语义分割中优化特征融合方法-Exfuse
作者:晟沚
前 言
目前语义分割网络框架通常会结合预训练backbone卷积的low-level和high-level特征来提高模型性能,但是low-level和high-leve特征的简单融合可能不太有效,主要是由于语义水平和空间分辨率方面的差距。 下面主要介绍Exfuse这篇文章的主要思路,论文地址:https://arxiv.org/abs/1804.03821。
01
简述
作者发现在低级特征(low-level feature)引入语义信息,在高级特征(high-level feature)嵌入空间信息对于特征融合更有效。基于此观察,作者提出了一个新框架,名为Exfuse,以减少low-level和high-level特征之间的gap。其性能超越 DeepLabv3,在 PASCAL VOC 2012 分割任务中也有比较好的效果。
低级特征空间信息丰富,但是缺乏语义信息;高级特征语义信息丰富但是缺乏一些精确的细节信息比如边缘等。作者又分析了“纯”低级特征,它编码低级概念比如点、线或者边缘。高级特征虽然需要底层的一些细节,但是与这些“纯”低级特征的融合意义不大,因为噪音太多,无法提供高分辨率的语义信息引导。相反,如果低级特征包含更多的语义信息,比如,编码相对明确的语义框,接着再去融合效果就会好很多。相似地,“纯”高级特征的空间信息也很少,不能充分利用低级特征;但是,通过嵌入额外的高分辨率特征,高级特征从而有机会通过对齐最近的低级语义框来实现自我优化,整个过程如下图所示
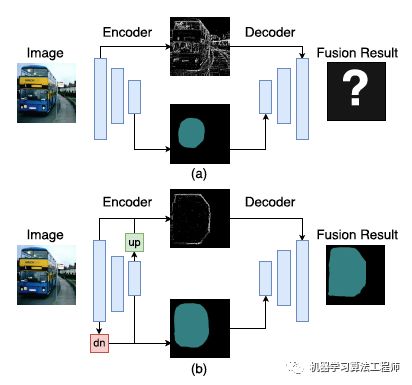
总的来说,特征融合可通过把更多的语义信息引入低级特征,或者在高级特征中嵌入更多的空间信息而实现提升。出于上述发现,作者提出一种新框架 ExFuse,通过弥补低级与高级特征图之间的语义与分辨率的差距来完善特征融合过程,其策略主要包含以下两个方面:
在低级特征中引入更多语义信息,作者给出 3个方案:卷积重排列(Layer Rearrangement/LR),多层语义监督(Semantic Supervision/SS) 和高级语义嵌入(Semantic Embedding Branch/SEB
在高级特征嵌入更多空间信息,为此作者给出 2个全新方法:显式通道内嵌空间信息(Explicit Channel Resolution Embedding/ECRE)和密集邻域预测(Densely Adjacent Prediction/DAP)。
上面每一方法都带来了显著的性能提升,组合使用涨点高达 4%。在 PASCAL VOC 2012 语义分割test数据集上mean IoU 达到 87.9%。
02
具体方法介绍
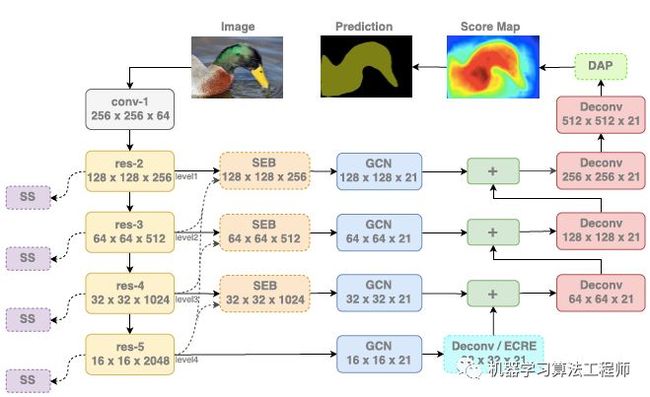
作者选用全局卷积网络(Global Convolutional Network/GCN)作为backbone,网络结构如下图所示。实线框属于 GCN 组件,虚线框属于 ExFuse 组件。其中每个组件含义如下:
SS – semantic supervision
ECRE – explicit channel resolution embedding
SEB – semantic embedding branch
DAP – densely adjacent prediction
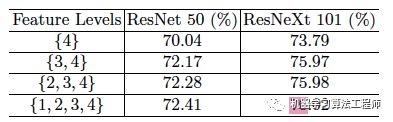
作者对四个level特征融合的有效性进行评估, 特征大小分别是{128, 64, 32, 16}(512x512输入大小),PASCAL VOC 2012 validation集结果如下表所示。从表中可以看到分割质量并没有随着不同层级特征的融合而提升,反而是快速达到饱和,这意味着高、低特征的融合在 GCN 中并不奏效,而作者提出的ExFuse 可以补足这一短板。
下面具体介绍这篇文章提出的主要方法:
Layer rearrangement
在ResNeXt网络结构中,各级的网络包含的残差单元个数为{3,4,23,3}。为了提高底层特征的语义性,让低层的两级网络拥有的层数更多,作者将残差单元个数重排为{8,8,9,8},并重新在ImageNet上预训练模型,尽管新设计模型的 ImageNet 分类分值几乎没有变化,其分割性能却涨点 0.8%。
卷积重排列(LR)
为使低级特征(res-2 或者res-3)“更接近于”监督,一个直接的办法是在早期而不是后期阶段(stage)安排更多的层。
多层语义监督(SS)
在其他的一些工作里(如GoogLeNet,边缘检测的HED等)已经使用到了。它主要专注于完善低级特征的质量,而不是提升 backbone 模型本身,能够带来大约1个点的提升,具体如下图所示。

高级语义嵌入(SEB)
很多 U-Net 架构会把低级特征作为上采样的高级特征的残差,在低级特征包含很少的语义信息的情况下,就会导致不足以复原语义分辨率。为克服这一问题,作者通过seb结构如下图所示,其中“×” 表示逐元素乘法,SEB被用于 level 1-3 的特征,在实验中 SEB 带来了 0.7% 的涨点。

高级特征嵌入更多空间信息
高级特征主要是语义信息偏多,但是包含较少的空间信息,作者尝试将更多的空间特征融入到通道(channel)中去,包括:
1. 通道分辨率嵌入(explicit channel resolution embedding);
2. 稠密邻域预测(densely adjacent prediction)。
显式通道内嵌空间信息(ECRE)
作者采用一种无需调参的上采样方法——Sub-pixel Upsample,如下图——以替代原先的解卷积。作者的出发点并不是前人工作中强调的如速度快、消除反卷积的棋盘效应等等,而是通过这个结构能够让和空间信息相关的监督信息回传到各个通道中,从而让不同通道包含不同空间信息。该模块和原有的反卷积一起使用才能显示出更好的性能。同单独使用反卷积相比,性能可以提高约0.6个点。

密集邻域预测(DAP)
如下图,DAP模块只使用在输出预测结果的时候。其想法也是通过扩展通道数来尽可能多地把空间信息编码进通道。假设DAP的作用区域为3x3,输出结果的通道数为21,则扩展后的输出通道数为21x3x3。每3x3个通道融合成一个通道。如在最终结果中,第5通道(共21通道)的(12,13)坐标上的像素,是通过DAP之前的第5+0通道(11,12)、5+1通道的(11,13)、5+2通道的(11,14)、5+3通道的(12,12)、5+4通道的(12,13)、5+5通道的(12,14)…平均得到的。DAP能带来约0.6个点的提升。

03
实验结果
在 PASCAL VOC 2012 test集合上的 mIoU 值达到 87.9%,优于相同条件下的 DeepLabv3,如下表所示。

作者提出的此方法和baseline对比如下图,可以看到细节方面有较大提升。


END
往期回顾之作者石文华
【1】目标检测新技能!引入知识图谱:Reasoning-RCNN
【2】 MaskConnect: 探究网络结构搜索中的Module间更好的连接
【3】 tensorboard 指南
【4】 network sliming:加快模型速度同时不损失精度
机器学习算法工程师
一个用心的公众号

长按,识别,加关注
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助