Github复现之FCN
结果:
acc: 0.9656463555555556
acc_cls: 0.8275280139353447
iou: [0.96393878 0.57954449]
miou: 0.7717416350543096
fwavacc: 0.9366305553086615
class_accuracy: 0.8161953126855341
class_recall: 0.6665350808595827
accuracy: 0.9656463555555556
f1_score: 0.7338121766524796

链接https://github.com/shekkizh/FCN.tensorflow
因为是复现,所以代码都有,只是换成自己的数据,我这里就简要说我改了哪里,有问题可以找我探讨一下,我修改或者用的相关代码会打包上传,下面是对修改和要注意的地方做的说明,这个肯定可以用的,请放心使用
环境:cuda8.0、cudnn5.1、tensorflow-gpu 1.4.0(版本高点问题应该不大, 可以先尝试下再换环境)、scipy1.1.0(版本不要超过1.1,不然一定会报scipy这个模块不存在,因为高版本已经没有这个了,这模块是读图像以及改变图像尺寸的,你们也可以在代码里自己改成其他图像处理模块)
复现的关键还是数据存放结构和数据入口,下面说一下:
1.数据结构
文件夹的名字最好和我这个一样哈,后面还有自己写的代码做数据

图像下级目录
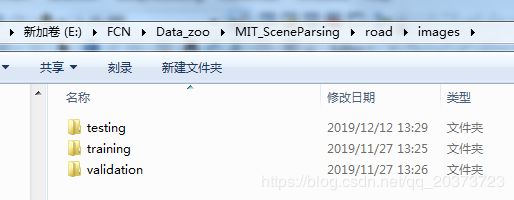
图像格式
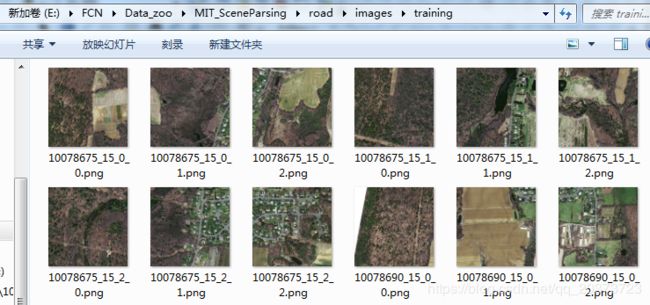
标签下级目录

标签格式,和图像命名一样,一一对应,背景是0,类别从1开始,这个项目是可以多分类的,我这里是二分类,0和1,所以看着是黑色的,这个可以在软件里打开看到

2.数据入口
FCN.py里面那个数据路径就默认就行,后面把自己制作的数据放到对应文件夹下就行了

那个路径改也行,等下把数据放到那个路径下就行了,下面是制作数据
自己新建一个脚本own_data.py
import os
import pickle
def data_dict(path):
data_list = {}
train_dict = []
val_dict = []
test_dict = []
img_full = os.path.join(path, "images", "training")
anno_full = os.path.join(path, "annotations", "training")
files = os.listdir(img_full)
for f in files:
temp_dict = {}
img_path = os.path.join(img_full, f)
label_path = os.path.join(anno_full, f)
temp_dict["image"] = img_path
temp_dict["annotation"] = label_path
temp_dict["filename"] = f
train_dict.append(temp_dict)
img_full = os.path.join(path, "images", "validation")
anno_full = os.path.join(path, "annotations", "validation")
files = os.listdir(img_full)
for f in files:
temp_dict = {}
img_path = os.path.join(img_full, f)
label_path = os.path.join(anno_full, f)
temp_dict["image"] = img_path
temp_dict["annotation"] = label_path
temp_dict["filename"] = f
val_dict.append(temp_dict)
img_full = os.path.join(path, "images", "testing")
anno_full = os.path.join(path, "annotations", "testing")
files = os.listdir(img_full)
for f in files:
temp_dict = {}
img_path = os.path.join(img_full, f)
label_path = os.path.join(anno_full, f)
temp_dict["image"] = img_path
temp_dict["annotation"] = label_path
temp_dict["filename"] = f
test_dict.append(temp_dict)
data_list['training'] = train_dict
data_list['validation'] = val_dict
data_list['testing'] = test_dict
with open('road.pickle','wb') as dt_dict:#数据位置
pickle.dump(data_list,dt_dict)
if __name__ == '__main__':
path = 'E:/FCN/Data_zoo/MIT_SceneParsing/road/'
data_dict(path)
注意:在你的文件夹名字和我的保持一致情况下,运行后会产生一个road.pickle的文件,把这个文件放到前面说的路径中
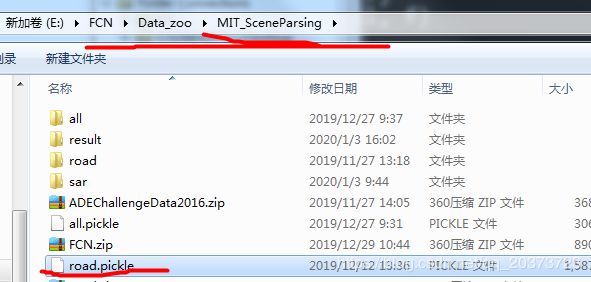
这下数据问题解决了,下面就是训练了,我在这个项目里加了学习率下降策略,所以有必要的代码我都贴一下吧
FCN.py
代码有两个地方要注意的
1.训练是train,预测是predict,要改一下的
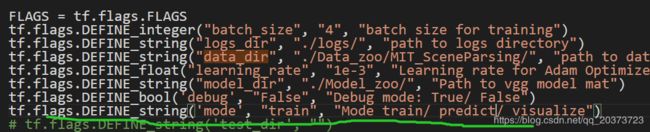
2.这个地方在训练的时候放预模型,预测的时候就是你觉得可以用的那个模型

from __future__ import print_function
import os
import pickle
import tensorflow as tf
import numpy as np
import TensorflowUtils as utils
import read_MITSceneParsingData as scene_parsing
import datetime
import BatchDatsetReader as dataset
import BatchDatsetReader_predict as dataset_pre
from six.moves import xrange
import time
FLAGS = tf.flags.FLAGS
tf.flags.DEFINE_integer("batch_size", "4", "batch size for training")
tf.flags.DEFINE_string("logs_dir", "./logs/", "path to logs directory")
tf.flags.DEFINE_string("data_dir", "./Data_zoo/MIT_SceneParsing/", "path to dataset")
tf.flags.DEFINE_float("learning_rate", "1e-3", "Learning rate for Adam Optimizer")
tf.flags.DEFINE_string("model_dir", "./Model_zoo/", "Path to vgg model mat")
tf.flags.DEFINE_bool('debug', "False", "Debug mode: True/ False")
tf.flags.DEFINE_string('mode', "train", "Mode train/ predict/ visualize")
# tf.flags.DEFINE_string('test_dir', "")
tf.flags.DEFINE_string('result_dir', "E:/20200506/ds/eval/fcn/", "Mode train/ test/ visualize")
MODEL_URL = 'http://www.vlfeat.org/matconvnet/models/beta16/imagenet-vgg-verydeep-19.mat'
MAX_ITERATION = 8000
NUM_OF_CLASSESS = 2
IMAGE_SIZE = 600
STEP = 1000
def vgg_net(weights, image):
layers = (
'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1',
'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3',
'relu3_3', 'conv3_4', 'relu3_4', 'pool3',
'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3',
'relu4_3', 'conv4_4', 'relu4_4', 'pool4',
'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3',
'relu5_3', 'conv5_4', 'relu5_4'
)
net = {}
current = image
for i, name in enumerate(layers):
kind = name[:4]
if kind == 'conv':
kernels, bias = weights[i][0][0][0][0]
kernels = utils.get_variable(np.transpose(kernels, (1, 0, 2, 3)), name=name + "_w")
bias = utils.get_variable(bias.reshape(-1), name=name + "_b")
current = utils.conv2d_basic(current, kernels, bias)
current = tf.layers.batch_normalization(current, training=True)
elif kind == 'relu':
current = tf.nn.relu(current, name=name)
if FLAGS.debug:
utils.add_activation_summary(current)
elif kind == 'pool':
current = utils.avg_pool_2x2(current)
net[name] = current
return net
def inference(image, keep_prob):
"""
Semantic segmentation network definition
:param image: input image. Should have values in range 0-255
:param keep_prob:
:return:
"""
print("setting up vgg initialized conv layers ...")
model_data = utils.get_model_data(FLAGS.model_dir, MODEL_URL)
mean = model_data['normalization'][0][0][0]
mean_pixel = np.mean(mean, axis=(0, 1))
weights = np.squeeze(model_data['layers'])
processed_image = utils.process_image(image, mean_pixel)
with tf.variable_scope("inference"):
image_net = vgg_net(weights, processed_image)
conv_final_layer = image_net["conv5_3"]
pool5 = utils.max_pool_2x2(conv_final_layer)
W6 = utils.weight_variable([7, 7, 512, 4096], name="W6")
b6 = utils.bias_variable([4096], name="b6")
conv6 = utils.conv2d_basic(pool5, W6, b6)
conv6 = tf.layers.batch_normalization(conv6, training=True)
relu6 = tf.nn.relu(conv6, name="relu6")
if FLAGS.debug:
utils.add_activation_summary(relu6)
relu_dropout6 = tf.nn.dropout(relu6, keep_prob=keep_prob)
W7 = utils.weight_variable([1, 1, 4096, 4096], name="W7")
b7 = utils.bias_variable([4096], name="b7")
conv7 = utils.conv2d_basic(relu_dropout6, W7, b7)
conv7 = tf.layers.batch_normalization(conv7, training=True)
relu7 = tf.nn.relu(conv7, name="relu7")
if FLAGS.debug:
utils.add_activation_summary(relu7)
relu_dropout7 = tf.nn.dropout(relu7, keep_prob=keep_prob)
W8 = utils.weight_variable([1, 1, 4096, NUM_OF_CLASSESS], name="W8")
b8 = utils.bias_variable([NUM_OF_CLASSESS], name="b8")
conv8 = utils.conv2d_basic(relu_dropout7, W8, b8)
conv8 = tf.layers.batch_normalization(conv8, training=True)
# annotation_pred1 = tf.argmax(conv8, dimension=3, name="prediction1")
# now to upscale to actual image size
deconv_shape1 = image_net["pool4"].get_shape()
W_t1 = utils.weight_variable([4, 4, deconv_shape1[3].value, NUM_OF_CLASSESS], name="W_t1")
b_t1 = utils.bias_variable([deconv_shape1[3].value], name="b_t1")
conv_t1 = utils.conv2d_transpose_strided(conv8, W_t1, b_t1, output_shape=tf.shape(image_net["pool4"]))
conv_t1 = tf.layers.batch_normalization(conv_t1, training=True)
fuse_1 = tf.add(conv_t1, image_net["pool4"], name="fuse_1")
deconv_shape2 = image_net["pool3"].get_shape()
W_t2 = utils.weight_variable([4, 4, deconv_shape2[3].value, deconv_shape1[3].value], name="W_t2")
b_t2 = utils.bias_variable([deconv_shape2[3].value], name="b_t2")
conv_t2 = utils.conv2d_transpose_strided(fuse_1, W_t2, b_t2, output_shape=tf.shape(image_net["pool3"]))
conv_t2 = tf.layers.batch_normalization(conv_t2, training=True)
fuse_2 = tf.add(conv_t2, image_net["pool3"], name="fuse_2")
shape = tf.shape(image)
deconv_shape3 = tf.stack([shape[0], shape[1], shape[2], NUM_OF_CLASSESS])
W_t3 = utils.weight_variable([16, 16, NUM_OF_CLASSESS, deconv_shape2[3].value], name="W_t3")
b_t3 = utils.bias_variable([NUM_OF_CLASSESS], name="b_t3")
conv_t3 = utils.conv2d_transpose_strided(fuse_2, W_t3, b_t3, output_shape=deconv_shape3, stride=8)
conv_t3 = tf.layers.batch_normalization(conv_t3, training=True)
annotation_pred = tf.argmax(conv_t3, dimension=3, name="prediction")
return tf.expand_dims(annotation_pred, dim=3), conv_t3
# def train(loss_val, var_list, global_step):
# lr = tf.train.natural_exp_decay(FLAGS.learning_rate, global_step, decay_steps=2202, decay_rate=0.9,staircase=False)
# optimizer = tf.train.AdamOptimizer(lr)
# grads = optimizer.compute_gradients(loss_val, var_list=var_list)
# if FLAGS.debug:
# for grad, var in grads:
# utils.add_gradient_summary(grad, var)
# return optimizer.apply_gradients(grads)
def train(loss_val, var_list, lr):
optimizer = tf.train.AdamOptimizer(lr)
grads = optimizer.compute_gradients(loss_val, var_list=var_list)
if FLAGS.debug:
for grad, var in grads:
utils.add_gradient_summary(grad, var)
return optimizer.apply_gradients(grads)
def main(argv=None):
keep_probability = tf.placeholder(tf.float32, name="keep_probabilty")
image = tf.placeholder(tf.float32, shape=[None, IMAGE_SIZE, IMAGE_SIZE, 3], name="input_image")
annotation = tf.placeholder(tf.int32, shape=[None, IMAGE_SIZE, IMAGE_SIZE, 1], name="annotation")
pred_annotation, logits = inference(image, keep_probability)
tf.summary.image("input_image", image, max_outputs=2)
tf.summary.image("ground_truth", tf.cast(annotation, tf.uint8), max_outputs=2)
tf.summary.image("pred_annotation", tf.cast(pred_annotation, tf.uint8), max_outputs=2)
loss = tf.reduce_mean((tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=tf.squeeze(annotation, squeeze_dims=[3]),
name="entropy")))
loss_summary = tf.summary.scalar("entropy", loss)
trainable_var = tf.trainable_variables()
if FLAGS.debug:
for var in trainable_var:
utils.add_to_regularization_and_summary(var)
global_step = tf.Variable(tf.constant(0), trainable=False)
lr = tf.train.exponential_decay(FLAGS.learning_rate, global_step, decay_steps=STEP, decay_rate=0.9,staircase=False)
train_op = train(loss, trainable_var, lr)
print("Setting up summary op...")
summary_op = tf.summary.merge_all()
print("Setting up image reader...")
train_records, valid_records = scene_parsing.read_dataset(FLAGS.data_dir)
print(len(train_records))
print(len(valid_records))
print("Setting up dataset reader")
image_options = {'resize': True, 'resize_size': IMAGE_SIZE}
if FLAGS.mode == 'train':
train_dataset_reader = dataset.BatchDatset(train_records, image_options)
validation_dataset_reader = dataset.BatchDatset(valid_records, image_options)
sess = tf.Session()
print("Setting up Saver...")
saver = tf.train.Saver(max_to_keep=0)
# create two summary writers to show training loss and validation loss in the same graph
# need to create two folders 'train' and 'validation' inside FLAGS.logs_dir
train_writer = tf.summary.FileWriter(FLAGS.logs_dir + '/train', sess.graph)
validation_writer = tf.summary.FileWriter(FLAGS.logs_dir + '/validation')
sess.run(tf.global_variables_initializer())
ckpt = tf.train.get_checkpoint_state(FLAGS.logs_dir)
if ckpt and ckpt.model_checkpoint_path:
# saver.restore(sess, ckpt.model_checkpoint_path) # fine_tuneing
saver.restore(sess, 'E:/FCN/logs/model.ckpt-4000')
print("Model restored...")
if FLAGS.mode == "train":
for itr in xrange(MAX_ITERATION):
train_images, train_annotations = train_dataset_reader.next_batch(FLAGS.batch_size)
feed_dict = {image: train_images, annotation: train_annotations, keep_probability: 0.85, global_step:itr}
if itr % 10 != 0 and itr % STEP != 0:
sess.run(train_op, feed_dict=feed_dict)
if itr % 10 == 0:
train_loss, summary_str, lr_str = sess.run([loss, loss_summary, lr], feed_dict=feed_dict)
print("Step: %d, Train_loss:%g, Learning rate is:%g" % (itr, train_loss, lr_str))
train_writer.add_summary(summary_str, itr)
# train_loss = tf.Summary(value=[tf.Summary.Value(tag="train_loss", simple_value=train_loss)])
# train_writer.add_summary(train_loss, itr)
# lr = tf.Summary(value=[tf.Summary.Value(tag="lr", simple_value=lr_str)])
# train_writer.add_summary(lr, itr)
if itr % STEP == 0:
valid_images, valid_annotations = validation_dataset_reader.next_batch(FLAGS.batch_size)
valid_loss, summary_sva = sess.run([loss, loss_summary], feed_dict={image: valid_images, annotation: valid_annotations,
keep_probability: 1.0})
print("%s ---> Validation_loss: %g" % (datetime.datetime.now(), valid_loss))
# add validation loss to TensorBoard
validation_writer.add_summary(summary_sva, itr)
val_loss = tf.Summary(value=[tf.Summary.Value(tag="val_loss", simple_value=valid_loss)])
validation_writer.add_summary(val_loss, itr)
saver.save(sess, FLAGS.logs_dir + "model.ckpt", itr)
elif FLAGS.mode == "visualize":
valid_images, valid_annotations = validation_dataset_reader.get_random_batch(FLAGS.batch_size)
pred = sess.run(pred_annotation, feed_dict={image: valid_images, annotation: valid_annotations,
keep_probability: 1.0})
valid_annotations = np.squeeze(valid_annotations, axis=3)
pred = np.squeeze(pred, axis=3)
for itr in range(FLAGS.batch_size):
utils.save_image(valid_images[itr].astype(np.uint8), FLAGS.logs_dir, name="inp_" + str(5+itr))
utils.save_image(valid_annotations[itr].astype(np.uint8), FLAGS.logs_dir, name="gt_" + str(5+itr))
utils.save_image(pred[itr].astype(np.uint8), FLAGS.logs_dir, name="pred_" + str(5+itr))
print("Saved image: %d" % itr)
elif FLAGS.mode == "evaluate":### waitiing
pickle_filepath = os.path.join(FLAGS.data_dir, 'road.pickle')
with open(pickle_filepath, 'rb') as f:
result = pickle.load(f)
predict_records = result['validation']
predict_dataset_reader = dataset.BatchDatset(predict_records, image_options)
pre_images, pre_annotations = predict_dataset_reader.get_random_batch(FLAGS.batch_size)
pred = sess.run(pred_annotation, feed_dict={image: pre_images, annotation: pre_annotations, keep_probability: 1.0})
pre_annotations = np.squeeze(pre_annotations, axis=3)
pred = np.squeeze(pred, axis=3)
for itr in range(FLAGS.batch_size):
utils.save_image(pre_images[itr].astype(np.uint8), FLAGS.result_dir, name="inp_" + str(itr))
utils.save_image(pred[itr].astype(np.uint8), FLAGS.result_dir, name="pred_" + str(itr))
print("Saved image: %d" % itr)
# elif FLAGS.mode == "predict":
# pickle_filepath = os.path.join(FLAGS.data_dir, 'road.pickle')
# with open(pickle_filepath, 'rb') as f:
# result = pickle.load(f)
# predict_records = result['testing']
# predict_dataset_reader = dataset_pre.BatchDatset(predict_records, image_options)
# pre_images = predict_dataset_reader.next_batch(FLAGS.batch_size)
# pred = sess.run(pred_annotation, feed_dict={image: pre_images, keep_probability: 1.0})
# pred = np.squeeze(pred, axis=3)
# for itr in range(FLAGS.batch_size):
# utils.save_image(pred[itr].astype(np.uint8), FLAGS.result_dir, name=predict_records[itr]['filename'])
# print("Saved image: %d" % itr)
elif FLAGS.mode == "predict":
time1 = time.time()
pickle_filepath = os.path.join(FLAGS.data_dir, 'road.pickle')
with open(pickle_filepath, 'rb') as f:
result = pickle.load(f)
predict_records = result['testing']
for itr in range(len(predict_records)):
predict_dataset_reader = dataset_pre.BatchDatset(predict_records, image_options)
pre_images = predict_dataset_reader.get_img2(itr)
pre_images = np.expand_dims(pre_images, axis=0)
pred = sess.run(pred_annotation, feed_dict={image: pre_images, keep_probability: 1.0})
pred = np.squeeze(pred, axis=3)
pred_temp = pred[0].astype(np.uint8)
# pred_temp[pred_temp>0] = 255
utils.save_image(pred_temp, FLAGS.result_dir, name=predict_records[itr]['filename'])
print("Saved image: %d" % itr)
time2 = time.time()
print(time2-time1)
if __name__ == "__main__":
tf.app.run()
read_MITSceneParsingData.py,这个脚本里也要改下数据的名字

__author__ = 'charlie'
import numpy as np
import os
import random
from six.moves import cPickle as pickle
from tensorflow.python.platform import gfile
import glob
import TensorflowUtils as utils
# DATA_URL = 'http://sceneparsing.csail.mit.edu/data/ADEChallengeData2016.zip'
DATA_URL = 'http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip'
def read_dataset(data_dir):
# pickle_filename = "MITSceneParsing.pickle"
pickle_filename = "road.pickle"
pickle_filepath = os.path.join(data_dir, pickle_filename)
if not os.path.exists(pickle_filepath):
utils.maybe_download_and_extract(data_dir, DATA_URL, is_zipfile=True)
SceneParsing_folder = os.path.splitext(DATA_URL.split("/")[-1])[0]
result = create_image_lists(os.path.join(data_dir, SceneParsing_folder))
print ("Pickling ...")
with open(pickle_filepath, 'wb') as f:
pickle.dump(result, f, pickle.HIGHEST_PROTOCOL)
else:
print ("Found pickle file!")
with open(pickle_filepath, 'rb') as f:
result = pickle.load(f)
training_records = result['training']
validation_records = result['validation']
del result
return training_records, validation_records
def create_image_lists(image_dir):
if not gfile.Exists(image_dir):
print("Image directory '" + image_dir + "' not found.")
return None
directories = ['training', 'validation']
image_list = {}
for directory in directories:
file_list = []
image_list[directory] = []
file_glob = os.path.join(image_dir, "images", directory, '*.' + 'tif')
file_list.extend(glob.glob(file_glob))
if not file_list:
print('No files found')
else:
for f in file_list:
filename = os.path.splitext(f.split("/")[-1])[0]
annotation_file = os.path.join(image_dir, "annotations", directory, filename + '.tif')
if os.path.exists(annotation_file):
record = {'image': f, 'annotation': annotation_file, 'filename': filename}
image_list[directory].append(record)
else:
print("Annotation file not found for %s - Skipping" % filename)
random.shuffle(image_list[directory])
no_of_images = len(image_list[directory])
print ('No. of %s files: %d' % (directory, no_of_images))
return image_list
BatchDatsetReader.py,这个文件要注意一个地方,axis原始是3,我不知道原始项目使用的什么数据,但是自己数据需要改成2,如果你原始代码遇到数据读取错误可以看下是不是这里

"""
Code ideas from https://github.com/Newmu/dcgan and tensorflow mnist dataset reader
"""
import numpy as np
import scipy.misc as misc
# import imageio
class BatchDatset:
files = []
images = []
annotations = []
image_options = {}
batch_offset = 0
epochs_completed = 0
def __init__(self, records_list, image_options={}):
"""
Intialize a generic file reader with batching for list of files
:param records_list: list of file records to read -
sample record: {'image': f, 'annotation': annotation_file, 'filename': filename}
:param image_options: A dictionary of options for modifying the output image
Available options:
resize = True/ False
resize_size = #size of output image - does bilinear resize
color=True/False
"""
print("Initializing Batch Dataset Reader...")
print(image_options)
self.files = records_list
self.image_options = image_options
self._read_images()
def _read_images(self):
self.__channels = True
self.images = np.array([self._transform(filename['image']) for filename in self.files])
self.__channels = False
self.annotations = np.array(
[np.expand_dims(self._transform(filename['annotation']), axis=2) for filename in self.files])
print (self.images.shape)
print (self.annotations.shape)
def _transform(self, filename):
image = misc.imread(filename)
if self.__channels and len(image.shape) < 3: # make sure images are of shape(h,w,3)
image = np.array([image for i in range(3)])
if self.image_options.get("resize", False) and self.image_options["resize"]:
resize_size = int(self.image_options["resize_size"])
resize_image = misc.imresize(image,
[resize_size, resize_size], interp='nearest')
else:
resize_image = image
return np.array(resize_image)
def get_records(self):
return self.images, self.annotations
def reset_batch_offset(self, offset=0):
self.batch_offset = offset
def next_batch(self, batch_size):
start = self.batch_offset
self.batch_offset += batch_size
if self.batch_offset > self.images.shape[0]:
# Finished epoch
self.epochs_completed += 1
print("****************** Epochs completed: " + str(self.epochs_completed) + "******************")
# Shuffle the data
perm = np.arange(self.images.shape[0])
np.random.shuffle(perm)
self.images = self.images[perm]
self.annotations = self.annotations[perm]
# Start next epoch
start = 0
self.batch_offset = batch_size
end = self.batch_offset
return self.images[start:end], self.annotations[start:end]
def get_random_batch(self, batch_size):
indexes = np.random.randint(0, self.images.shape[0], size=[batch_size]).tolist()
return self.images[indexes], self.annotations[indexes]
BatchDatsetReader_predict.py,我新建了一个预测用的数据读取文件,和上面的那个有点区别,你们自己看吧
"""
Code ideas from https://github.com/Newmu/dcgan and tensorflow mnist dataset reader
"""
import numpy as np
import scipy.misc as misc
class BatchDatset:
files = []
images = []
# annotations = []
image_options = {}
batch_offset = 0
epochs_completed = 0
def __init__(self, records_list, image_options={}):
"""
Intialize a generic file reader with batching for list of files
:param records_list: list of file records to read -
sample record: {'image': f, 'annotation': annotation_file, 'filename': filename}
:param image_options: A dictionary of options for modifying the output image
Available options:
resize = True/ False
resize_size = #size of output image - does bilinear resize
color=True/False
"""
print("Initializing Batch Dataset Reader...")
print(image_options)
self.files = records_list
self.image_options = image_options
self._read_images()
def _read_images(self):
self.__channels = True
self.images = np.array([self._transform(filename['image']) for filename in self.files])
self.__channels = False
# self.annotations = np.array(
# [np.expand_dims(self._transform(filename['annotation']), axis=3) for filename in self.files])
print (self.images.shape)
# print (self.annotations.shape)
def _transform(self, filename):
image = misc.imread(filename)
if self.__channels and len(image.shape) < 3: # make sure images are of shape(h,w,3)
image = np.array([image for i in range(3)])
if self.image_options.get("resize", False) and self.image_options["resize"]:
resize_size = int(self.image_options["resize_size"])
resize_image = misc.imresize(image,
[resize_size, resize_size], interp='nearest')
else:
resize_image = image
return np.array(resize_image)
def get_records(self):
# return self.images, self.annotations
return self.images
def reset_batch_offset(self, offset=0):
self.batch_offset = offset
def next_batch(self, batch_size):
start = self.batch_offset
self.batch_offset += batch_size
if self.batch_offset > self.images.shape[0]:
# Finished epoch
self.epochs_completed += 1
print("****************** Epochs completed: " + str(self.epochs_completed) + "******************")
# Shuffle the data
perm = np.arange(self.images.shape[0])
np.random.shuffle(perm)
self.images = self.images[perm]
# self.annotations = self.annotations[perm]
# Start next epoch
start = 0
self.batch_offset = batch_size
end = self.batch_offset
# return self.images[start:end], self.annotations[start:end]
return self.images[start:end]
def get_random_batch(self, batch_size):
indexes = np.random.randint(0, self.images.shape[0], size=[batch_size]).tolist()
# return self.images[indexes], self.annotations[indexes]
return self.images[indexes]
def get_img(self, num):
indexes = list(range(num))
# return self.images[indexes], self.annotations[indexes]
return self.images[indexes]
def get_img2(self,index):
return self.images[index]
精度评价脚本eval.py
import cv2
import os
import numpy as np
# from sklearn import metrics
# import xlwt as excel
# from decimal import Decimal
mask_path='D:/wcs/own_tf_test/complete_project/CE-Net-master/road/val/labels/' #label path
pres_path='D:/wcs/own_tf_test/complete_project/CE-Net-master/result/' # pres path
classnum=2
def cal_confusion_matrix(mask_path,classnum,pres_path):
confusion_matrix=np.zeros((classnum+1,classnum+1))
im_list=os.listdir(mask_path)
for i in range(classnum):
confusion_matrix[0][i+1]=i
confusion_matrix[i+1][0]=i
for name in im_list:
mask=cv2.imread(mask_path+name,0)
pre=cv2.imread(pres_path+name,0)
# print(pre)
# mask[mask==255]=1 # if label is 0,1,do not ues
pre[pre==255]=1
for i in range(classnum): #pres
for j in range(classnum): #mask
mask_=(np.array(mask==i,dtype=bool))
pre_=(np.array(pre==j,dtype=bool))
num=mask_&pre_
confusion_matrix[i+1][j+1]=confusion_matrix[i+1][j+1]+np.sum(num)
return confusion_matrix
def cal_eval(confusion_matrix):
pi=0
pij=0
pii=0
pji=0
pji_=[]
pij_=[]
mpa_=[]
iou_=[]
sum_pij=0
sum_mpa=0
sum_miou=0
for i in range(classnum):
pij=0
pji=0
for j in range(classnum):
if i==j:
pii=pii+confusion_matrix[j+1,j+1]
pi=confusion_matrix[j+1,j+1]
else:
pij=pij+confusion_matrix[i+1,j+1]
pji=pji+confusion_matrix[j+1,i+1]
pij_.append(pij)
pji_.append(pji)
mpa_.append(float(pi/(pij+pi)))
iou_.append(float(pi/(pij+pji+pi)))
for i in range(classnum):
sum_pij=sum_pij+pij_[i]
sum_mpa=sum_mpa+mpa_[i]
sum_miou=sum_miou+iou_[i]
PA=float(pii/(sum_pij+pii))
MPA=float(sum_mpa/classnum)
MIOU=float(sum_miou/classnum)
# Recall=float()
# Precision=float()
# F1=float()
return PA,MPA,MIOU
if __name__ == '__main__':
matrix=cal_confusion_matrix(mask_path,classnum,pres_path)
print("confusion_matrix : ",matrix)
PA,MPA,MIOU=cal_eval(matrix)
print ("PA : ",PA)
print ("MPA : ",MPA)
print ("MIOU : ",MIOU)
代码地址:https://download.csdn.net/download/qq_20373723/12402804