Linux协议栈报文收发流程记录
来自:http://blog.chinaunix.net/uid-22397896-id-3348984.html
RX流程
1.非NAPI的RX
driver的isr调用eth_type_trans //确定skb->pkt_type和skb->protocol
driver的isr调用netif_rx //可查看返回值,NET_RX_DROP表示丢包,
__skb_queue_tail(&queue->input_pkt_queue, skb); //input_pkt_queue最大值为netdev_max_backlog=1000
napi_schedule(&queue->backlog); //添加backlog到poll_list,触发NET_RX_SOFTIRQ
net_rx_action //收多少包受到netdev_budget、device的weight和时间限制
process_backlog
netif_receive_skb
NAPI的RX
driver的isr关闭NIC中断
driver的isr调用__netif_rx_schedule(&nic->napi); //添加device自己的napi到poll_list,触发NET_RX_SOFTIRQ
net_rx_action //收多少包受到netdev_budget、device的weight和时间的限制
driver的poll //上传全部skb之后开启NIC中断,driver通常自己维护队列,
//或者直接从ring buffer中取出
eth_type_trans //确定skb->pkt_type和skb->protocol
netif_receive_skb
备忘:
NAPI的优势在于:
中断少, softirq被触发的次数少,CPU占用率低;
关中断,先前收到报文的处理不容易被打断,buffer不容易被溢出,所以吞吐率高;
NAPI和硬件的“收多个包产生一个中断”的区别:
NAPI的队列由driver维护,通常就是RX的ring buffer,当这个buffer满了,如果链路支持流控,NIC就会发送PAUSE帧,从而避免丢包;
如果使用netif_rx,假设硬件可以做到多包一个中断,还是有可能会使得 input_pkt_queue满,从而丢包,这个丢包和NIC发送PAUSE帧的时刻并不一定一致
查看统计信息:cat /proc/net/softnet_stat
2.
netif_receive_skb
deliver_skb //deliver给第三层的protocol
//若有多个packet_type来接收,会共享skb(增加users)
atomic_inc(&skb->users)
pt_prev(packet_type)->func //struct packet_type
//ptype_all是用AF_PACKET注册的socket?
3.
packet_type->func == ip_rcv
NF_HOOK(NF_INET_PRE_ROUTING)
ip_rcv_finish
ip_route_input //查找路由,确定dst->input/dst->output,struct dst_entry。
//先查找路由cache(struct rtable)
//查找键值是src/dst ip、interface等算出的hash值
ip_route_input_slow //若cache中没有,查找FIB(struct fib_table等),查找键值是struct flowi,并创建cache
dst_input
备忘:
struct rtable包含struct dst_entry、struct flowi、struct in_device等
路由命令:
route -n
route -C -n //查看路由cache
route add default gw 192.168.99.254
route add -net 192.168.98.0 netmask 255.255.255.0 gw 192.168.99.1
route add -host 192.168.98.42 gw 192.168.99.1
ip route show
FIB表分local和main两个表,前者用于本地分配的ip地址,后者存放到外部节点的路由,由route等命令操作
当需要复杂规则选择路由时(不仅仅依靠ip地址来选择),可启用基于policy路由,基于policy路由会建立多个FIB表
比如:ip rule add tos 0x04 table 252
如果是基于policy的路由,会先匹配规则,查找路由表,然后再查找路由
查看路由规则:ip rule show
Cache路由表查找算法是hash查找,FIB的是LPM (Longest Prefix Match)等
cat /proc/sys/net/ipv4/ip_forward
4.
dst->input == ip_local_deliver(or ip_forward) //本地ip_local_deliver,转发是ip_forward,ip_forward会减少TTL
ip_defrag //struct ipq,在成功完全重组完整个ip之后才继续,否则返回;超时会清除;
ip_find //找到对应未完成重组的队列,未找到则创建,struct inet_frag_queue
ip4_frag_match //根据src/dst ip、id等计算hash值来match
ip_frag_queue //将分片挂到队列上,struct inet_frag_queue的fragments是单向链表
ip_frag_reasm //把ipq上的分片挂在一个skb的frag_list里面
NF_HOOK(NF_IP_LOCAL_IN)
ip_local_deliver_finish
5.
ip_local_deliver_finish //递交给第四层
(raw_local_deliver/__raw_v4_lookup/raw_rcv_skb) //raw socket处理
ipprot->handler //struct net_protocol
6.
ipprot->handler == udp_rcv (or tcp_v4_rcv, icmp_rcv)
udp_v4_lookup //根据ip地址、端口来查找对应的socket,一个skb通常属于某个socket
udp_queue_rcv_skb(sk, skb)
sock_queue_rcv_skb(sk, skb) //接收缓冲区不够会丢包,sk->sk_rmem_alloc skb->truesize >= sk->sk_rcvbuf
//sk->sk_rcvbuf是接收缓冲区的大小,可以通过netstat -s来查看
skb_set_owner_r(skb, sk) //skb属于某个sk、增加sk->sk_rmem_alloc,skb->destructor=sock_rfree,
//应用程序进程取走数据后会释放接收缓冲区空间
skb_queue_tail(&sk->sk_receive_queue, skb)
sk->sk_data_ready == sock_def_readable //唤醒阻塞的 应用程序 进程
wake_up_interruptible_sync(sk->sk_sleep)
7. //从下往上看,因为是应用程序调用
sk->sk_prot->recvmsg == udp_recvmsg //struct proto
skb_recv_datagram //从sk->sk_receive_queue读取
wait_for_packet //如果没有包,挂在sk->sk_sleep队列
skb_copy_datagram_iovec //struct msghdr, copy skb_shinfo(skb)->frags[i]/frag_list to msg->msg_iov
sock->ops->recvmsg == sock_common_recvmsg //ops is struct proto_ops
__sock_recvmsg
sock_recvmsg
sys_recvfrom
sys_recv
sys_socketcall
recvfrom
+++++++++++++++++++++++++++++++++++++++++++++++++
TX流程
1.
sys_send
sockfd_lookup_light
sock_sendmsg
sock->ops->sendmsg == inet_sendmsg //struct proto_ops
sk->sk_prot->sendmsg //struct proto
2.
sk->sk_prot->sendmsg == udp_sendmsg
ip_route_output_flow
ip_append_data //根据MTU分割,创建多个skb,挂在sk_write_queue上
sock_alloc_send_skb //分配skb空间
sock_wait_for_wmem //sk->sk_wmem_alloc与sk->sk_sndbuf比较,不够会挂起
//UDP也会因发送缓冲区不够而刮起?
skb_set_owner_w //设置skb的sk、增加sk->sk_wmem_alloc、skb->destructor=sock_wfree
//sock_wfree在__kfree_skb的时候得以执行,它减少sk->sk_wmem_alloc
//并且它调用sk->sk_write_space=sock_def_write_space唤醒等待的进程
getfrag == ip_generic_getfrag //拷贝数据到skb
3.
udp_flush_pending_frames
udp_push_pending_frames //填充第四层报头\计算校验和
ip_push_pending_frames //sk->sk_write_queue队列被flush,里面的skb除了第一个都会追加到第一个skb的frag_list上
ip_select_ident //计算ip头的ID,struct inet_peer
NF_HOOK(NF_INET_LOCAL_OUT)
4.
dst_output
dst->output == ip_output(or ip_mc_output)
NF_HOOK(NF_INET_POST_ROUTING)
ip_finish_output
备忘:
ip_queue_xmit--->ip_route_output_flow--->ip_local_out--->dst_output for TCP
5.
ip_fragment(skb, ip_finish_output2) //判断fast或者slow分片,fast分片表示上层已经做过准备,分片都在frag_list上,
//直接为frag_list上的分片添加IP头,并调用output(即ip_finish_output2)
//slow分片根据MTU来分配,有复制和创建skb的操作
ip_finish_output2
备忘:
讲述分片:
http://simohayha.iteye.com/blog/433178
http://www.cnblogs.com/jinrize/archive/2009/11/28/1612567.html
6.
neigh_hh_output(有hh)/dst->neighbour->output //struct neighbour,struct neigh_table
dev_queue_xmit
q->enqueue=pfifo_fast_enqueue //struct Qdisc,pfifo队列满会丢包
//dev->tx_queue_len=1000,ether_setup中赋值
//丢包的错误会返回到上层处理
qdisc_run //qdisc选择适合的skb来发送
qdisc_restart
q->dequeue=pfifo_fast_dequeue
dev_hard_start_xmit
dev->netdev_ops->ndo_start_xmit
备忘:
tc命令用于控制qdisc,用于替换掉默认的pfifo_fast_enqueue/dequeue
对于NIC不能发送的情况(tx buffer满),qdisc会调用dev_requeue_skb,再调用__netif_schedule触发net_tx_action,由软中断发送,长期发送不成功会造成pfifo队列满
dev_queue_xmit是第一次发送skb,net_tx_action发送qdisc队列里的skb和清理completion_queue
arp命令:
arp -na
ip neighbor show
+++++++++++++++++++++++++++++++++++++++++++++++++
收发包大蓝图:

+++++++++++++++++++++++++++++++++++++++++++++++++
协议栈初始化
1.
start_kernel
rest_init
kernel_thread(init)
init
do_basic_setup
do_initcalls
2.
sock_init //core_initcall阶段
sk_init
skb_init //初始化两个skb slab cache: skbuff_head_cache、skbuff_fclone_cache
//slab预先分配好数据类型,由一个或多个page组成
register_filesystem(&sock_fs_type);
kern_mount(&sock_fs_type); //注册和挂在socket文件系统
备忘:
查看slab的使用情况:cat /proc/slabinfo
查看文件系统:cat /proc/filesystem
3.
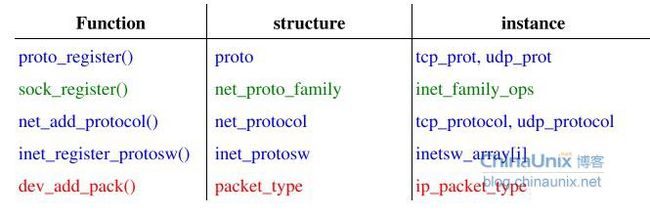
inet_init //fs_initcall阶段
proto_register(&tcp_prot, 1);
proto_register(&udp_prot, 1);
proto_register(&raw_prot, 1); //协议相关的socket
//struct udp_sock包含struct inet_sock,后者又包含struct sock
sock_register(&inet_family_ops); //注册INET socket地址族
inet_add_protocol(&icmp_protocol, IPPROTO_ICMP)
inet_add_protocol(&udp_protocol, IPPROTO_UDP)
inet_add_protocol(&tcp_protocol, IPPROTO_TCP)
inet_register_protosw
arp_init
ip_init
tcp_v4_init
tcp_init
udp_init
icmp_init
net_dev_init //subsys_initcall阶段
NIC device初始化
+++++++++++++++++++++++++++++++++++++++++++++++++
一些数据结构
常用的地址族:
#define AF_UNSPEC 0
#define AF_UNIX 1 //Unix domain sockets
#define AF_INET 2 //Internet IP Protocol
#define AF_INET6 10 //IP version 6
#define AF_SECURITY 14 //Security callback pseudo AF
#define AF_KEY 15 //PF_KEY key management API
#define AF_NETLINK 16
#define AF_ROUTE AF_NETLINK
#define AF_PACKET 17 //Packet family
PF_XXX和AF_XXX是一样的
struct socket --BSD套接字层的操作对象,支持各种socket地址族;
--int socket(int protocol_family, int socket_type, int protocol_id);
struct sock --用于网络协议栈;
struct net_proto_family --通用结构,支持各种socket地址族,实例为inet_family_ops;
struct inet_protosw --描述INET socket地址族,根据socket()中的type和protocol分类,inetsw_array[]定义了三个实例,有面向stream的TCP、面向dgram的UDP和RAW,struct inet_protosw中含有struct proto_ops和struct proto;
struct net_protocol --第三层到第四层,实例有tcp_protocol、udp_protocol,实例的方法有tcp_v4_rcv,udp_rcv,icmp_rcv,都放在一个inet_protos的数组中;
struct proto_ops --socket层到INET层(之前叫inet_protocol?),描述stream、dgram、raw的ops,实例有inet_stream_ops、inet_dgram_ops、inet_sockraw_ops等,sock->ops->sendmsg;
struct proto --INET层到传输层,描述具体协议的ops,实例有udp_prot、tcp_prot、raw_prot等,sk->prot->sendmsg;
struct packet_type --第二层到第三层,实例有ip_packet_type;

struct net_device,struct in_device
struct rtable,struct dst_entry
struct neighbour,struct hh_cache
struct ifreq //ifconfig 调用的 ioctl 码依次是 SIOCSIFADDR,SIOCSIFFLAGS,SIOCSIFNETMASK
在BSD Socket层使用struct msghdr来存储数据包,使用struct socket来字处理控制socket。
在INET Socket以下层中使用struct sk_buff 来存储数据包,使用struct sock来处理控制socket。
在driver和协议栈(比如IP层)之间有一层generic dev层(/net/core/dev.c)
struct softnet_data{
struct Qdisc *output_queue; //通过__netif_reschedule将不能发送的device的qdisc入队,
//通过net_tx_action出队
struct sk_buff_head input_pkt_queue; //所有非NAPI device的接收队列,通过netif_rx将skb入队,
//通过process_backlog出队
struct list_head poll_list; //struct napi_struct链表,通过__napi_schedule入队,通过net_rx_action出队
struct sk_buff *completion_queue; //待释放skb队列,通过dev_kfree_skb_irq入队,通过net_tx_action出队
struct napi_struct backlog; //所有非NAPI device借此以符合NAPI的调用方法,由netif_rx操作
};
struct sk_buff
skb->csum: 对tx来说,是第四层头中checksum的位置;对rx来说,是checksum的值
skb->len: 是所有的数据,线性段+frag_list(分片链表)+frags(page)
skb->data_len: skb的frag_list(分片链表)+frags(page)
skb->users: 引用参考,每次skb被共享增加1,每次skb被free减少1,为0时被释放
data, head, tail, end:
初始化时data, head, tail指向线性数据段开始,end指向线性数据段结束,skb_shared_info在end后一个字节开始,len为0;
实际kmalloc的区域是指定的size加上sizeof(struct skb_shared_info),size还有可能被align;
head和end自分配好之后就不再变化
skb_shinfo(skb)->dataref:
对skb的数据的引用计数
skb_clone会增加这个值,它拷贝sk_buff头,但共享数据
skb_shinfo(skb)->frag_list:
ip的分片和重组用,ip_frag_reasm和ip_push_pending_frames会用到,链接了有多个skb
skb_shinfo(skb)->frags:
支持SG,用page存放数据,只有一个skb
skb_shinfo(skb)->nr_frags:
page的个数
一些使用场合:
skb_reserve(): tx时,预留包头
skb_put(): rx时,driver收到包时调用;tx时,copy_from_user时调用
skb_push(): tx时,构建包头
skb_poll(): rx时,去掉包头
skb_trim(): rx时,去掉包尾的padding,当心有page区域,使用pskb_trim()
skb_headlen(): skb->len - skb->data_len,即kmalloc分配的数据区域大小
skb_is_nonlinear(): skb->data_len非0即非线性
struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask, int fclone, int node)
skb->data由kmalloc分配
skb从skbuff_head_cache或skbuff_fclone_cache中分配
如果有fclone标志,从skbuff_fclone_cache分配,一次分配2*sizeof(struct sk_buff)+sizeof(atomic_t)的大小
主skb->fclone=SKB_FCLONE_ORIG,从child->fclone = SKB_FCLONE_UNAVAILABLE
atomic_t的变量是fclone_ref,它是主从skb共同的引用计数
之所以需要skbuff_fclone_cache这种分配策略是因为传输层往往需要保留skb的一份拷贝,同时传递另一份skb给下层
struct sk_buff *skb_clone(struct sk_buff *skb, gfp_t gfp_mask)
会判断skb是否来自skbuff_fclone_cache,若是的话,判断其次skb的fclone是否为SKB_FCLONE_UNAVAILABLE
SKB_FCLONE_UNAVAILABLE表示没有使用;SKB_FCLONE_CLONE表示已经被使用;
若skb不是来自skbuff_fclone_cache,则在skbuff_head_cache上新建一个skb用于克隆
当一个skb被clone之后,数据区不能被修改的,通过pskb_copy复制线性数据段,skb_copy复制所有数据段,包括frags[i]
而skb_copy是在skbuff_head_cache上进行分配的
struct sk_buff_head {
struct sk_buff *next; //与sk_buff的第1、2个成员一样
struct sk_buff *prev; //与sk_buff的第1、2个成员一样
__u32 qlen; //队列大小
spinlock_t lock; //操作队列时,必须先获得lock
};
skb的队列操作函数略
+++++++++++++++++++++++++++++++++++++++++++++++++
应用程序、系统调用、协议栈

iputils工具包含有ping, arping等 命令
nettools工具包含有ifconfig, netstat, route, arp等 命令
IPROUTE2含有ip命令
netfilter用于包的Filtering, Changing packets (masquerading), Connection Tracking等,通过iptable配置
etable相当于二层的netfilter
xfrm与IPSEC有关
+++++++++++++++++++++++++++++++++++++++++++++++++
参考
Understanding Linux Network Internals
http://basiccoder.com/intro-linux-kernel-hash-rt-1.html
http://www.cnblogs.com/jinrize/archive/2009/11/29/1612872.html
http://blog.chinaunix.net/uid-127037-id-2919560.html
http://simohayha.iteye.com/
The journey of a packet through the linux 2.4/6 network stack
netinit.pdf
Linux TCP IP 协议栈分析.pdf