新一代数据仓库HAWQ的体系架构
从首次提出到发展至今,数据仓库大概可以分为三个阶段,第一阶段是采用共享架构的传统数据仓库,这类数仓主要是面向传统的BI分析,可扩展性较差,大概是十几个节点;第二阶段是无共享架构的MPP,这类数仓主要是面向有复杂需求的传统BI分析,典型的代表有Teradata、Vertica、Greenplum等等;前两个阶段的数据仓库架构都存在缺乏弹性、不易调整、难以实现秒级扩容等问题,而新一代数据仓库克服了这些困难,实现了弹性伸缩和灵活配置。
新一代数据仓库主要是面向大数据和人工智能,支持工业标准的X86服务器,可扩展到上千个节点。如果再进一步细分的话,新一代数据仓库可分为SQL on Hadoop、SQL on Object Store和Hybrid。HAWQ可以归类到Hybrid里面。下面介绍一下HAWQ的体系架构。
体系构架
概览
图1给出了一个典型的HAWQ集群的主要组件。其中有几个Master节点:包括HAWQ master节点,HDFS master节点NameNode,YARN master节点ResourceManager。现在HAWQ元数据服务在HAWQ master节点里面,未来版本会成为单独的服务。其他节点为Slave节点。每个Slave节点上部署有HDFS DataNode,YARN NodeManager以及一个HAWQ Segment。其中YARN是可选组件,如果没有YARN的话,HAWQ会使用自己内置的资源管理器。HAWQ Segment在执行查询的时候会启动多个QE (Query Executor, 查询执行器)。查询执行器运行在资源容器里面。在这个架构下,节点可以动态的加入集群,并且不需要数据重新分布。当一个节点加入集群时,他会向HAWQ Master节点发送心跳,然后就可以接收未来查询了。

图1. HAWQ体系架构
图2是HAWQ内部架构图。可以看到在HAWQ master节点内部有如下几个重要组件:查询解析器(Parser/Analyzer),优化器,资源管理器,资源代理,容错服务,查询派遣器,元数据服务。在Slave节点上安装有一个物理Segment,在查询执行时,针对一个查询,弹性执行引擎会启动多个虚拟Segment同时执行查询,节点间数据交换通过Interconnect(高速互联网络)进行。如果一个查询启动了1000个虚拟Segment,意思是这个查询被均匀的分成了1000份任务,这些任务会并行执行。所以说虚拟Segment数其实表明了查询的并行度。查询的并行度是由弹性执行引擎根据查询大小以及当前资源使用情况动态确定的。下面我逐个来解释这些组件的作用以及它们之间的关系:

图2: HAWQ内部架构
查询解析器:负责解析查询,并检查语法及语义。最终生成查询树传递给优化器。
优化器:负责接受查询树,生成查询计划。针对一个查询,可能有数亿个可能的等价的查询计划,但执行性能差别很大。优化器的作用是找出优化的查询计划。
资源管理器:资源管理器通过资源代理向全局资源管理器(比如YARN)动态申请资源并缓存资源。在不需要的时候返回资源。我们缓存资源的主要原因是减少HAWQ与全局资源管理器之间的交互代价。HAWQ支持毫秒级查询。如果每一个小的查询都去向资源管理器申请资源,这样的话,性能会受到影响。资源管理器同时需要保证查询不使用超过分配给该查询的资源,否则查询之间会相互影响,可能导致系统整体不可用。
HDFS元数据缓存:用于HAWQ确定哪些Segment扫描表的哪些部分。HAWQ需要把计算派遣到数据所在的地方,所以我们需要匹配计算和数据的局部性。这些需要HDFS块的位置信息。位置信息存储在HDFS NameNode上。每个查询都访问HDFS NameNode会造成NameNode的瓶颈。所以我们在HAWQ Master节点上建立了HDFS元数据缓存。
容错服务:负责检测哪些节点可用,哪些节点不可用。不可用的机器会被排除出资源池。
查询派遣器:优化器优化完查询以后,查询派遣器派遣计划到各个节点上执行,并协调查询执行的整个过程。查询派遣器是整个并行系统的粘合剂。
元数据服务:负责存储HAWQ的各种元数据,包括数据库和表信息,以及访问权限信息等。另外,元数据服务也是实现分布式事务的关键。
高速互联网络:负责在节点之间传输数据。使用软件实现,基于UDP协议。UDP协议无需建立连接,从而可以避免TCP高并发连接数的限制。
查询执行流程

图3. 查询执行流程
用户通过JDBC/ODBC提交查询之后,查询解析器解析查询得到查询树,然后优化器根据查询树生成查询计划,派遣器和资源管理器交互得到资源,分解查询计划,然后派遣计划到Segment的执行器上面执行。最终结果会传回给用户。
弹性调度执行
弹性执行引擎有几个关键设计点:存储和计算的完全分离,无状态Segment以及如何使用资源。存储和计算的分离使得我们可以动态的启动任意多个虚拟Segment来执行查询。无状态Segment使得集群更容易扩展。要想保证大规模集群的状态一致性是比较困难的问题,所以我们采用了无状态的Segment。如何使用资源包括如何根据查询的代价申请多少资源,如何有效的使用这些资源以及如何使得数据局部性最优。HAWQ内部针对每一个部分都进行了优化的设计。
极速执行器
执行器是数据库最核心的部件之一,Oushu Database对执行器进行了完全重新设计,充分利用了最新CPU的每一个特性,比如SIMD指令等,可以做到性能的极致。
高速互联网络
高速互联网络的作用是在多个节点之间交换大量数据。HAWQ高速互联网络基于UDP协议。大家可能会疑问为什么HAWQ不使用TCP。其实HAWQ同时支持TCP和UDP两种协议,TCP协议实现早于UDP协议。但是因为我们遇到了TCP不能很好解决的高连接数并发问题,我们才开发了基于UDP的协议。图4展示了一个高速互联网络的例子。
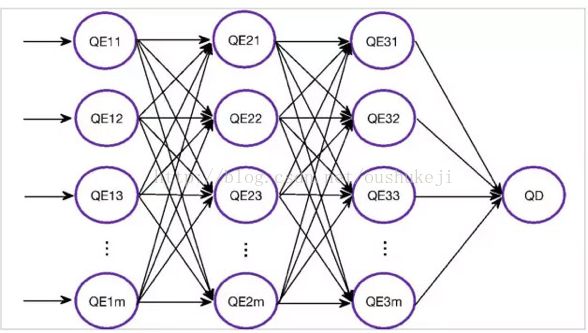
图4. 高速互联网络
例子中各个节点上的执行器进程形成了一个数据交换的流水线。假设每个节点上有1000个进程。有1000个节点,这些进程需要相互交互,每个节点上就会有上百万个连接。TCP是没办法高效地支持这么多的连接数的。所以我们开发了基于UDP的互联协议。针对UDP传输,操作系统是不能保证可靠性的,并且不能保证是有序传递的。所以我们的设计需要保证和支持如下特性:
可靠性:能够保证在丢包的情况下,重传丢失的包
有序性:保证包传递给接受者的最终有序性
流量控制:如果不控制发送者的速度,接收者可能会被淹没,甚至会导致整个网络性能急剧下降
性能和可扩展性:性能和可扩展性是我们需要解决TCP问题的初衷
可支持多种平台
事务管理
事务是数据管理系统一个非常重要的属性。大部分Hadoop里面的SQL引擎不支持事务。让程序员自己保证事务和数据的一致性是非常困难的事。 HAWQ支持事务的所有ACID属性,支持Snapshot Isolation。事务发生由Master节点协调和控制。采用的是泳道模型。并发插入时每个并发会使用各自的泳道,互不冲突。在事务提交的时候通过记录文件逻辑长度的方式来保证一致性。如果事务失败的时候,需要回滚,删除文件末尾的垃圾数据。起初HDFS是不支持truncate的,现在HDFS刚支持的truncate功能是根据HAWQ的需求做出的。
资源管理器
HAWQ支持三级资源管理:
全局资源管理:可以集成YARN,和其他系统共享集群资源。
HAWQ内部资源管理:可以支持查询,用户等级别的资源管理。
操作符级别资源管理:可以针对操作符分配和强制资源使用。
现在HAWQ支持多极资源队列。可以通过DDL方便的定义和修改资源队列。下面是HAWQ资源管理器的主要架构图(图5):
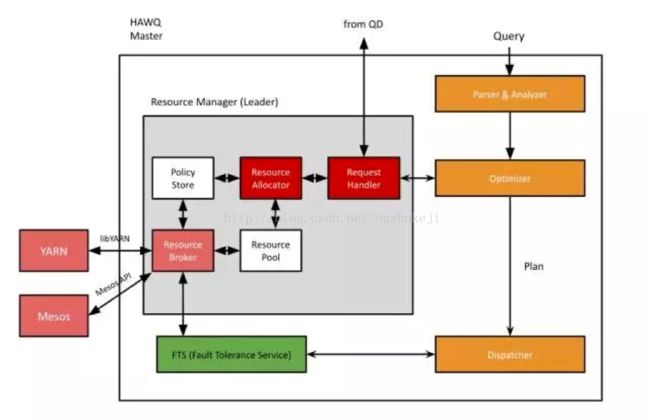
图5. 资源管理器
资源管理器中的各个组件作用如下:
请求处理器:接收查询派遣器进程的资源请求。
资源分配器:负责资源的分配。
资源池:保存所有资源的现有状态。
策略存储:保存所有的分配策略,将来会做到策略可定制。
资源代理:负责与全局资源管理器交互。
存储模块
HAWQ支持多种内部优化的存储格式,比如AO和Parquet。提供MapReduceInputFormat,可以供外部系统直接访问。其他各种存储格式通过扩展框架访问。针对用户专有格式,用户可以自己开发插件。同时支持各种压缩,多极分区等各种功能。