Kubernetes服务定时伸
Kubernetes服务定时伸缩
文章目录
- Kubernetes服务定时伸缩
- 前言
- 系统设计
- 扩容服务的管理
- 工作流程
- kube-cronhpa-controller部署
- 1. 安装CRD
- 2. 安装RBAC授权
- 3. 部署`kubernetes-cronhpa-controller`
- 4. 验证`kubernetes-cronhpa-controller`安装状态
- 功能介绍
- 遇到的问题
- 扩容的node存在污点无法flannel等插件
- kube-cronhpa-controller时区不统一
- 结束
前言
容器技术的发展让软件的交付和运维更加标注化,轻量化,自动化.这使得动态调整负载的容其数量成为一件非常简单的事情,在kubernetes中,只需要修改对应的replcas数目即可完成,对应到我们的paas平台上我们只改变手动伸缩进行调整也可以改变所需容器组数量即可
当负载的容量调整变得如此简单后,我们再回过头来看下应用的资源画像。对于大部分互联网的在线应用而言,负载的峰谷分布是存在一定规律的。下图是paas平台中语音识别的敷在曲线,通过观察不难发现峰值的周期是每天早上6点开始持续两个小时,再到晚上九点开始持续两个小时
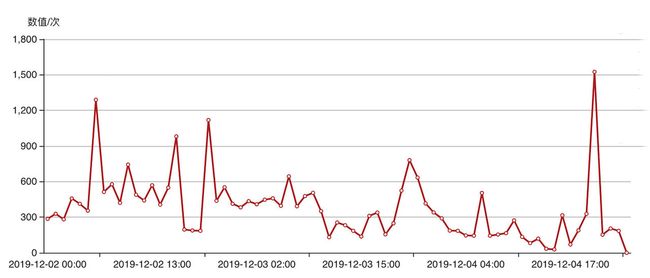
每天低负载的时间为16个小时高负载为8个小时之间性能差距大约在5倍左右,如果使用纯静态的容器规划方式进行部署与管理,可以计算的出资源的浪费比例为53.33%(计算方式:(1-(8*5+16*1)/24*5)*100%).
在面对资源浪费的情况我们可以使用HPA基于指标阈值进行伸缩,paas平台提供CPU,内存,QPS/p95/GPU等策略,但是这里存在一个问题,因为基于资源的伸缩是有一定时延的,这个时延主要包含:采集时延(分钟级)+判断时延(分钟级)+伸缩时延(分钟级)对于上图我们可以看出负载的毛刺非常尖锐,这种情况下普通HPA的伸缩时延会造成负载无法及时变化,短时间内应用整体负载飙高,响应时间变慢,对于一些实时性的业务而言影响非常大.
为了解决这个场景,我们将阿里云开源的k8s组件kube-cronhpa-controller集成到paas平台中,专门应对资源华兴存在周期性的场景.可以通过自定义伸缩规则来提前扩容资源,并且预期的波谷定时将资源回收.我们在底层也结合了autoscaler在资源扩容的时候会根据配置好的伸缩组规则扩展指定机型.
系统设计
引入定时伸缩之后对系统的复杂性带来了提高,主要面临以下几个问题:
- 避免在同一时间存在大量的扩容需求导致原有系统的不可用;
- 定时扩容的容器增多导致原有系统无法新增新的服务;
- 不同的业务服务需要使用不同的机器型号(如cpu/内存);
为了避免上述一二问题的出现我们将现有的资源和定时扩容的资源划分为两个部分,具体如下图所示:

工作资源池与伸缩资源池是两个不可见的空间,并且后者的node全部带有污点:
- 工作资源池:原有的资源池,用来提供服务部署,伸缩等;
- 伸缩资源池:用来部署定时扩容出来的服务.
当某一个服务需要扩容时会对当给前的deployment进行copy并且添加特有的容忍和亲和性,当到达指定的扩容时间deployment所管理的pod就会在伸缩资源池进行启动.
下面的yaml配置截取自
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node/type
operator: In
values:
- AIASR
- key: cronhpa
operator: In
values:
- paas
tolerations:
- key: AI_ASR
value: paas
effect: NoExecute
- key: cronhpa
value: paas
effect: NoExecute
目前我们处理伸缩的资源是利用阿里云的autoscale技术实现的,目前大部分云服务提供商都支持k8snode级别的弹性伸缩,通过这种方式可以更大程度的降低我们机器的付费成本.
扩容服务的管理
在扩容之后的服务管理方面会通过监听cronhpa规则的变化以及父deployment的变化进行更新

原则上新创建的deployment不应该提供修改和删除操作,其修改只能通过监听原deployment的变化进行修改,而删除操作则绑定着将其创建出来的定时伸缩任务,任务存在则新建的deployment存在同样任务删除
工作流程
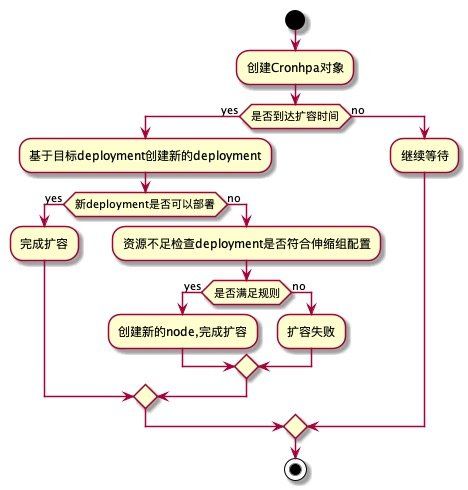
上图的工作流程需要注意,在copy新的deployment的同时会出发autoscale,所以需要提前将云服务商提供的autoscale功能配置好
[root ~]# kubectl get pod -n kube-system | grep auto
cluster-autoscaler-65885dc87b-h4s4r 1/1 Running 0 18h
当新创建的deployment检测到资源不足是回去检查自身的亲和度以及容忍是否符合伸缩组的配置,如果符合就会将新创建的机器弹出,如果不符合则无法完成扩容,这时就需要我们根据当前的需要扩容的pod的affinity配置新的伸缩组.
kube-cronhpa-controller部署
cronhpa是基于CRD的方式开发的controller,使用cronhpa的方式非常简单,整体的使用习惯也尽可能的和HPA保持一致。代码仓库地址
1. 安装CRD
kubectl apply -f config/crds/autoscaling_v1beta1_cronhorizontalpodautoscaler.yaml
2. 安装RBAC授权
# create ClusterRole
kubectl apply -f config/rbac/rbac_role.yaml
# create ClusterRolebinding and ServiceAccount
kubectl apply -f config/rbac/rbac_role_binding.yaml
3. 部署kubernetes-cronhpa-controller
kubectl apply -f config/deploy/deploy.yaml
4. 验证kubernetes-cronhpa-controller安装状态
kubectl get deploy kubernetes-cronhpa-controller -n kube-system -o wide
kubernetes-cronhpa-controller git:(master) kubectl get deploy kubernetes-cronhpa-controller -n kube-system
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
kubernetes-cronhpa-controller 1 1 1 1 49s
功能介绍
弹性伸缩自身是不限制伸缩次数以及伸缩时间的,在开源版本的文档中也给出了配置的示例,具体的调度时间可以按照如下给出的规则自定义填写.
Field name | Mandatory? | Allowed values | Allowed special characters
---------- | ---------- | -------------- | --------------------------
Seconds | Yes | 0-59 | * / , -
Minutes | Yes | 0-59 | * / , -
Hours | Yes | 0-23 | * / , -
Day of month | Yes | 1-31 | * / , - ?
Month | Yes | 1-12 or JAN-DEC | * / , -
Day of week | Yes | 0-6 or SUN-SAT | * / , - ?
但是实际的使用场景其实并不需要很多复杂的规则,过度的开放功能反而会给用户带来选择的烦恼,所以在paas平台中我们直接将其抽象成了如下的形式

下图的配置会在每天1时3分的时候新增一个pod在每天0是0分的时候将扩容的一个pod释放掉

遇到的问题
扩容的node存在污点无法flannel等插件
上文讲到所有新增的机器为了和原有的节点隔离需要包含cronhpa=paas污点,但是对于flannel等基础插件同样会因为污点的存在导致无法部署,最终使新增的node一直处于nodeReady状态,为了解决这个问题,需要修改flannel的DaemonSet在yaml中添加对应污点的容忍,或者是直接添加统配的容忍
tolerations:
- operator: Exists
DaemonSet的部署策略提供了两种选择,一种是OnDelete,即只有手工删除了DaemonSet创建的Pod副本,新的Pod副本才回被创建出来,如果不设置updateStrategy的值,则在Kubernetes1.6之后的版本中会被默认设置为RollingUpdate,所谓的RollingUpdate就是滚动升级
通过观察flannel的DaemonSet的升级方式是OnDelete所以在对其进行更新操作的时候并不会影响其他node的flannel,直接修改DaemonSet即可
kube-cronhpa-controller时区不统一
cronhpa作为一个定时伸缩的组件那自然就会用到时间,如果kube-cronhpa-controller容器内部的时区和主机或者是当前所在的时区不同意就会造成无法在指定时间进行伸缩的情况,官方github上提供的源码并没有指定时区为了解决这个问题,我们在部署镜像的时候需要在yaml中手动指定时区:
spec:
containers:
- command:
- /root/kubernetes-cronhpa-controller
env:
- name: TZ
value: Asia/Shanghai
指定时区之后更新kube-cronhpa-controller进入容器查看时间
[root ~]# kubectl exec -it -n kube-system ack-kubernetes-cronhpa-controller-ack-kubernetes-cronhpa-cc8pwv /bin/sh
~ # date
Wed Dec 25 16:05:02 CST 2019
时间与当前时区同步即可
结束
paas平台服务定时扩容的功能介绍到这里基本就结束了,由于篇幅问题很多细节的问题没有详细介绍,有疑问的老师可以在下方评论区直接提问.