Python 爬虫 新浪2019年五大联赛所有球员基本数据爬取与分析
纪念自己第一个有稍微用心的小学期项目,使用Python编程语言编写一个网络爬虫项目,对新浪足球球员数据库(http://match.sports.sina.com.cn)的数据爬取,获取2019年五大联赛所有球员的基本数据存储到csv中,进行统计分析,爬取信息字段要求:['中文名称','英文名称','英文全称','生日','身高','体重','年龄','位置','国籍','俱乐部','球衣号码']。
首先对网站网页进行分析,发现各个联赛都有相对于的链接页面,且发现规律英超的为(http://match.sports.sina.com.cn/football/opta_rank.php?year=2019&lid=1),西甲的lid为2,德甲为3,意甲为4,法甲为5,点进去球队后,右边有一列当前阵容的表格,点击头像便可以链接到球员的详细数据页面,所以初步计划先爬取各个联赛各支球队链接,然后再通过球队链接来爬取球员链接。

编写getteam.py
#encoding:UTF-8
import requests
from bs4 import BeautifulSoup
def get_teamlink(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'}
res = requests.get(url,headers = headers) #get方法中加入请求头
res.encoding = 'utf-8'#设置编码格式防止乱码
soup = BeautifulSoup(res.text, 'lxml') #对返回的结果进行解析
team=soup.select('a[href^="team.php?id"]')
team_list={}
for x in range(len(team)):
team_list[str(team[x].string)]=str('http://match.sports.sina.com.cn/football/'+team[x].attrs['href'])
return (team_list)
England = get_teamlink('http://match.sports.sina.com.cn/football/opta_rank.php?year=2019&lid=1')#英超联赛的球队链接获取
Spain=get_teamlink('http://match.sports.sina.com.cn/football/opta_rank.php?year=2019&lid=2')#西甲联赛的球队链接获取
Germany=get_teamlink('http://match.sports.sina.com.cn/football/opta_rank.php?year=2019&lid=3')#德甲联赛的球队链接获取
Italy=get_teamlink('http://match.sports.sina.com.cn/football/opta_rank.php?year=2019&lid=4')#意甲联赛的球队链接获取
French=get_teamlink('http://match.sports.sina.com.cn/football/opta_rank.php?year=2019&lid=5')#法甲联赛的球队链接获取
with open('teamlinks.csv', 'w') as f:#把数据放到csv文件中
[f.write('{0},{1}\n'.format(key, value)) for key, value in England.items()]
[f.write('{0},{1}\n'.format(key, value)) for key, value in Spain.items()]
[f.write('{0},{1}\n'.format(key, value)) for key, value in Germany.items()]
[f.write('{0},{1}\n'.format(key, value)) for key, value in Italy.items()]
[f.write('{0},{1}\n'.format(key, value)) for key, value in French.items()]
得到球队链接teamlinks.csv文件
编写player.py
#encoding:UTF-8
import csv
import requests
from bs4 import BeautifulSoup
with open('teamlinks.csv','r') as f:#取球队链接
reader = csv.reader(f)
column1 = [row[1]for row in reader]
player={}#建存储球员链接的字典
for x in column1:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'}
url=x
res = requests.get(url,headers = headers) #get方法中加入请求头
res.encoding = 'gbk'
soup = BeautifulSoup(res.text, 'lxml') #对返回的结果进行解析
player_name=soup.find(class_='sub03_c').find_all('p')#找球员姓名
for i in range(len(player_name)):
player_name[i]=str(player_name[i].get_text())
player_links=soup.find(class_='sub03_c').find_all('a')#找球员链接
for j in range(len(player_links)):
player_links[j]=str(player_links[j].attrs['href'])#取href属性
for k in range(len(player_name)):
player[str(player_name[k])]=str(player_links[k])
with open('playerlinks.csv', 'w') as f:#写入球员链接
[f.write('{0},{1}\n'.format(key, value)) for key, value in player.items()]
得到球员链接

编写state.py
#encoding:UTF-8
import csv
import os
import pandas as pd
import requests
from bs4 import BeautifulSoup
def get_state(player):#取球员详细数据的方法
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'}
res = requests.get(player,headers = headers) #get方法中加入请求头
res.encoding = 'gbk'
soup = BeautifulSoup(res.text, 'lxml') #对返回的结果进行解析
state=list(soup.find(class_='txt').find_all('dd'))
for x in range(len(state)):
state[x]=str(state[x])[4:-5]
return state
with open('playerlinks.csv','r') as f:#打开球员链接文件
reader = csv.reader(f)
column1 = [row[1]for row in reader]
player=list()#新建存储球员数据的列表
for x in column1:
player.append(get_state(x))
p_columns=['中文名称','英文名称','英文全称','生日','身高','体重','年龄','位置','国籍','俱乐部','球衣号码']
raw_list = pd.DataFrame(columns=p_columns,data=player)#把嵌套列表转化为DataFrame对象
raw_list.to_csv('player.csv', encoding='gbk')#存储为csv文件得到球员信息

编写country.py分析五大联赛球员国家比例分析
#coding:utf-8
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
from matplotlib import font_manager
#设置图表样式
plt.style.use('fivethirtyeight')
#这里使用pandas读取csv文件
data = pd.read_csv('player.csv',encoding='gbk')
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
countrys = data['国籍']
#定义一个Counter
#用来国家分类的总数
country_counter = Counter()
for country in countrys:
country_counter.update(country.split(' '))
countries = []
popularity = []
#取前15个
for item in country_counter.most_common(15):
countries.append(item[0])
popularity.append(item[1])
#倒序显示
countries.reverse()
popularity.reverse()
#设置图表的字体微软雅黑 防止中文乱码的
zh_font = font_manager.FontProperties(fname='C:\\Windows\\Fonts\\simhei.ttf')
#使用横向条形图表
plt.yticks(fontsize = 8)
plt.barh(countries,popularity)
plt.title("五大联赛球员国籍比例",fontproperties=zh_font)
plt.xlabel("人数",fontproperties=zh_font)
plt.tight_layout()
plt.show()
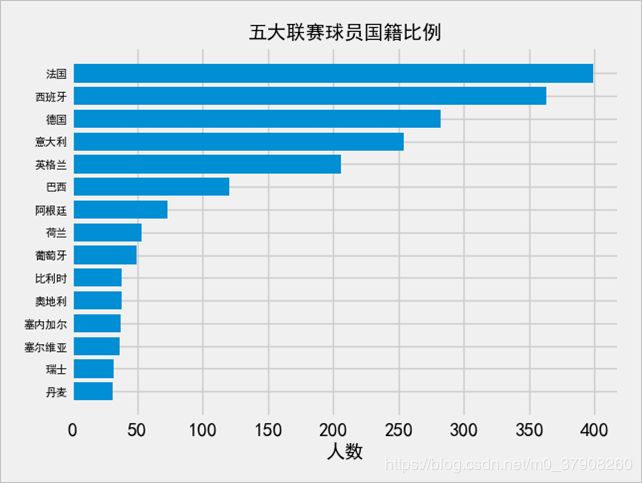
从数据中可以看出法国球员最多,这不禁让人感觉到法国国家队夺得2018的世界杯冠军也是有一定道理,人员储备的充足给国家队主帅提供了更多的可行性。同时也可以看出国家联赛的发展也是对本国球员发展有一定的促进作用,排在前五的恰好就是五大联赛本国。瑞士丹麦在2016欧洲杯的表现也是得益于在五大联赛球员中的比例越来越大。
编写old.py分析年龄
#coding:utf-8
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
from matplotlib import font_manager
#设置图表样式
plt.style.use('fivethirtyeight')
#这里使用pandas读取csv文件
data = pd.read_csv('player.csv',encoding='gbk')
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
olds = data['年龄']
#定义一个Counter
#用来年龄分类的总数
old_counter = Counter()
for old in olds:
old_counter.update(old.split(' '))
oldes = []
popularity = []
#取前15个
for item in old_counter.most_common(15):
oldes.append(item[0])
popularity.append(item[1])
#倒序显示
oldes.reverse()
popularity.reverse()
#设置图表的字体微软雅黑 防止中文乱码的
zh_font = font_manager.FontProperties(fname='C:\\Windows\\Fonts\\simhei.ttf')
#使用横向条形图表
plt.barh(oldes,popularity)
plt.title("五大联赛球员年龄比例",fontproperties=zh_font)
plt.xlabel("人数",fontproperties=zh_font)
plt.tight_layout()
plt.show()
 得到五大联赛球员年龄分析
得到五大联赛球员年龄分析
从中可以看出现在的五大联赛球员年龄偏年轻化,当打之年的球员占据较大比例,更多的年轻小将涌现世界足坛,留给穆巴佩,登贝莱等超新星的时间不多了,另外五大联赛中年龄最高的是来自尤文图斯的门神布冯以及蒙彼利埃的后卫希尔顿,他们的年龄都为41岁,不禁让人赞叹他们的职业素养,唯有超高的职业素养以及对足球的热爱才能够让他们依旧活跃在世界主流联赛中。
编写hight.py
#coding:utf-8
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
from matplotlib import font_manager
#设置图表样式
plt.style.use('fivethirtyeight')
#这里使用pandas读取csv文件
data = pd.read_csv('player.csv',encoding='gbk')
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
heights = data['身高']
#定义一个Counter
#用来身高分类的总数
height_counter = Counter()
for country in heights:
height_counter.update(country.split(' '))
heightes = []
popularity = []
#取前15个
for item in height_counter.most_common(15):
heightes.append(item[0])
popularity.append(item[1])
#倒序显示
heightes.reverse()
popularity.reverse()
#设置图表的字体微软雅黑 防止中文乱码的
zh_font = font_manager.FontProperties(fname='C:\\Windows\\Fonts\\simhei.ttf')
#使用横向条形图表
plt.yticks(fontsize = 8)
plt.barh(heightes,popularity)
plt.title("五大联赛球员身高比例",fontproperties=zh_font)
plt.xlabel("人数",fontproperties=zh_font)
plt.tight_layout()
plt.show()
wight.py#coding:utf-8
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
from matplotlib import font_manager
#设置图表样式
plt.style.use('fivethirtyeight')
#这里使用pandas读取csv文件
data = pd.read_csv('player.csv',encoding='gbk')
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
weights = data['体重']
#定义一个Counter
#用来体重分类的总数
weight_counter = Counter()
for weight in weights:
weight_counter.update(weight.split(' '))
weightes = []
popularity = []
#取前15个
for item in weight_counter.most_common(15):
weightes.append(item[0])
popularity.append(item[1])
#倒序显示
weightes.reverse()
popularity.reverse()
#设置图表的字体微软雅黑 防止中文乱码的
zh_font = font_manager.FontProperties(fname='C:\\Windows\\Fonts\\simhei.ttf')
#使用横向条形图表
plt.yticks(fontsize = 8)
plt.barh(weightes,popularity)
plt.title("五大联赛球员体重比例",fontproperties=zh_font)
plt.xlabel("人数",fontproperties=zh_font)
plt.tight_layout()
plt.show()
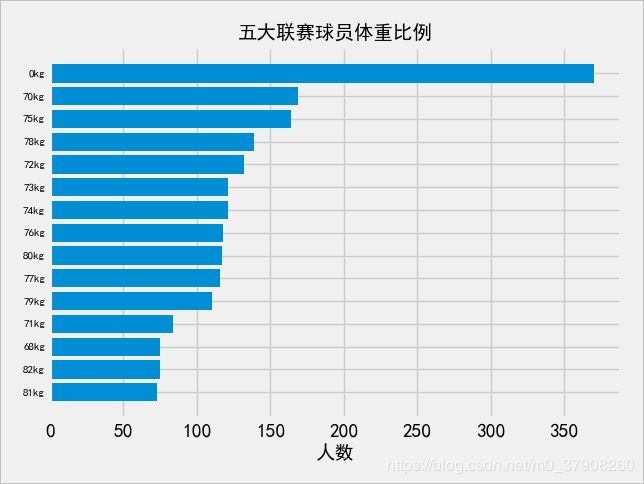

可得五大联赛球员的体重身高和比例
可以看到有0cm和0kg的占据大比例,这其实不是爬取数据中出错了,而是新浪数据库的数据不全导致。普遍身高为180cm,体重为70kg。其中身高最高的是来自斯帕尔俱乐部的蒂亚姆,他的身高为202cm,最矮的是来自布雷斯特的巴托齐奥,他的身高为160cm,体重最大的是来自莱斯特城俱乐部的摩根,他的体重为101kg,体重最小的是来自那不勒斯俱乐部的莫滕斯和来自摩纳哥俱乐部的索菲亚内-迪奥普,他们的体重都为55kg。
源码和文件已上传到csdn资源中,可以修改部分代码获取别的数据,仅用于学术研究请勿他用