python数据结构与算法 18 无序列表的实现
无序列表的实现:链表
为了实现无序列表,先要实现我们通常称为“链表”的结构。前面说过我们保持列表元素之间的相对位置。当然,在连续存储的情况下不需要额外保存相对位置(如数组),但是如果数据以图1这样的随机方式保存,这就需要为每个元素配置额外的信息,指明它下一个元素的位置(图2),这样每个元素的相对位置,就通过一个元素到另一个元素的链接实现了。

图1 元素不固定物理位置
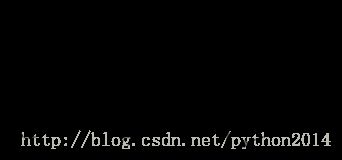
图2通过明确链接维持相对关系
特别要注意,链表第一个元素的位置必须单独指定,一旦知道了第一个元素,它就能告诉我们第2个元素的位置,依次类推。链表的外部引用通常就指向它的头部。类似地,最后一个元素,也要表明他“下面没有了”。
节点类
节点(Node)是实现链表的基本模块,每个节点至少包括两个重要部分。首先,包含节点自身的数据,称为“数据域”。其次,包括对下一个节点的“引用”。下面代码是Node类的代码。为了构造节点,需要初始化节点的数据,如图3,为节点赋值并返回一个节点对象。不过图4才是一般节点的图示方式。节点类也包括访问和修改数据域及指针域的的方法。
Listing 1
classNode:
def__init__(self,initdata):
self.data= initdata
self.next=None
defgetData(self):
returnself.data
defgetNext(self):
returnself.next
defsetData(self,newdata):
self.data= newdata
defsetNext(self,newnext):
self.next= newnext
用上述类创建一个节点对象
>>> temp= Node(93)
>>> temp.getData()
93
特殊的引用值None在节点类和链表中都非常重要。对None的引用代表没有下一个节点,象构造函数中,就是创建一个节点,把并它的“引用”赋值为None。因为有时把最后一个节点称为“接地点”,我们干脆用电气上的接地符号代表None。初始化一个“引用”时,先赋值为None,是个不错的主意。
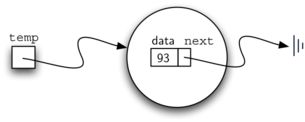
图3节点对象包括数据域和对下一个节点的引用
图4节点的典型表示法
无序列表类
如前所述,无序列表通过一个节点的集合来实现,每个节点包括对下一个节点的引用。只要我们找到第一个节点,跟着引用就能走遍每个数据项。按这个想法,无序列表类必须保存对第一个节点的引用。下面是构造方法,注意每个列表对象包含对“列表头”(head)的引用。
Listing 2
classUnorderedList:
def__init__(self):
self.head=None
创建列表的时候进行初始化,这里没有数据项,赋值语句
>>> mylist= UnorderedList()
创建的链表如图5所示。我们已经讨论过节点类的特殊引用None,这里用来表示head没有引用任何节点。最后,前面给出的链表例子如图6所示,head指向第一个节点,第一个节点包括第一个数据项。同样,第一个节点包括对下一个节点的引用。特别重要的是,链表类不包括任何节点对象,相反,它只包括对列表第一个元素的引用。
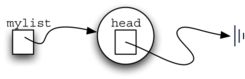
图5 空列表
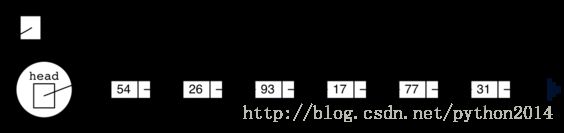
图6 整数链表
下面代码段中的isEmpty方法,用来检查head引用是否是None,方法中的返回值表达式self.head==None,只有当链表中没有节点时为真。既然一个新建链表是空,构造函数和“isEmpty“函数一定保持一致,这也显示了用None来代表“结束”的优势。在python语言中,None能够和任意的引用作比较,如果两个变量引用了同一对象,他们就是相等的。今后还会经常用到这种方法。
Listing 3
defisEmpty(self):
returnself.head==None
回想链表结构只为我们提供了一个入入,即列表的head,所有其他节点都要通过引用逐个访问,这说明,最容易的处理的地方就是在head位置,或开始的位置。换个说法,新数据项总是列表的第一个项,原有数据项都通过引用依次排在它的后面。
图6显示了通过 add方法几次形成的链表。
>>> mylist.add(31)
>>> mylist.add(77)
>>> mylist.add(17)
>>> mylist.add(93)
>>> mylist.add(26)
>>> mylist.add(54)
注意到31是第一个加入的数据,最终它是链表里最后一个。同样,54是最后加入的,它成为链表的第一个节点的数据
Add方法在代码4中实现。每个数据项都在节点对象内部。第2行创建一个新节点,并把数据保存在它的数据域内。然后需要把这个节点与现有结构连接起来,图7表明了两个步骤。第一步,把新节点的引用改成对原来第一个节点的引用。这样列表里其他节点就与新节点建立了链接,只要把修改head为对新节点的引用。第4行的赋值语句设置列表的head。
上面两个步骤的顺序特别重要,如果3和4反序会怎么样?如果先修改了head的引用,就象图8所示,因为head是对列表节点的唯一外部引用入口,一旦失去,所有原来的节点将从内存中消失。
Listing 4
代码4
defadd(self,item):
temp = Node(item)
temp.setNext(self.head)
self.head= temp
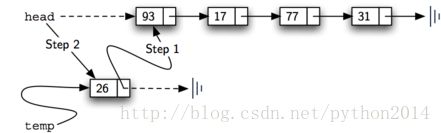
图7 两步增加新节点
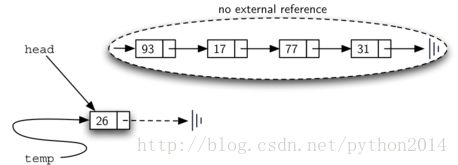
图8两步顺序倒置的结果
下面我们要建立的方法size, search,和 remove,都基于链表的一种技术,即遍历实现的。遍历指系统地访问每个节点的过程。为此,我们从第一个节点的外部引用开始,每访问过一个节点,通过引用移动到下一个节点实现遍历。
为了实现size方法,我们也要遍历链表,这个过程中用一个变量记录我们经过的节点。代码5显示了计数器代码。外部引用叫做current,第二行中初始化为链表的head。开始时因为没有经历过任何节点,所以计数器变量为0,第4-6行实现了遍历。只要current引用没有看到None,就把current指向下一个节点(第6行)。
最后,迭代结束后,count得以返回。图9显示了处理过程。
Listing 5
defsize(self): current =self.head count =0 while current !=None: count = count +1 current = current.getNext()
return count |
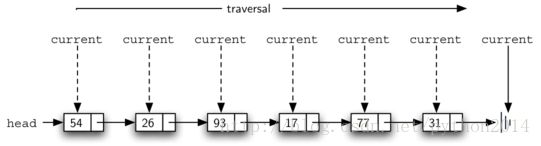
图9 从头到尾的遍历
在无序列表中查找一个值 也要使用遍历技术,当访问每个节点的时候,都要比较它的数据是否与要查找的数据相符。这样,可能不用遍历全部的节点就能找到,如果找到了就不必继续找下去。事实上,如果我们真到了列表的尾部,就说明没找到。
List6显示了查找方法的实现。象在size方法中一样,遍历从head开始(2行),另用了一个found变量记录是否已经找到。因为开始的状态是没找到,found初始化为False。第4行使用了两个条件决定是否要继续遍历,1后面还有节点2、还没找到。行5行检查当前节点的数值是否符合,如果是,found值为True,遍历结束。
Listing 6
defsearch(self,item): current =self.head found =False while current !=Noneandnot found: if current.getData()== item: found =True else: current = current.getNext()
return found |
试着查找一下17
>>> mylist.search(17)
True
17在列表中,遍历过程只需到含17的节点,在这点上,found被置True,while的条件不成立,退出循环,返回found值。如图10所示
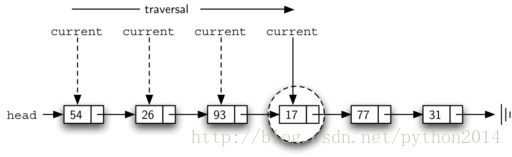
找到后,found变成True,current就是对包含要删除的数据的节点的引用。一种可能的方式是用一种标志代替原来的数值,表明这个数值不存在。但这样一来,链表的节点数量和实际的数量对不上,所以不如直接删除这个节点。
为了删除节点,我们要把待删除节点前面的那个节点的next指向待删除节点后面那个节点就可以了。不幸的是,找到current以后,我们没办法再回到它前面,来不及改了。
解决办法办法是在遍历时使用两个外部引用,current和以前一样,标志当前正在遍历的,新的引用,我们叫它previous,跟在current后面遍历,这样current找到要删除节点时,previous正好停在current前面节点上。
Listing7显示了remove方法的全部代码。2-3行为两个引用分配初值。注意,current开始于head,previous是要跟在current后面的,所以previous的初值是None,因为head前面没有节点(图11)。Found仍是叠代的控制变量。
在6-7行检查是否找到了要删除的节点,如果是,found为True。如果不是,previous和current各自向前一步到下一个节点。再次注意,这个前移的步骤非常关键,previous必须先移动到当前current的位置,current才能向前走。这个过程时常称为“尺蠖”,因为这瞬间previous和current指向同一对象,就象尺蠖弓腰。图12显示了previous和current在查找17的过程中的运动。
(尺蠖,又名“弓腰虫”,行动时一屈一伸像个拱桥——译者)
Listing 7
defremove(self,item): current =self.head previous =None found =False whilenot found: if current.getData()== item: found =True else: previous = current current = current.getNext()
if previous ==None: self.head= current.getNext() else: previous.setNext(current.getNext()) |
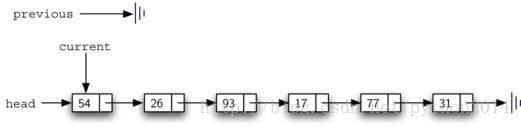
图11 previous和current的初始化
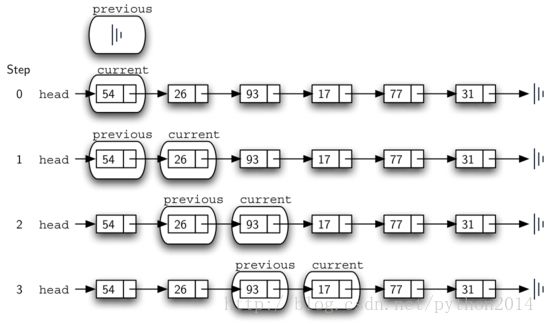
图12 previou和current的运动历程
一旦查找过程结束,开始删除过程。图13显示了要修改的链接。不过有一种特殊情况要处理,如果要删除的数据就在第一个节点上,current就是第一个节点,这里previous仍然是None,我们前面说过,prevous所在节点是要修改它的next引用。但在这种特殊情况下,要修改的不是previous的next,而是列表的head。(图14)
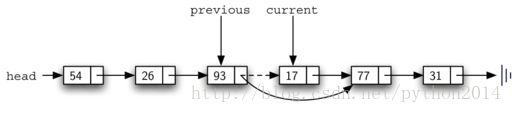
图13 删除中间某节点
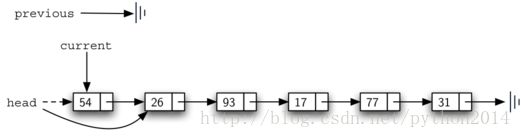
图14 移除第一个节点
12行让我们检查是否上面所说的特殊情况。如果previous还没有前移,它就仍然是None,但这时found是True,在这种情况下(13行),head被修改为指向current的下个节点,效果上就是删除了第一个节点。不过,如果previous不是None,那么要删除的节点就是在中间某处。这种情况下,previous所在节点的next要做修改,15行使用了setNext方法完成删除。要注意的是,在两种情况下,修改引用都指向了current.getNext()。
不过这两种情况是否适用于要删除的节点在最后节点上呢?留作练习。
以下是无序列表的全部代码及测试代码
class Node:
def __init__(self, initdata):
self.data = initdata
self.next = None
def getData(self):
return self.data
def getNext(self):
return self.next
def setData(self, newdata):
self.data = newdata
def setNext(self, newnext):
self.next = newnext
classUnorderedList:
def __init__(self):
self.head = None
def isEmpty(self):
return self.head == None
def add(self, item):
temp = Node(item)
temp.setNext(self.head)
self.head = temp
def size(self):
current = self.head
count = 0
while current != None:
count = count + 1
current = current.getNext()
return count
def search(self, item):
current = self.head
found = False
while current != None and not found:
if current.getData() == item:
found = True
else:
current = current.getNext()
return found
def remove(self, item):
current = self.head
previous = None
found = False
while not found:
if current.getData() == item:
found = True
else:
previous = current
current = current.getNext()
if previous == None:
self.head = current.getNext()
else:
previous.setNext(current.getNext())
mylist =UnorderedList()
mylist.add(31)
mylist.add(77)
mylist.add(17)
mylist.add(93)
mylist.add(26)
mylist.add(54)
print(mylist.size())
print(mylist.search(93))
print(mylist.search(100))
mylist.add(100)
print(mylist.search(100))
print(mylist.size())
mylist.remove(54)
print(mylist.size())
mylist.remove(93)
print(mylist.size())
mylist.remove(31)
print(mylist.size())
print(mylist.search(93))其他方法,append,insert,index和pop留为练习。练习要注意,每个方法都要考虑是否适用于第一个元素或其他情况。另外,insert,index和pop需要链表的索引名,我们约定索引名是整数,从0开始。