算法及数据结构知识点总结(持续更新)
目录
数据结构基础概念
链表
数组
栈
队列
哈希表
堆
二叉查找树
树
图
排序
冒泡排序
选择排序
插入排序
堆排序
归并排序
快速排序(重点)
查找
线性查找
二分查找
图的搜索
广度优先搜索
深度优先搜索
Bellman-Ford
Dijkstra
机器学习
监督非监督
k-means
apriori算法(关联分析)
支持向量机
Logistic回归和SVM的异同
原理及算法红黑树
-
数据结构基础概念
链表
线性,添加删除较容易,不容易查找
数组
线性,访问简单,添加删除较复杂
栈
先入后出。对应Java中的Stack。方法有 push,pop,isEmpty,peek等
队列
先入先出。对应java中queue。双向链表Deque。push,addfirst,addlast,peekfirst,pop等
哈希表
先存储在线性表中,然后根据i Mod x =n求得插入的位置,如果存在则像链表一样插入到这一位置的后边。
堆
一种图的树形结构被用于优先队列中。子节点必须大于父节点,新数据插入到最下一行靠左位置
二叉查找树
二叉排序树,二叉搜索树。每个节点大于左子树上所有节点,小于右子树所有节点。
树
完全二叉树,满二叉树
https://www.cnblogs.com/skywang12345/p/3576328.html
图
普通图表示个体之间的相互关系。还有加权图,有向图,无向图,图可以解决最短路径问题
-
排序
冒泡排序
没啥好说的
for(int i=0;i选择排序
线性查找,O(n^2),选一个最小的,插到最前边,再从头到尾遍历,选择一个最小的,插到前边,循环比较慢,不再多说。
插入排序
依次选择,while(比前边的数小) 交换
堆排序
先降序排列,也可以升序,依次取出根节点,由于使用到堆这个复杂的结构,所以不方便实现
归并排序
先分解成小块,小块之间排序,然后再整体排序
快速排序(重点)
平均运行时间为 O(nlogn)。
Arrays.sort()用的是快速排序算法,做算法题可以直接使用。例如
12,20,5,16,15,1,30,45,23,9定义头指针i 尾指针j,记录一个点为key=12,从后向前找个比它小的9,覆盖i,从前向后找个比它大的20,j再向前找到1覆盖i,i向后找到16覆盖j,j向前,当i>=j时第一轮结束,然后继续
开始12,20,5,16,15,1,30,45,23,9
接下来的顺序为
i-> <- j
0 1 2 3 4 5 6 7 8 9
9 20 5 16 15 1 30 45 23 9
9 20 5 16 15 1 30 45 23 20
9 1 5 16 15 1 30 45 23 20
9 1 5 16 15 16 30 45 23 20
9 1 5 16 15 16 30 45 23 20
9 1 5 16 15 16 30 45 23 20
5 1 5 12 15 16 30 45 23 20
5 1 5 12 15 16 30 45 23 20
1 1 9 12 15 16 30 45 23 20
1 1 9 12 15 16 30 45 23 20
1 5 9 12 15 16 30 45 23 20
1 5 9 12 15 16 30 45 23 20
1 5 9 12 15 16 30 45 23 20
1 5 9 12 15 16 30 45 23 20
1 5 9 12 15 16 20 45 23 20
1 5 9 12 15 16 20 45 23 45
1 5 9 12 15 16 20 23 23 45
1 5 9 12 15 16 20 23 23 45
1 5 9 12 15 16 20 23 30 45
1 5 9 12 15 16 20 23 30 45
这样就很直观的理解了
import com.sun.xml.internal.bind.v2.model.core.NonElement;
import java.util.*;
public class Main {
private static void quickSort(int[] arr, int begin, int end) {
if (begin < end){
int p = partition1(arr, begin, end);
// int p = partition2(arr, begin, end);
quickSort(arr, begin, p - 1);
quickSort(arr, p + 1, end);
}
}
private static int partition1(int[] arr, int begin, int end) {
int key=arr[begin];
int i=begin;
int j=end;
while (i=key) j--;
if(i list = new ArrayList<>();
for(int i=0;i it = list.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
} -
查找
线性查找
一个一个找,按顺序O(n)
二分查找
经典查找O(log),运行对数时间,主要注意mid = (low+high)/2,low=mid+1;high=mid-1这三句
private static int BinarySearch(int[] a, int i) {
int low = 0;
int high = a.length;
while(low<=high){
int mid = (low+high)/2;
if(a[mid] == i) return mid;
else if(a[mid] < i) low = mid+1;
else high = mid -1;
}
return -1;
}-
图的搜索
广度优先搜索
,而我们的目的是从起点开始顺着边搜索,直到到达指定顶点(即终 点)。在此过程中每走到一个顶点,就会判断一次它是否为终点。广度优先搜索会优先从离起点 近的顶点开始搜索。若一次有多个候补点,则按照FIFO的原则依次搜索。
深度优先搜索
目的也都是从起点开始搜 索直到到达指定顶点(终点)。深度优先搜索会沿着一条路径不断往下搜索直到不能再继续为 止,然后再折返,开始搜索下一条候补路径。
Bellman-Ford
Dijkstra
-
机器学习
监督非监督
监督就是人为给定目标,按目标方向进行训练,非监督就是不知道分成什么类别,让系统自己去识别
k-means
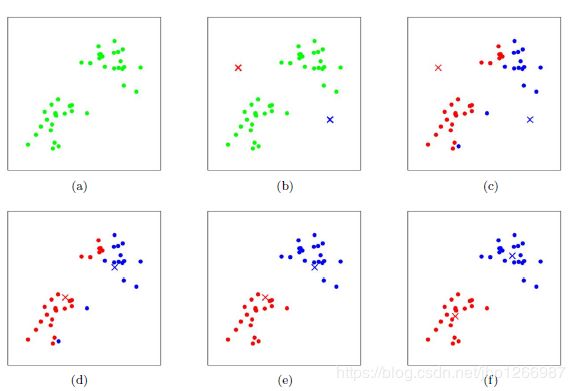
先随机选择代表K个簇的种子点,分别计算其他数据点到K个中心点的距离,距离那个近,那个就分配到该簇下,重新计算每个簇数据的左边均值,将新的均值作为新的聚类中心,然后重复。图片大概意思就是分成两类,找两个点,计算距离,然后找每类中重心,然后再计算距离,分类,找重心,再分类。。。
apriori算法(关联分析)
关联分析,例如某个商品和某个商品之间是否有关联。先生成单个物品的项集列表,剔除不符合最低要求的项,对剩下的集合组合,生成类似(a,b)的集合,再次剔除不符合最低要求的项,重复直到去除所有不符合项
支持向量机
按监督学习对数据二分类,可以想一下下面的图,基本就能记起来了


Logistic回归和SVM的异同
相同:分类算法,线性分类,监督学习
不同:loss function不同,推荐看吴恩达的机器学习,网易云课堂有中文字幕免费版
SVM损失函数自带正则项,结构风险最小
解决非线性时,SVM使用核函数(支持向量机通过某非线性变换 φ( x) ,将输入空间映射到高维特征空间)
SVM对异常值不敏感,泛化好,小数据好
逻辑回归简单,大量数据较好
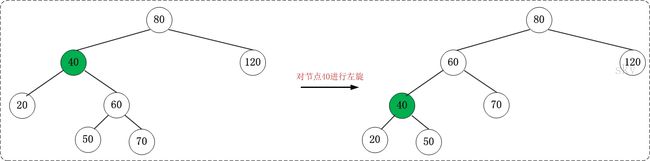
原理及算法红黑树
特殊的二叉查找树(左小右大),节点红黑色,根黑,红下必黑,叶子节点(度为0)为黑接近平衡二叉树,O(lgN),效率高,java的treemap。c++ map使用