flags;
trace_kfree(_RET_IP_, objp);
if (unlikely(ZERO_OR_NULL_PTR(objp)))
return;
local_irq_save(flags);
kfree_debugcheck(objp);
c = virt_to_cache(objp);
debug_check_no_locks_freed(objp, c->object_size);
debug_check_no_obj_freed(objp, c->object_size);
__cache_free(c, (void *)objp, _RET_IP_);
local_irq_restore(flags);
}
EXPORT_SYMBOL(kfree);kfree()函数用于释放由kmalloc()函数分配的连续内存空间。kmalloc()分配的是内核内存,但是其分配的大小是有限制的。
3.8 SLAB分配器体现的改进思想:
(1)SLAB分配器把内存区看成对象
(2)SLAB分配器吧对象分组放进高速缓存
(3)每个SLAB都是同种类型的内存对象
如上文内容有不当之处,请批评指针,谢谢!