内容主数据 TiDB 集群写入热点优化实践
本文首发于微信公众号之家技术
1. 背景
内容主数据项目数据存储层使用了分布式关系型数据库 TiDB (编写本文时,内容主数据 TiDB 集群的版本号是 3.0.9),本文从一次业务优化解决写入热点的案例入手,为大家简单介绍 TiDB 架构,内容主数据 TiDB 集群基本情况,遇到的问题及如何解决的,最后介绍数据库开发规范的重要性。
内容主数据是之家统一中台体系中非常重要且核心的系统之一,是之家内容生态的支撑系统,实现了汽车之家全平台内容的一致化,即所有内容展示数据的一致、所有内容状态及对外显示的统一、所有内容源头的统一。后续项目规划是接入所有之家内容类系统所产生的数据,为内容类数据制定统一标准,并为所有业务前台系统提供中心化的一致性出口。
2. TiDB 介绍
TiDB 是一款开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP (Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。TiDB 整体架构如下:
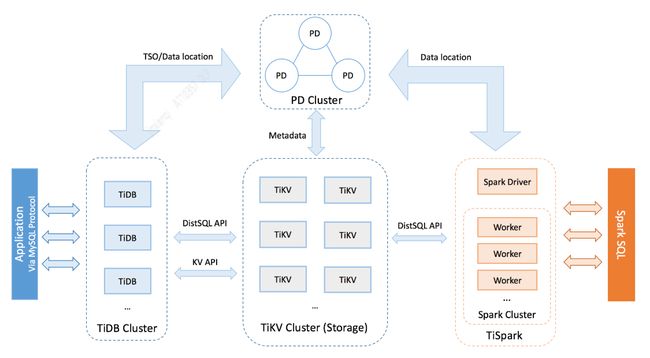
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:
- 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);
- 二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);
- 三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证自身数据的安全性。Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点。
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
3. 集群信息
本章节为大家介绍下内容主数据 TiDB 集群的基本架构。
3.1 基本信息
目前内容主数据 TiDB 集群使用的版本是 3.0.9 版本,各个组件如下表所示:
| 模块名称 | 版本信息 | 数量 |
|---|---|---|
| tidb | v3.0.9 | 5 |
| pd | v3.0.9 | 3 |
| tikv | v3.0.9 | 12(单机多实例) |
| pump | v3.0.9 | 4 |
| drainer | v3.0.9 | 3 |
TiDB、PD、TiKV 在第2章节已做介绍,不再赘述,这里简单说一下 Pump 和 Drainer 组件。Pump 用于实时记录 TiDB 产生的 Binlog,并将 Binlog 按照事务的提交时间进行排序,再提供给 Drainer 进行消费,Drainer 从各个 Pump 中收集 Binlog 进行归并,再将 Binlog 同步到下游 Kafka。
3.2 集群拓扑
下面是集群的基本架构图
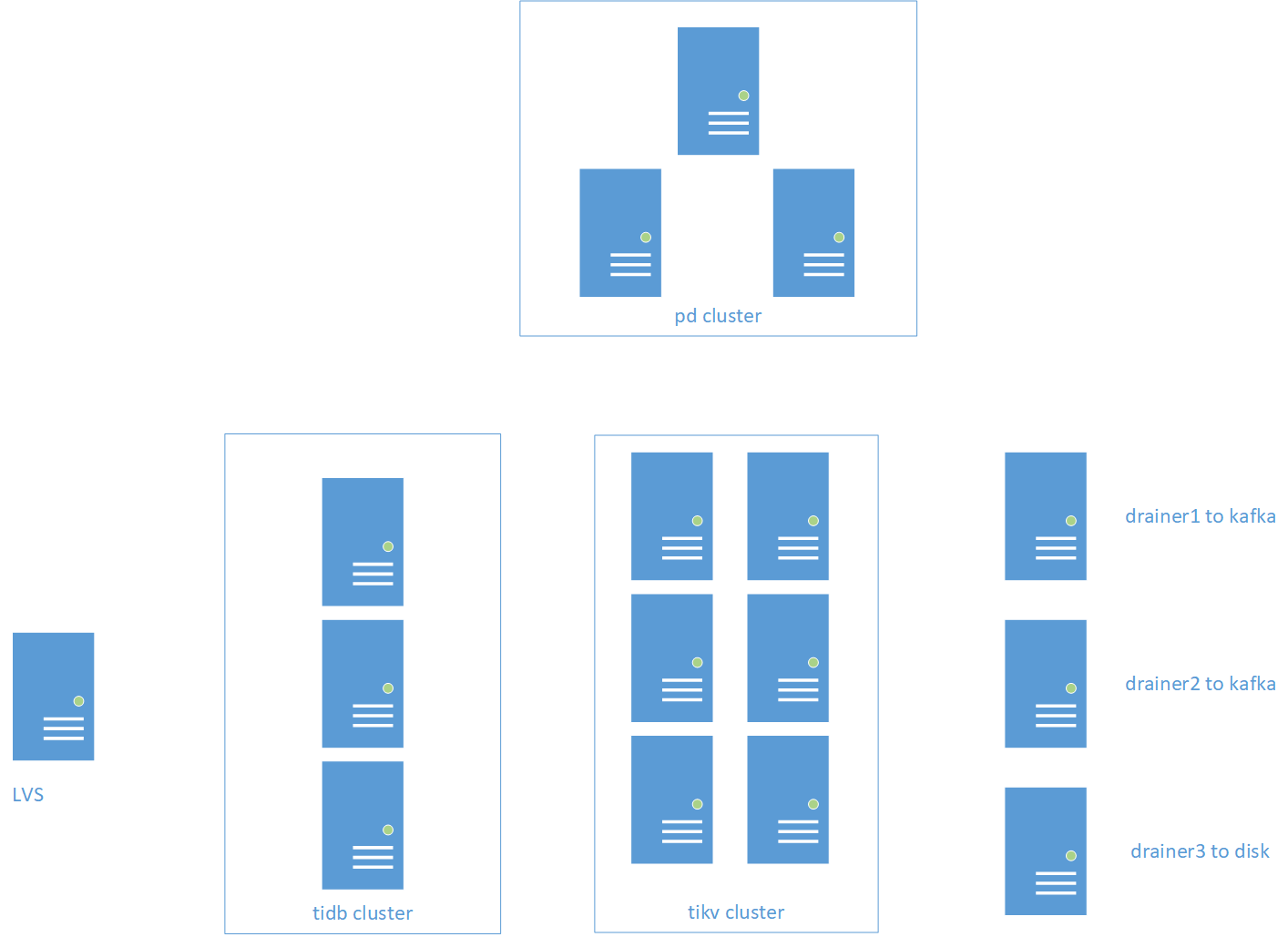
【 集群说明 】
业务数据写入 TiDB 同步库通过两种方式
(1)SQL SERVER 通过 CDC 同步到集群
(2)MySQL 通过 Otter 同步到集群
LVS 后端有多个 TiDB 节点用于业务访问,2 个 Drainer 实时同步 TiDB 业务数据到下游 Kafka 集群用于获取 TiDB 增量数据,然后汇总成业务数据写入 TiDB 汇总库,1个 Drainer 同步 TiDB 数据到服务器磁盘,用于分析问题,比如某个时间段 TPS 特别高,可以利用 reparo 工具解析指定时间段内的 Binlog 来分析问题。
4. 问题描述
数据写入流程是:Drainer 将 TiDB Binlog 同步到 Kafka,程序消费 Kafka 数据写入 TiDB 汇总库。
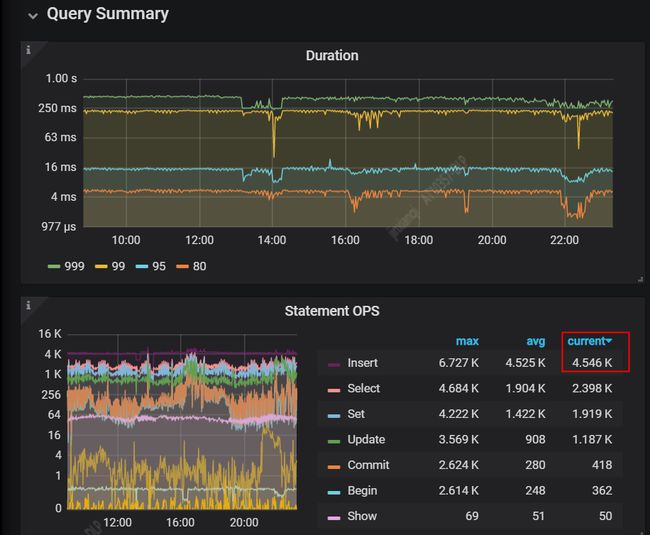
业务方反馈写入 TiDB 汇总库很慢,Kafka 消息有大量堆积。我们从下面 TiDB 监控图也能很明显的看出集群响应很慢: SQL 99 的响应时间在 200ms 到 220ms 之间,但是 insert 每秒只有 4500 左右。我们带着这些问题开始逐步分析。
(1)Duration 表示 SQL 响应时间,包括 SQL 999/99/95/80
(2)Statement QPS 表示每秒增删改查的量
5. 问题分析
5.1 分析慢日志
首先我们看下集群慢是否是由于慢 SQL 导致的呢?我们使用 pt-query-digest 工具对慢日志进行分析,排名第一的慢 SQL 如下,都是一些简单的 insert,平均耗时 8ms,为什么这么简单的 insert 耗时这么长?
Insert IGNORE Into table_name (ciz_id,data_type,field,`value`) values(37163712,'club','club_is_jinghua','0' ) \G
5.2 查看监控
我们继续分析,查看监控指标是否有异常,通过观察监控系统 Hot Write 面板,我们发现以下几点异常
(1)gRPC poll CPU 指标中某个 TiKV gRPC poll CPU 的值明显高于其它 TiKV 节点
(2)QPS 指标中某个 TiKV 的 QPS 明显高于其它 TiKV 节点
(3)CPU 指标中某个 TiKV 节点的 CPU 使用率明显高于其他 TiKV 节点
基于以上分析,我们可以得出结论:集群存在写热点,导致了集群写入慢。
众所周知,在分布式数据库中,除了本身的基础性能外,最重要的就是充分利用所有节点能力,避免让单个节点成为瓶颈。严重的热点问题,会导致单个节点成为资源瓶颈,进而影响整个系统的吞吐能力。
下面是部分监控指标截图
【 gRPC poll CPU 】: gRPC 线程的 CPU 使用率
从监控曲线可以看到,某个 TiKV 的 gRPC poll CPU 明显高于其它 TiKV 节点。

【 QPS 】:每个 TiKV 实例上各种命令的 QPS
从监控曲线可以看到,某个 TiKV 的 QPS 明显高于其它 TiKV 节点。

5.3 查看系统表
确定是个别 TiKV 实例的热点问题后,需要进一步确认是哪张表的热点。从 TiDB 3.0 开始,我们可以通过 SQL 查询 information_schema.TiDB_HOT_REGIONS 表定位热点表/索引:
select * from information_schema.TiDB_HOT_REGIONS where TYPE='write';
通过系统表,我们看到写入热点的几张表主要是内容数据的四张汇总表,表结构(已做脱敏处理)类似如下
CREATE TABLE `table_name` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`data_type` varchar(100) NOT NULL COMMENT '数据类型',
`ciz_id` bigint(11) NOT NULL COMMENT '数据标识',
`content` mediumtext DEFAULT NULL COMMENT '内容',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '接入时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_type_cizid` (`data_type`,`ciz_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='XXX 表';
从表结构我们看到,每张表都有一个自增 id 作为主键,自增 id 作为主键在 MySQL 里是推荐的,这样可以提高顺序写入的性能。而TiDB 中数据按照主键的 Key 切分成很多 Region,每个 Region 的数据只会保存在一个节点上面。如果 TiDB 中的表使用自增id作为主键,最新写入的数据大概率都在同一个 Region 上,也就是同一个 TiKV 节点上,从而引起热点。
到此为止,我们已经知道集群慢是写入热点导致的,也知道是哪些表导致的,接下来我们看如何来解决这个问题。
6. 问题解决
既然自增 id 会导致 TiDB 写入热点,我们需要对表结构进行改造
(1)去掉自增 id 的主键,使用 varchar 类型作为主键
(2)配置 shard_row_id_bits 以打散热点
改造后的表结构如下
CREATE TABLE `table_name` (
`global_id` varchar(20) NOT NULL COMMENT '主键',
`data_type` varchar(100) NOT NULL COMMENT '数据类型',
`ciz_id` bigint(11) NOT NULL COMMENT '数据标识',
`content` mediumtext DEFAULT NULL COMMENT '内容',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '接入时间',
PRIMARY KEY (`global_id`),
UNIQUE KEY `uniq_type_cizid` (`data_type`,`ciz_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 SHARD_ROW_ID_BITS=4 COMMENT='XXX 表';
改造完表结构,修改完代码进行压测,压测效果非常好。下面是正式上线后的效果:
SQL 99 的响应时间从之前的 200ms 到 220ms 之间,降低到 20ms 左右

这里感谢开发同学(白建瑞)的积极配合,测试,最终协作解决了写入热点的问题,集群性能得到大幅提升。
7. 总结
TiDB 作为一个分布式数据库,虽然会自动且动态的进行数据的重新分布以到达尽可能的均衡,但是有时候由于业务特性或者业务负载的突变,仍然会产生热点,这时候往往就会出现性能瓶颈。TiDB 是一个分布式的数据库,在表结构设计的时候需要考虑的事情和传统的单机数据库有所区别,需要开发者能够带着「这个表的数据会分散在不同的机器上」这个前提,才能做更好的设计。
TiDB 引入汽车之家后,我们一直在探索,研究,相应的,我们制订了 TiDB 数据库开发规范,用于指导开发者更好的使用 TiDB ,发挥 TiDB 最佳性能。下面是 TiDB 数据库开发规范中表结构设计规范的一条内容 :
【强制】对于 TiDB 3.0 版本,表的主键必须设置为 varchar 类型,并配置 SHARD_ROW_ID_BITS ,正例
CREATE TABLE `tb_example` (
`user_id` varchar(20) NOT NULL COMMENT '用户id',
`name` varchar(10) NOT NULL DEFAULT '' COMMENT '人名',
`created_stime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`modified_stime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`user_id`),
KEY `idx_modified_stime` (`modified_stime`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 SHARD_ROW_ID_BITS=4 COMMENT='TiDB 规范表';
说明
(1)不要使用自增 id(或者 int 类型)作为主键,存在写入热点问题,导致写入慢
(2)主键为 varchar 的目的是为了使用 shard_row_id_bits 打散热点,提高并发写入能力
(3)shard_row_id_bits = 4 表示 tidb_rowid 的值会随机分布成 16 (16=2^4) 个范围区间
(4)主键 varchar 设置多长够用,可以按照十进制的字节计算,int 是 10 位,bigint 是 20 位
备注:
规范会随着 TiDB 版本的迭代及时更新。本文基于 TiDB 3.0 编写。从 TiDB 4.0 开始,
TiDB 提供了一种扩展语法(AutoRandom),用于解决整数类型主键通过 AutoIncrement 属性隐式分配 ID 时的写热点问题。可以利用 AUTO_RANDOM 列属性,将 AUTO_INCREMENT 改为 AUTO_RANDOM,插入数据时让 TiDB 自动为整型主键列分配一个值,消除行 ID 的连续性,从而达到打散热点的目的。
更详细的开发规范请参考汽车之家【 TiDB 数据库开发规范 】。
8. 结束语
本文从一次写入热点的优化实践引出数据库开发规范,数据库 (SQL SERVER,MySQL,TiDB,MongoDB) 每一条规范背后都有一定的意义,经验,各个互联网公司使用数据库的经验也是类似的,请大家严格按照规范使用数据库,提高数据库性能和效率,更好的为业务提供服务。