启发式搜索1
回想起来我像第一次接触启发式搜索还是在本科大三的课程设计,但是当时还完全没有分类的概念。一直想总结一下启发式搜索的内容,现在能有时间做一些总结感觉真爽快。
————————————————————————————————————————————————————————————————————————
启发式搜索(Informed Search / Heuristic Search)
一般的搜索策略都可以归纳成以下的算法过程
- 初始化队列Q
- 重复以下过程
- 取队列Q头的值,并测试其是否是我们的目标值,如果是结束搜索
- 拓展Q,例如产生候选节点并将其加入队列Q
因为在实际编程过程中,虽然实际模型常常是图Graph结构的,但是通常会使用队列Queue来保存搜索信息
不同的搜索算法根据添加新节点的顺序不同而区分,就是拓展步骤候选节点的选择顺序策略
从这种角度考虑时,深度优先搜索(DFS)和广度优先搜索(BFS)其实在处理新节点的方法上是一样的
区别仅仅在:
- 深度优先搜索,在队列的头加入新的候选节点
- 广度优先搜索,在队列的尾加入新的候选节点
最佳优先搜索 Best First Search 使用评价函数 f(x) 来对上述的节点选择顺序进行排序
下面先定义两个函数
- g(x) 为从根节点到x节点的代价总和
- h(x) 为从x节点到目标节点的估计代价总和
这类应用算法有
代价一致搜索 (Uniform Cost Search) f(x) = g(x)
贪心搜索 (Greedy Search) f(x) = h(x)
A星搜索 (A* Search) f(x) = g(x) + h(x)
关于模型的图
上面所讲的 g(x) h(x) 还是太过抽象,所以这里用一张经典的图进行说明,这是一张地图的抽象,假定目标节点为Bucharest
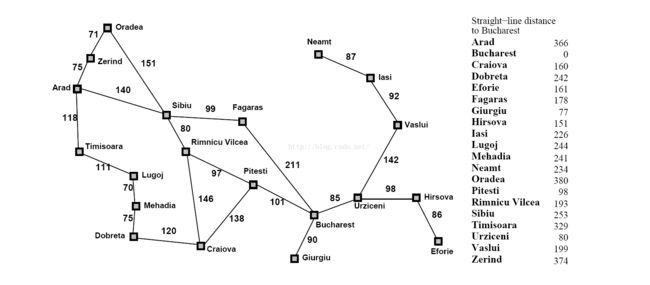
在上图中,h(x)指的是右边的各个节点(城市)到目标节点(Bucharest)的直线测量距离
可以想象,这个距离在实际中不可能等同于路程,除非你在驾驶一辆理想化的私人进行交通而且还无视航空法规。
但是,这个距离在大多情况下是能反映出一部分的实际距离的,因为无论怎样绕远路,直线距离100km和直线距离1km的两个地点在实际到达距离或时间(代价)上都是有区分度的。
这里又回到了数学建模问题,一个好的建模可以大大优化算法的执行质量。
贪心搜索是完全使用 h(x) 作为参考的,该算法会一直选择距离目标最近的点进行拓展。
由于每一步的拓展都是基于当前与节点相连接的节点进行选择的,所以贪心算法可能会出现环路状况,例如图中的 Iasi 和 Neamt 就会不断循环访问
而且贪心搜索无法保证结果的最优解,原因是我们用的数据是预测数据(直线距离)而不是真实数据,其具有一定概率上的相关性但不具备实际相关性。
代价一致搜索
用优先队列实现,关键点在于该算法不关心经过节点量,只关心该路径已走过路程和(代价和)。而且此算法就算到达目标点也不会停止,而是继续寻找是否有更佳路径,直至遍历完成
procedure UniformCostSearch(Graph, start, goal) node ← start cost ← 0 frontier ← priority queue containing node only explored ← empty set prev[] ← empty set do if frontier is empty return failure node ← frontier.pop() if node is goal return solution explored.add(node) for each of node's neighbors n if n is not in explored if n is not in frontier frontier.add(n) prev[n] = node else if n is in frontier with higher cost replace existing node with n prev[n] = node这里还有一个算法在我看来是和代价一致搜索是一样原理的,就是Dijkstra's algorithm。
这两个算法的区别在于UCS不需要像Dijkstra's那样一次吧所有节点的信息全部读入(初始化时所有节点的cost设置成无限大),而是在某节点有更新时才对其进行cost值初始化并加入优先队列。(黄色字部分为区别)
因为算法的限制,ucs不会出现环路情况,因为explored参数的存在
explored 和 prev可以设置为每个节点的状态 ,也可以设成独立结构
A* Search
吸收了以上两个算法的优点
贪心的效率和ucs的精准
为什么A* Search能保证有最优解呢?
这是由于 h() 只要满足可允许(adimssible)条件:任何的h(x)都小于或等于h*(x)
h*(x) 是从节点x到目标的实际路径
那么从算法的角度看预测值的权永远小于或等于同等的实际距离的权
就是说预测对算法的影响不会大于实际值
Iterative Deepening A*
相对A*算法该算法使用了深度优先的搜索策略,并且在递归开始就设定了阈值,在算法搜索到一定深度后自动停止深度搜索
该算法无需进行访问判断和排序,相对占内存空间较小
node current node g the cost to reach current node f estimated cost of the cheapest path (root..node..goal) h(node) estimated cost of the cheapest path (node..goal) cost(node, succ) step cost function is_goal(node) goal test successors(node) node expanding function procedure ida_star(root) bound := h(root) loop t := search(root, 0, bound) if t = FOUND then return bound if t = ∞ then return NOT_FOUND bound := t end loop end procedure function search(node, g, bound) f := g + h(node) if f > bound then return f if is_goal(node) then return FOUND min := ∞ for succ in successors(node) do //DFS t := search(succ, g + cost(node, succ), bound) if t = FOUND then return FOUND if t < min then min := t end for return min end function