jvm源码分析之oop-klass对象模型
概述
HotSpot是基于c++实现,而c++是一门面向对象的语言,本身具备面向对象基本特征,所以Java中的对象表示,最简单的做法是为每个Java类生成一个c++类与之对应。
但HotSpot JVM并没有这么做,而是设计了一个OOP-Klass Model。这里的 OOP 指的是 Ordinary Object Pointer (普通对象指针),它用来表示对象的实例信息,看起来像个指针实际上是藏在指针里的对象。而 Klass 则包含元数据和方法信息,用来描述Java类。
之所以采用这个模型是因为HotSopt JVM的设计者不想让每个对象中都含有一个vtable(虚函数表),所以就把对象模型拆成klass和oop,其中oop中不含有任何虚函数,而Klass就含有虚函数表,可以进行method dispatch。
oop-klass对象模型
klass
Klass简单的说是Java类在HotSpot中的c++对等体,用来描述Java类。
Klass主要有两个功能:
- 实现语言层面的Java类
- 实现Java对象的分发功能
Klass是什么时候创建的呢?一般jvm在加载class文件时,会在方法区创建instanceKlass,表示其元数据,包括常量池、字段、方法等。
oop
Klass是在class文件在加载过程中创建的,OOP则是在Java程序运行过程中new对象时创建的。
一个OOP对象包含以下几个部分:
- 对象头 (header)
- Mark Word,主要存储对象运行时记录信息,如hashcode, GC分代年龄,锁状态标志,线程ID,时间戳等
- 元数据指针,即指向方法区的instanceKlass实例
- 实例数据。存储的是真正有效数据,如各种字段内容,各字段的分配策略为longs/doubles、ints、shorts/chars、bytes/boolean、oops(ordinary object pointers),相同宽度的字段总是被分配到一起,便于之后取数据。父类定义的变量会出现在子类定义的变量的前面。
- 对齐填充。仅仅起到占位符的作用,并非必须。
实例说明
假设我们有以下代码:
class Model
{
public static int a = 1;
public int b;
public Model(int b) {
this.b = b;
}
}
public static void main(String[] args) {
int c = 10;
Model modelA = new Model(2);
Model modelB = new Model(3);
}上述代码得OOP-Klass模型入下所示
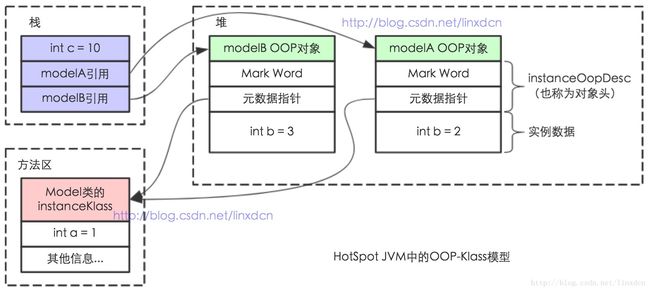
oop-klass的jvm源码分析
oop.hpp
oopDesc类描述了java对象的格式。
oopDesc中包含两个数据成员:_mark 和 _metadata。
- _mark对象即为Mark World,存储对象运行时记录信息,如hashcode, GC分代年龄,锁状态标志,线程ID,时间戳等。
- _metadata即为元数据指针,它是一个联合体,其中_klass是普通指针,_compressed_klass是压缩类指针,这两个指针都指向instanceKlass对象。
// oopDesc is the top baseclass for objects classes. The {name}Desc classes describe
// the format of Java objects so the fields can be accessed from C++.
//这个类描述了java对象的格式
// oopDesc is abstract.
// (see oopHierarchy for complete oop class hierarchy)
//
// no virtual functions allowed 不允许虚函数
class oopDesc {
friend class VMStructs;
private:
volatile markOop _mark; //Mark Word
union _metadata { //元数据指针
wideKlassOop _klass;
narrowOop _compressed_klass;
} _metadata;
}instanceOop.hpp
instanceOopDesc继承了oopDesc,它代表了java类的一个实例化对象。
// An instanceOop is an instance of a Java Class
// Evaluating "new HashTable()" will create an instanceOop.
class instanceOopDesc : public oopDesc {
public:
// aligned header size.
static int header_size() { return sizeof(instanceOopDesc)/HeapWordSize; }
// If compressed, the offset of the fields of the instance may not be aligned.
static int base_offset_in_bytes() {
return UseCompressedOops ?
klass_gap_offset_in_bytes() :
sizeof(instanceOopDesc);
}
static bool contains_field_offset(int offset, int nonstatic_field_size) {
int base_in_bytes = base_offset_in_bytes();
return (offset >= base_in_bytes &&
(offset-base_in_bytes) < nonstatic_field_size * heapOopSize);
}
};instanceKlass.hpp
instanceKlass是Java类的vm级别的表示。
其中,ClassState描述了类加载的状态:分配、加载、链接、初始化。
instanceKlass的布局包括:声明接口、字段、方法、常量池、源文件名等等。
// An instanceKlass is the VM level representation of a Java class.
// It contains all information needed for at class at execution runtime.
class instanceKlass: public Klass {
friend class VMStructs;
public:
enum ClassState {
unparsable_by_gc = 0, // object is not yet parsable by gc. Value of _init_state at object allocation.
allocated, // allocated (but not yet linked)
loaded, // loaded and inserted in class hierarchy (but not linked yet)
linked, // successfully linked/verified (but not initialized yet)
being_initialized, // currently running class initializer
fully_initialized, // initialized (successfull final state)
initialization_error // error happened during initialization
};
//部分内容省略
protected:
// Method array. 方法数组
objArrayOop _methods;
// Interface (klassOops) this class declares locally to implement.
objArrayOop _local_interfaces; //该类声明要实现的接口.
// Instance and static variable information
typeArrayOop _fields;
// Constant pool for this class.
constantPoolOop _constants; //常量池
// Class loader used to load this class, NULL if VM loader used.
oop _class_loader; //类加载器
typeArrayOop _inner_classes; //内部类
Symbol* _source_file_name; //源文件名
}markOop.hpp
markOop描述了java的对象头格式。
// The markOop describes the header of an object.
//markOop描述了Java的对象头
// Note that the mark is not a real oop but just a word.
// It is placed in the oop hierarchy for historical reasons.
//
// Bit-format of an object header (most significant first, big endian layout below):
//
// 32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
//
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
//
// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
class markOopDesc: public oopDesc {
private:
// Conversion
uintptr_t value() const { return (uintptr_t) this; }
public:
// Constants
enum { age_bits = 4,
lock_bits = 2,
biased_lock_bits = 1,
max_hash_bits = BitsPerWord - age_bits - lock_bits - biased_lock_bits,
hash_bits = max_hash_bits > 31 ? 31 : max_hash_bits,
cms_bits = LP64_ONLY(1) NOT_LP64(0),
epoch_bits = 2
};
// The biased locking code currently requires that the age bits be
// contiguous to the lock bits.
enum { lock_shift = 0,
biased_lock_shift = lock_bits,
age_shift = lock_bits + biased_lock_bits,
cms_shift = age_shift + age_bits,
hash_shift = cms_shift + cms_bits,
epoch_shift = hash_shift
};
//部分内容省略
}instanceOopDesc对象的创建过程
allocate_instance方法
instanceOopDesc对象通过instanceKlass::allocate_instance进行创建,实现过程如下:
1、has_finalizer判断当前类是否包含不为空的finalize方法;
2、size_helper确定创建当前对象需要分配多大内存;
3、CollectedHeap::obj_allocate从堆中申请指定大小的内存,并创建instanceOopDesc对象
instanceKlass.cpp
instanceOop instanceKlass::allocate_instance(TRAPS) {
assert(!oop_is_instanceMirror(), "wrong allocation path");
bool has_finalizer_flag = has_finalizer(); // Query before possible GC
int size = size_helper(); // Query before forming handle.
KlassHandle h_k(THREAD, as_klassOop());
instanceOop i;
i = (instanceOop)CollectedHeap::obj_allocate(h_k, size, CHECK_NULL);
if (has_finalizer_flag && !RegisterFinalizersAtInit) {
i = register_finalizer(i, CHECK_NULL);
}
return i;
}obj_allocate方法
CollectedHeap::obj_allocate从堆中申请指定大小的内存,并创建instanceOopDesc对象,实现如下:
CollectedHeap.inline.hpp
oop CollectedHeap::obj_allocate(KlassHandle klass, int size, TRAPS) {
debug_only(check_for_valid_allocation_state());
assert(!Universe::heap()->is_gc_active(), "Allocation during gc not allowed");
assert(size >= 0, "int won't convert to size_t");
HeapWord* obj = common_mem_allocate_init(klass, size, CHECK_NULL);
post_allocation_setup_obj(klass, obj);
NOT_PRODUCT(Universe::heap()->check_for_bad_heap_word_value(obj, size));
return (oop)obj;
}common_mem_allocate_noinit方法
该方法的实现如下:
1、如果开启了TLAB优化,从tlab分配内存并返回(TLAB全称ThreadLocalAllocBuffer,是线程的一块私有内存);
2、如果第一步不执行,调用Universe::heap()->mem_allocate方法在堆上分配内存并返回;
HeapWord* CollectedHeap::common_mem_allocate_noinit(KlassHandle klass, size_t size, TRAPS) {
// Clear unhandled oops for memory allocation. Memory allocation might
// not take out a lock if from tlab, so clear here.
CHECK_UNHANDLED_OOPS_ONLY(THREAD->clear_unhandled_oops();)
if (HAS_PENDING_EXCEPTION) {
NOT_PRODUCT(guarantee(false, "Should not allocate with exception pending"));
return NULL; // caller does a CHECK_0 too
}
HeapWord* result = NULL;
if (UseTLAB) { //如果开启了TLAB优化
result = allocate_from_tlab(klass, THREAD, size);
if (result != NULL) {
assert(!HAS_PENDING_EXCEPTION,
"Unexpected exception, will result in uninitialized storage");
return result;
}
}
bool gc_overhead_limit_was_exceeded = false;
result = Universe::heap()->mem_allocate(size,
&gc_overhead_limit_was_exceeded);
if (result != NULL) {
NOT_PRODUCT(Universe::heap()->
check_for_non_bad_heap_word_value(result, size));
assert(!HAS_PENDING_EXCEPTION,
"Unexpected exception, will result in uninitialized storage");
THREAD->incr_allocated_bytes(size * HeapWordSize);
AllocTracer::send_allocation_outside_tlab_event(klass, size * HeapWordSize);
return result;
}mem_allocate方法
假设使用G1垃圾收集器,该方法实现如下:
g1CollectedHeap.cpp
HeapWord*
G1CollectedHeap::mem_allocate(size_t word_size,
bool* gc_overhead_limit_was_exceeded) {
assert_heap_not_locked_and_not_at_safepoint();
// Loop until the allocation is satisfied, or unsatisfied after GC.
for (int try_count = 1; /* we'll return */; try_count += 1) {
unsigned int gc_count_before;
HeapWord* result = NULL;
if (!isHumongous(word_size)) {
result = attempt_allocation(word_size, &gc_count_before);
} else {
result = attempt_allocation_humongous(word_size, &gc_count_before);
}
if (result != NULL) {
return result;
}
// Create the garbage collection operation...
VM_G1CollectForAllocation op(gc_count_before, word_size);
// ...and get the VM thread to execute it.
VMThread::execute(&op);
if (op.prologue_succeeded() && op.pause_succeeded()) {
// If the operation was successful we'll return the result even
// if it is NULL. If the allocation attempt failed immediately
// after a Full GC, it's unlikely we'll be able to allocate now.
HeapWord* result = op.result();
if (result != NULL && !isHumongous(word_size)) {
// Allocations that take place on VM operations do not do any
// card dirtying and we have to do it here. We only have to do
// this for non-humongous allocations, though.
dirty_young_block(result, word_size);
}
return result;
} else {
assert(op.result() == NULL,
"the result should be NULL if the VM op did not succeed");
}
// Give a warning if we seem to be looping forever.
if ((QueuedAllocationWarningCount > 0) &&
(try_count % QueuedAllocationWarningCount == 0)) {
warning("G1CollectedHeap::mem_allocate retries %d times", try_count);
}
}
ShouldNotReachHere();
return NULL;
}
成员变量在对象中的布局
布局策略
各字段的分配策略为longs/doubles、ints、shorts/chars、bytes/boolean、oops(ordinary object pointers),相同宽度的字段总是被分配到一起,便于之后取数据。父类定义的变量会出现在子类定义的变量的前面。

事实上,它有三种分配策略:
First Fields order: oops, longs/doubles, ints, shorts/chars, bytes
Second Fields order: longs/doubles, ints, shorts/chars, bytes, oops
Third Fields allocation: oops fields in super and sub classes are together.
我们使用的一般是第二种分配策略。
jvm源码实现位于classFileParser.cpp
parseClassFile方法
该函数主要功能就是根据JVM Spec解析class文件,它依次解析以下部分:
1. class文件的一些元信息,包括class文件的magic number以及它的minor/major版本号。
2. constant pool。
3. 类的访问标记以及类的属性(是否是class/interface,当前类的index,父类的index)。
4. interfaces的描述
5. fields的描述
6. methods的描述
5. attributes的描述
在Hotspot中,每个类在初始化时就会完成成员变量在对象布局的初始化。具体而言就是在class文件被解析的时候完成这个步骤的。
该步骤实现如下(以不存在父类和静态字段为例):
1、判断父类是否存在,如果存在,获取父类的非静态字段的大小;
// Field size and offset computation
//判断是否有父类,如果没有父类,非静态字段的大小为0,否则设为父类的非静态字段的大小
int nonstatic_field_size = super_klass() == NULL ? 0 : super_klass->nonstatic_field_size();2、求出首个非静态字段在对象的偏移;
instanceOopDesc::base_offset_in_bytes()方法返回的其实是Java对象头的大小。
假如父类不存在,即nonstatic_field_size为0,首个非静态字段在对象的偏移量即为Java对象头的大小。
heapOopSize指的是oop的大小,它依赖于是否打开UseCompressedOops(默认打开)。打开时为4-byte否则为8-byte。
因为nonstatic_field_size的单位是heapOopSize故要换算成offset需要乘上它。
first_nonstatic_field_offset = instanceOopDesc::base_offset_in_bytes() +
nonstatic_field_size * heapOopSize;3、求出各种字段类型的个数,初始化next指针为first;
next_nonstatic_field_offset变量相当于是一个pointer。
first_nonstatic_field_offset = instanceOopDesc::base_offset_in_bytes() +
nonstatic_field_size * heapOopSize;
next_nonstatic_field_offset = first_nonstatic_field_offset; //初始化next指针为first
unsigned int nonstatic_double_count = fac.count[NONSTATIC_DOUBLE];//double和long字段类型
unsigned int nonstatic_word_count = fac.count[NONSTATIC_WORD]; //int和float字段类型
unsigned int nonstatic_short_count = fac.count[NONSTATIC_SHORT]; //short字段类型
unsigned int nonstatic_byte_count = fac.count[NONSTATIC_BYTE]; //short字段类型
unsigned int nonstatic_oop_count = fac.count[NONSTATIC_OOP]; //oop字段类型4、根据分配策略求出首个字段类型在对象的偏移;
如果是第一种分配策略:先求出oop类型字段和double类型字段的偏移;
如果是第二种分配策略:先求出double类型字段的偏移;
if( allocation_style == 0 ) {
// Fields order: oops, longs/doubles, ints, shorts/chars, bytes
next_nonstatic_oop_offset = next_nonstatic_field_offset;
next_nonstatic_double_offset = next_nonstatic_oop_offset +
(nonstatic_oop_count * heapOopSize);
} else if( allocation_style == 1 ) {
// Fields order: longs/doubles, ints, shorts/chars, bytes, oops
next_nonstatic_double_offset = next_nonstatic_field_offset;
} else if( allocation_style == 2 ) {
//第三种分配策略此处不讨论
}5、求出各种字段类型在对象的偏移;
按照double >> word >> short >> btye的字段顺序:
word字段的偏移 = double字段的偏移 + (double字段的个数 * 一个double字段的字节长度)
short字段的偏移 = word字段的偏移 + (word字段的个数 * 一个word字段的字节长度)
btye字段的偏移 = short字段的偏移 + (short字段的个数 * 一个short字段的字节长度)
next_nonstatic_word_offset = next_nonstatic_double_offset +
(nonstatic_double_count * BytesPerLong);
next_nonstatic_short_offset = next_nonstatic_word_offset +
(nonstatic_word_count * BytesPerInt);
next_nonstatic_byte_offset = next_nonstatic_short_offset +
(nonstatic_short_count * BytesPerShort);参考:【理解HotSpot虚拟机】对象在jvm中的表示:OOP-Klass模型
Java虚拟机(二)对象的创建与OOP-Klass模型
Java对象中成员变量布局及其实现
JVM源码分析之Java对象的创建过程