Netty精粹之基于EventLoop机制的高效线程模型
摘要: Infoq有篇文章提到通过Netty4+Thrift压缩二进制编码技术有人实现了10W TPS(1K的复杂POJO对象)跨节点远程服务调用,对于RPC应用来说高性能的三个主题永远是IO模型、数据协议、线程模型,10W TPS的测试结果一方面归功于Thrift方面压缩二进制编码技术的高效(这里有protobuf和thrift相关测试数据)。另一方面还要归功于Netty精心设计的高效线程模型。本文主要对Netty线程模型的设计进行分析,结合对比JavaScript或Node单线程模型的设计与实现,以及对IO密集型和计算密集型应用方面线程模型的设计进行一些思考。转https://my.oschina.net/andylucc/blog/618179
Infoq有篇文章提到通过Netty4+Thrift压缩二进制编码技术有人实现了10W TPS(1K的复杂POJO对象)跨节点远程服务调用,对于RPC应用来说高性能的三个主题永远是IO模型、数据协议、线程模型,10W TPS的测试结果一方面归功于Thrift方面压缩二进制编码技术的高效(这里有protobuf和thrift相关测试数据)。另一方面还要归功于Netty精心设计的高效线程模型。本文主要对Netty线程模型的设计进行分析,结合对比JavaScript或Node单线程模型的设计与实现,以及对IO密集型和计算密集型应用方面线程模型的设计进行一些思考。
单线程Reactor模式
Netty线程模型总体上可以说是Reactor模式的一种变种,我们先看看什么是Reactor模式。这里主要参考维基百科上对Ractor的定义与描述。
Reactor模式是一种事件处理模式,单个或多个事件(Event)并发地投递到事件处理服务(Service Handler),事件处理服务将事件进行分离,同步的将他们分发到对应的事件处理器中去处理。Reactor模式有下面几种参与者:
-
资源:任何提供系统的输入或者消费系统的输出的资源,如:Socket句柄。
-
同步事件分离器:通常使用event loop来进行对资源的阻塞等待,当有资源就绪的时候事件分离器将资源传递给事件分发器。
-
事件分发器:处理请求处理器的注册或者反注册,将资源从时间分离器分发到资源对应的请求处理器中同步执行。
-
请求处理器:应用定义的对相关资源的请求处理。
下面用一张图表示通用Reactor模式的示意图:
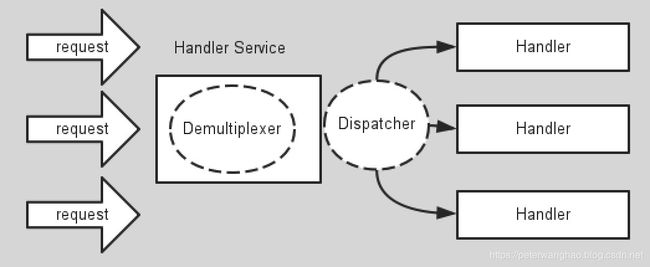
Reactor模式的优点与缺点:
Reactor模式使得应用代码和Reactor实现相分离,这使得用户可以将应用代码设计成最大程度可复用的模块,由于对于请求处理器的调用的是同步的,用户不需要去考虑并发问题,同时也减少了多线程对系统资源的消耗。另一方面,相比于过程化模式的程序,Reactor模式下的程序相对比较难于Debug,同时单线程的设计在多核时代不能够充分利用多核处理器资源,影响了系统的扩展性。
这是最简单的单线程Reactor模式,网上也有对于多线程Reactor模式的一些介绍(这里),本文不做过多介绍,多线程Reactor模式也是在原有的模型基础上进行的变种。
Netty线程模型
Netty是一款高效的NIO框架和工具,基于JAVA NIO提供的API实现。在JAVA NIO方面Selector给Reactor模式提供了基础,Netty结合Selector和Reactor模式设计了高效的线程模型,Reactor模式的参与者主要有下面一些组件:
-
Selector
-
EventLoopGroup/EventLoop
-
ChannelPipeline
下面对其功能和其在Netty之Reactor模式中扮演的角色进行介绍。
Selector
Selector是JAVA NIO提供的SelectableChannel多路复用器,它内部维护着三个SelectionKey集合,负责配合select操作将就绪的IO事件分离出来,落地为SelectionKey,我前面有一篇文章的一部分对Selector进行了相对详细的介绍(这里)。在Netty线程模型中,我认为Selector充当着demultiplexer的角色,而对于SelectionKey我们可以将它看成Reactor模式中的资源。
EventLoopGroup/EventLoop
EventLoopGroup是一组EventLoop的抽象,由于Netty对Reactor模式进行了变种,实际上为更好的利用多核CPU资源,Netty实例中一般会有多个EventLoop同时工作,每个EventLoop维护着一个Selector实例,类似单线程Reactor模式地工作着。至于多少线程可有用户决定,Netty也根据实际上的处理器核数提供了一个默认的数字,我们也建议使用这个数字:
private static final int DEFAULT_EVENT_LOOP_THREADS;
static {
DEFAULT_EVENT_LOOP_THREADS = Math.max(1, SystemPropertyUtil.getInt(
"io.netty.eventLoopThreads", Runtime.getRuntime().availableProcessors() * 2));
if (logger.isDebugEnabled()) {
logger.debug("-Dio.netty.eventLoopThreads: {}", DEFAULT_EVENT_LOOP_THREADS);
}
}
EventLoopGroup提供next接口,可以总一组EventLoop里面按照一定规则获取其中一个EventLoop来处理任务,对于EventLoopGroup这里需要了解的是在Netty中,在Netty服务器编程中我们需要BossEventLoopGroup和WorkerEventLoopGroup两个EventLoopGroup来进行工作。通常一个服务端口即一个ServerSocketChannel对应一个Selector和一个EventLoop线程,也就是我们建议BossEventLoopGroup的线程数参数这是为1。BossEventLoop负责接收客户端的连接并将SocketChannel交给WorkerEventLoopGroup来进行IO处理。下面是他们的工作示意图:
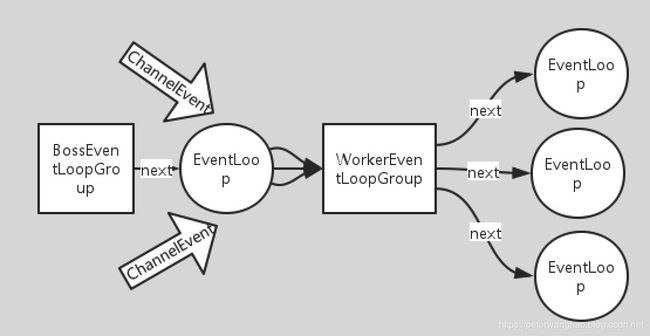
如上图,BossEventLoopGroup通常是一个单线程的EventLoop,EventLoop维护着一个注册了ServerSocketChannel的Selector实例,BoosEventLoop不断轮询Selector将连接事件分离出来,通常是OP_ACCEPT事件,然后将accept得到的SocketChannel交给WorkerEventLoopGroup,WorkerEventLoopGroup会由next选择其中一个EventLoopGroup来将这个SocketChannel注册到其维护的Selector并对其后续的IO事件进行处理。在Reactor模式中BossEventLoopGroup主要是对多线程的扩展,而每个EventLoop的实现涵盖IO事件的分离,和分发(Dispatcher)。
ChannelPipeline
在Netty中ChannelPipeline维护着一个ChannelHandler的链表队列,每个SocketChannel都有一个维护着一个ChannelPipeline实例,而每个ChannelPipeline实例通常维护着一个ChannelHandler链表队列,由于SocketChannel是和SelectionKey关联的,也就是Reactor模式中的资源,当EventLoop将SelectionKey分离出来的时候会将SelectionKey关联的Channel交给Channel关联的ChannelHandler链来处理,那么ChannelPipeline其实是担任着Reactor模式中的请求处理器这个角色。既然提到ChannelPipeline,这里对其也进行一些简单的介绍吧。
ChannelPipeline的默认实现是DefaultChannelPipeline,DefaultChannelPipeline本身维护着一个用户不可见的tail和head的ChannelHandler,他们分别位于链表队列的头部和尾部。tail在更上从的部分,而head在靠近网络层的方向。在Netty中关于ChannelHandler有两个重要的接口,ChannelInBoundHandler和ChannelOutBoundHandler。inbound可以理解为网络数据从外部流向系统内部,而outbound可以理解为网络数据从系统内部流向系统外部。用户实现的ChannelHandler可以根据需要实现其中一个或多个接口,将其放入Pipeline中的链表队列中,ChannelPipeline会根据不同的IO事件类型来找到相应的Handler来处理,同时链表队列是责任链模式的一种变种,自上而下或自下而上所有满足事件关联的Handler都会对事件进行处理。
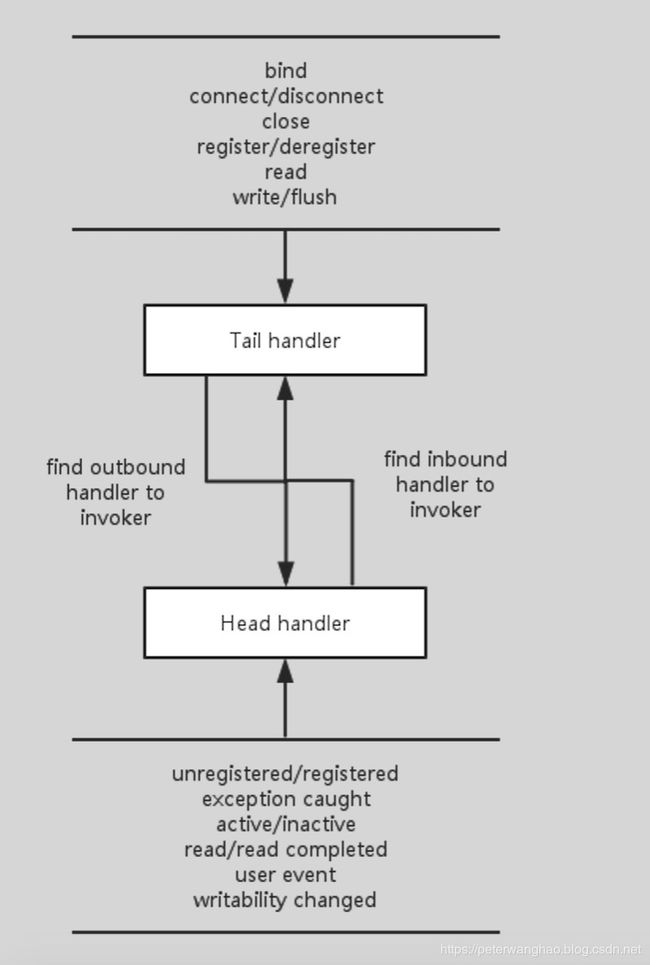
上面部分主要是对比Reactor模式对Netty的线程模型进行相应的对比介绍,下面主要会结合JavaScript单线程模型多介绍一些Netty对EventLoop的实现及相应的思考。
JavaScript单线程模型
众所周知,JavaScript是单线程的,也就是任何时刻同时只能有一个线程堆栈在执行,那么对于下面这段代码可能有同学会疑惑这,这个是怎么执行的:
console.log("A");
setTimeout(function timeout() {
console.log("B");
}, 10);
console.log("C");
....//biz code
console.log("D");
最初的想法是我们设置了一个定时任务,10ms之后执行,如果在biz code处的code需要执行20ms以上,那么timeout怎么能够顺利执行呢,而且单线程是如何做到既执行下面的biz code又执行timeout的呢。事实上如果biz code的部分如果执行时间大于10ms,那么timeout并不会立即准时执行的。要明白其中的原因,我们可以从一张图来理解JavaScript的单线程模型:
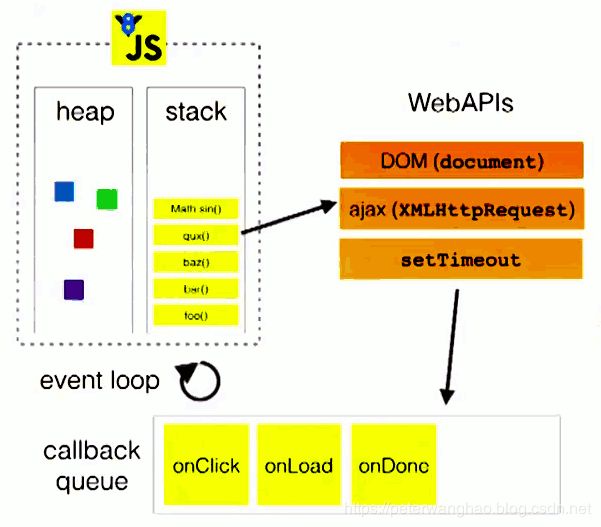
首先简单理解下eventloop机制,即一个线程在执行完主线程后会不断轮询callback队列,取出就绪任务执行,每个循环称为一个tick。因为JavaScript只有一个线程执行,因此也只有一个线程堆栈,结合上面的code实例接单说明一下对应堆栈的变动:
console.log(“A”)入栈执行,输出"A",console.log(“A”)出栈。setTimeout入栈,WebAPIs后台不断检查timeout对象的超时时间是否已经到达,如果到达则会将对于的callback也即timeout放入callback队列。接下来console.log(“C”)会入栈执行,输出"C",然后出栈。…最后console.log(“D”)会入栈执行,输出"D",然后出栈。主区域代码执行完毕线程会不断轮询callback队列来查询是否有就绪callback,如果有则取出执行,如果没有则继续轮询。而对于超时或者是我们使用ajax的callback,后台会根据IO操作或超时时间是否完毕来决定是否将callback放入callback队列,这就是EventLoop机制。Node的单线程EventLoop模型相比于JavaScript的单线程EventLoop模型类似,但是更复杂一些,整体模型可以作为参考去理解。
Netty EventLoop
理解完JavaScript的EventLoop机制之后我们再回过头来看看Netty EventLoop机制的具体实现。对比JavaScript单线程模型图,我画了一张Netty的单线程模型图:
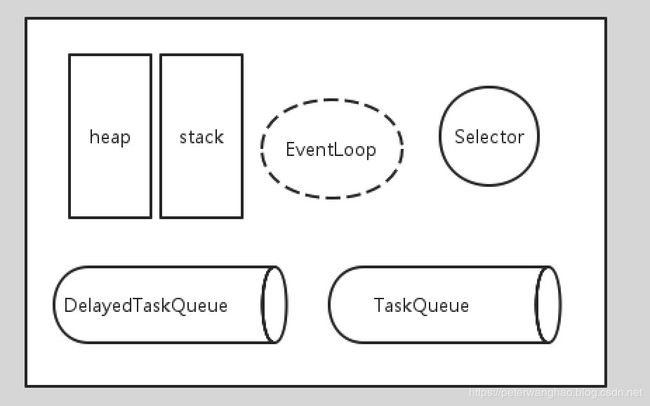
在Netty的EventLoop线程中,这个线程主要需要处理IO事件和其他两种任务,分别为定时任务和一般任务。Netty提供可一个参数ioRatio用于用户调整单线程对于IO处理时间和任务处理时间的分配的比率。这样根据实际应用场景用户可以对这个值进行调整,默认值是50,也就是这个线程会将处理IO的时间和处理任务的时间控制为1:1。
final long ioStartTime = System.nanoTime();
processSelectedKeys();//处理IO事件
final long ioTime = System.nanoTime() - ioStartTime;//处理IO事件的时间
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);//计算用于处理任务的时间
这样尽管一个EventLoop会关联多个Channel,这些Channel在单个线程下并不会出现并发问题,同时对于异步任务的处理也一样,Netty这样设计即免去了并发问题的烦恼,有减少了多线程上下文切换带来的性能损耗,同时基于EventLoopGroup实现的有限的线程数能够充分利用CPU处理能力。
关于IO密集型和CPU密集型的思考
Netty基于单线程设计的EventLoop能够同时处理成千上万的客户端连接的IO事件,缺点是单线程不能够处理时间过长的任务,这样会阻塞使得IO事件的处理被阻塞,严重的时候回造成IO事件堆积,服务不能够高效响应客户端请求。所谓时间过长的任务通常是占用CPU资源比较长的任务,也即CPU密集型,对于业务应用也可能是业务代码的耗时。这点和Node是极其相似的,我可以认为这是基于单线程的EventLoop模型的通病,我们不能够将过长的任务交给这个单线程来处理,也就是不适合CPU密集型应用。那么问题怎么解决呢,参照Node的解决方案,当我们遇到需要处理时间很长的任务的时候,我们可以将它交给子线程来处理,主线程继续去EventLoop,当子线程计算完毕再讲结果交给主线程。这也是通常基于Netty的应用的解决方案,通常业务代码执行时间比较长,我们不能够把业务逻辑交给这个单线程来处理,因此我们需要额外的线程池来分配线程资源来专门处理耗时较长的业务逻辑,这是比较通用的设计方案。