SEARCHING FOR ACTIVATION FUNCTIONS翻译
1.摘要
在深度神经网络中选择合适的激活函数对网络的动态训练和任务的性能具有显著的影响。目前,最成功也最为被广泛使用的激活函数是修正线性单元(Rectified Linear Unit,ReLU)。虽然已经提出了各种手工设计的ReLU替代方案,但由于收益不一致,没有人设法取代它。在这项工作中,我们提出了利用自动搜索技术来发现新的激活函数。使用穷举和强化学习搜索的组合,我们发现了多个新的激活函数。我们通过使用最佳发现的激活函数进行经验评估来验证搜索的有效性。我们的实验表明,最好的激活函数为 f ( x ) = x ⋅ s i g m o i d ( β x ) f(x)=x·sigmoid(βx) f(x)=x⋅sigmoid(βx),我们称之为Swish,在许多具有挑战性的数据集中使用更深层次的模型证明,它们比ReLU更有效。例如,简单地用Swish单元替换ReLU可以将ImageNet上的top-1分类精度提高0.9%(移动NASNet-A)和0.6%(Inception-ResNet-v2)。Swish的简单性及其与ReLU的相似性使得从业者可以轻松地在任何神经网络中用Swish单元替换ReLU。
2.介绍
每个深度神经网络的核心都是进行线性变换,然后紧接一个激活函数 f ( ⋅ ) f(·) f(⋅)。激活函数在深度神经网络训练的成功中起着重要作用。目前,最成功和被广泛使用的激活函数是修正线性单元(ReLU),被定义为 f ( x ) = m a x ( x , 0 ) f(x)=max(x,0) f(x)=max(x,0)。ReLUs的使用是一项突破性的成就,其使得对最先进的深度神经网络进行全监督训练成为可能。具有ReLU的深度神经网络比具有sigmoid或tanh单元的网络更容易优化,因为当ReLU函数的输入为正时,梯度是线性的。由于其简单性和有效性,ReLU已成为深度学习社区中使用的默认激活函数。
虽然已经提出了许多激活函数来取代ReLU,但没有人能够获得和Relu一样的受欢迎程度。 许多从业者都喜欢ReLU的简单性和可靠性,因为其他激活函数的性能的改进往往在不同的模型和数据集之间表现不一致。
建议替代ReLU的激活函数是人工设计的,以适应被认为重要的属性。然而,最近显示使用搜索技术自动发现传统的人工设计组件非常有效。例如,Zoph等人使用基于强化学习的搜索来找到一个可复制的卷积单元,其优于ImageNet上的人工设计架构。
在这项工作中,我们使用自动搜索技术来发现新的激活函数。我们专注于寻找新的标量激活函数,它们将标量作为输入并输出标量,因为标量激活函数可用于替换ReLU函数而无需更改网络体系结构。使用穷举和强化学习搜索的组合,我们发现许多新的激活函数显示出有前途的表现。为了进一步验证使用自动搜索来发现标量激活函数的有效性,我们根据经验评估了最佳发现的激活函数。最好激活函数,我们称之为Swish,定义为 f ( x ) = x ⋅ s i g m o i d ( β x ) f(x)=x·sigmoid(βx) f(x)=x⋅sigmoid(βx),其中 β β β是一个常数或可训练的参数。我们的广泛实验表明,Swish在应用于各种具有挑战性的领域(如图像分类和机器翻译)的深度网络上始终匹配或优于ReLU。在ImageNet上,用Swish单元替换ReLU可以在移动NASNet-A上提高0.9%的Top-1分类准确率,在Inception-ResNet-v2上提高0.6%。这些精确度的提高是非常重要的,因为一年的架构调整和扩大从初始V3到Inception-ResNet-v2,准确度也仅提高了1.3%。
3.方法
为了利用搜索技术,必须设计一个包含可选择的候选激活函数的搜索空间。设计搜索空间的一个重要挑战是平衡搜索空间的大小和表示能力。过度约束的搜索空间将不包含新颖的激活函数,而过大的搜索空间将难以有效搜索。 为了平衡这两个标准,我们设计了一个简单的搜索空间,其灵感来自Bello等人的优化器搜索空间,它通过使用一元函数和二元函数的组合来构造激活函数。
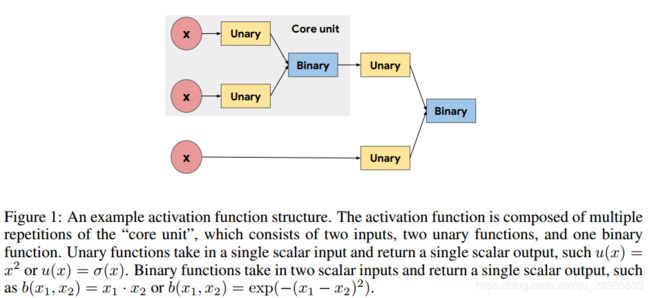
如图1所示,通过重复组成“核心单元(core unit)“来构造激活函数,“核心单元”定义为 b ( u 1 ( x 1 ) , u 2 ( x 2 ) ) b(u1(x1),u2(x2)) b(u1(x1),u2(x2))。核心单元接收两个标量输入,通过一元函数独立地传递每个输入,然后将两个一元输出用一个二元函数组合,并输出一个标量。由于我们的目标是找到将单个标量输入转换为单个标量输出的标量激活函数,因此一元函数的输入仅限于每层的预激活值x和二进制函数输出。
给定搜索空间,搜索算法的目标是找到一元函数和二元函数的有效选择。搜索算法的选择取决于搜索空间的大小。如果搜索空间很小,例如当使用单个核心单元时,则可以详尽地穷举整个搜索空间。如果核心单元重复多次,则搜索空间将非常大(即,大约 1 0 12 10^{12} 1012种可能性),使得穷举搜索方法不可行。
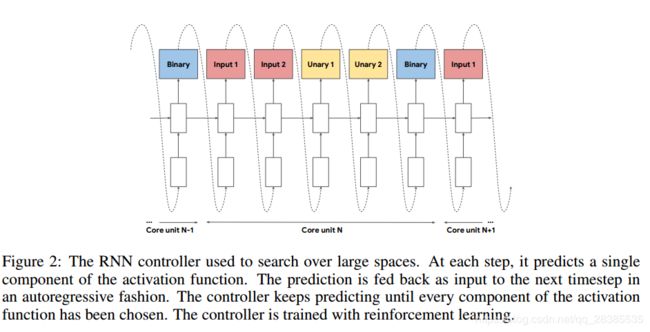
对于大型搜索空间,我们使用了RNN控制器,如下图2中所示。在每个时刻 t t t,控制器预测激活函数的单个组件。在下一个时刻 t + 1 t+1 t+1中将预测反馈给控制器,并且重复该过程直到预测激活函数的每个分量。然后使用预测的字符串来构建激活函数。
一旦通过搜索算法生成了候选激活函数,就在某些任务上训练具有候选激活函数的“子网络”,例如CIFAR-10上的图像分类。训练之后,记录子网络的验证准确性并用于更新搜索算法。在穷举搜索的情况下,保持按验证准确度排序的表现最佳的激活函数的列表。在RNN控制器的情况下,控制器通过强化学习进行训练,以最大化验证准确度,其中验证准确度用作奖励。该训练推动控制器生成具有高验证精度的激活函数。
由于评估单个激活函数需要训练子网络,因此搜索合适的激活函数在计算上是昂贵的。为了减少进行搜索所需的时间,使用分布式训练方案来并行化每个子网络的训练。在该方案中,搜索算法提出了一批候选激活函数,这些函数被添加到队列中。工作机器将激活函数从队列中拉出,训练子网络,并报告相应激活函数的最终验证准确性。验证精度被汇总并用于更新搜索算法。
4.搜索发现
我们使用ResNet-20(He等,2016a)作为基础网络架构进行所有搜索,并在CIFAR-10(Krizhevsky&Hinton,2009)上进行10K步骤的训练。这种受限制的环境可能会使结果产生偏差,因为性能最佳的激活函数可能仅适用于该小型网络。但是,我们在实验部分中显示,许多发现的函数可以推广到更大的模型。穷举搜索用于小搜索空间,而RNN控制器用于较大的搜索空间。使用Policy Proximal Optimization(Schulman等,2017)对RNN控制器进行训练,使用指数移动平均值作为baseline来减少方差。考虑的完整的一元和二元函数如下:
- Unary functions: x , − x , ∣ x ∣ , x 2 , x 3 , x , β x , x + β , l o g ( ∣ x ∣ + ε ) , e x p ( x ) s i n ( x ) , c o s ( x ) , s i n h ( x ) , c o s h ( x ) , t a n h ( x ) , s i n h − 1 ( x ) , t a n − 1 ( x ) , s i n c ( x ) , m a x ( x , 0 ) , m i n ( x , 0 ) , σ ( x ) , l o g ( 1 + e x p ( x ) ) , e x p ( − x 2 ) , e r f ( x ) , β x,−x,|x|,x^2,x^3,\sqrt x,βx,x+β,log(|x|+\varepsilon),exp(x) sin(x),cos(x),sinh(x),cosh(x),tanh(x),sinh−1(x),tan−1(x),sinc(x),max(x,0),min(x,0),σ(x),log(1+exp(x)),exp(−x2),erf(x),β x,−x,∣x∣,x2,x3,x,βx,x+β,log(∣x∣+ε),exp(x)sin(x),cos(x),sinh(x),cosh(x),tanh(x),sinh−1(x),tan−1(x),sinc(x),max(x,0),min(x,0),σ(x),log(1+exp(x)),exp(−x2),erf(x),β
- Binary functions: x 1 + x 2 , x 1 ⋅ x 2 , x 1 − x 2 , x 1 x 2 + ε , m a x ( x 1 , x 2 ) , m i n ( x 1 , x 2 ) , σ ( x 1 ) ⋅ x 2 , e x p ( − β ( x 1 − x 2 ) 2 ) , e x p ( − β ∣ x 1 − x 2 ∣ ) , β x 1 + ( 1 − β ) x 2 x_1+x_2,x_1·x_2,x_1−x_2,\frac {x_1}{x_2+\varepsilon},max(x_1,x_2),min(x_1,x_2),σ(x_1)·x_2,exp(−β(x_1 − x_2)^2),exp(−β|x_1−x_2|),βx_1+(1−β)x_2 x1+x2,x1⋅x2,x1−x2,x2+εx1,max(x1,x2),min(x1,x2),σ(x1)⋅x2,exp(−β(x1−x2)2),exp(−β∣x1−x2∣),βx1+(1−β)x2
其中 β β β表示每通道可训练参数, σ ( x ) = ( 1 + e x p ( − x ) ) − 1 σ(x)=(1+exp(-x))^{-1} σ(x)=(1+exp(−x))−1是sigmoid函数。通过改变用于构造激活函数的核心单元的数量并改变搜索算法可用的一元和二元函数来创建不同的搜索空间。
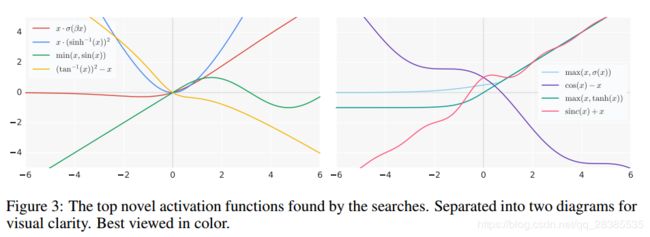
图3描绘了搜索找到的表现最佳的若干新激活函数。我们将强调搜索发现的几个值得注意的趋势:
- 复杂的激活函数性能始终低于更简单的激活功能,可能是由于优化的难度增加。性能最佳的激活功能可以由1或2个核心单元表示。
- 性能最优的激活函数共有的一个共同结构是使用原始预激活x作为最终二元函数的一个输入: b ( x , g ( x ) ) b(x,g(x)) b(x,g(x))。ReLU函数也遵循这种结构,其中 b ( x 1 , x 2 ) = m a x ( x 1 , x 2 ) b(x1,x2)=max(x1,x2) b(x1,x2)=max(x1,x2)和 g ( x ) = 0 g(x)=0 g(x)=0。
- 搜索发现了使用周期函数的激活函数,例如sin和cos。周期函数的最常见用途是通过使用原始预激活x(或线性缩放的x)进行加法或减法。在激活函数中使用周期函数只是在先前的工作中进行了简要探讨(Parascandolo等,2016),因此这些发现的函数为进一步研究提供了一条富有成效的途径。
- 使用除法的函数往往表现不佳,因为当分母接近0时输出会爆炸。只有当分母中的函数要么偏离0时才会成功,例如 c o s h ( x ) cosh(x) cosh(x),或者仅当分子也接近0时才成功 接近0,产生1的输出。
由于使用相对较小的子网络发现激活函数,因此当应用于较大的模型时,它们的性能可能不一致。为了测试最佳表现的新型激活函数对不同架构的稳健性,我们使用预激活ResNet-164(RN)(He等,2016b),Wide ResNet 28-10(WRN)(Zagoruyko&Komodakis, 2016),和DenseNet 100-12(DN)(Huang et al。,2017)模型。我们在TensorFlow中实现了3个模型,并将ReLU函数替换为搜索发现的每个顶级新激活函数。我们使用每个工作中描述的相同超参数,例如使用具有动量的SGD进行优化,并通过报告5个不同运行的中值来遵循先前的工作。
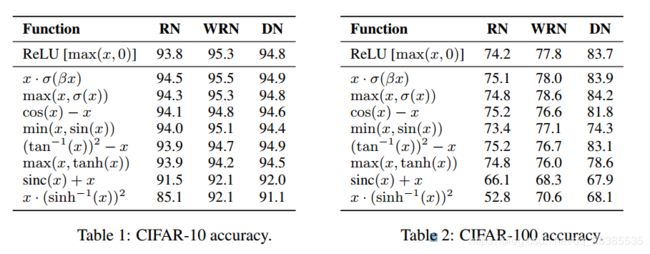
结果显示在表1和表2中。尽管模型体系结构发生了变化,但八个激活函数中有六个成功推广。在这六个激活功能中,要么由于,要么与ResNet-164上的ReLU性能相仿。此外,所发现的两个激活函数 x ⋅ σ ( β x ) x·σ(βx) x⋅σ(βx)和 m a x ( x , σ ( x ) ) max(x,σ(x)) max(x,σ(x))在所有三个模型上的性能始终等于或优于ReLU。
虽然这些结果很有希望,但仍然不清楚发现的激活函数是否可以在具有挑战性的真实世界数据集上成功替换ReLU。为了验证搜索的有效性,在本工作的其余部分,我们专注于实验评估激活函数 x ⋅ σ ( β x ) x·σ(βx) x⋅σ(βx),我们称之为Swish。我们选择广泛评估Swish而不是 m a x ( x , σ ( x ) ) max(x,σ(x)) max(x,σ(x))因为早期实验显示Swish具有更好的推广。在接下来的部分中,我们分析Swish的属性,然后进行全面的实证评估,比较Swish,ReLU和其他候选baseline激活函数,以及各种任务中的大型模型的数量。
5.SWISH
概括地说,Swish定义为 x ⋅ σ ( β x ) x·σ(βx) x⋅σ(βx),其中 σ ( z ) = ( 1 + e x p ( − z ) ) − 1 σ(z)=(1+exp(-z))^{-1} σ(z)=(1+exp(−z))−1是sigmoid函数, β β β是常数或可训练参数。图4绘制了不同 β β β值的Swish图。
(1) β = 1 β=1 β=1
如果 β = 1 β=1 β=1,则Swish等效于Elfwing等人的Sigmoid加权线性单元(SiL),其被提议用于强化学习。
(2) β = 0 β=0 β=0
如果 β = 0 β=0 β=0,则Swish变为缩放线性函数 f ( x ) = x 2 f(x)=\frac{x}{2} f(x)=2x。
(3) β → ∞ β→∞ β→∞
当 β → ∞ β→∞ β→∞时,sigmoid组件接近0-1函数,因此Swish变得像ReLU函数。
以上 β β β值的改变表明可以将Swish松散地视为平滑函数,其在线性函数和ReLU函数之间进行非线性插值。如果将β设置为可训练参数,则可以通过模型控制插值程度。

像ReLU一样,Swish在上界是无限的,下界是有限的。与ReLU不同的是,Swish是平滑且非单调的( non-monotonic)。实际上,Swish的非单调性属于最常见的激活函数。Swish的导数是:
$ f ′ ( x ) = σ ( β x ) + β x ⋅ σ ( β x ) ( 1 − σ ( β x ) ) = σ ( β x ) + β x ⋅ σ ( β x ) − β x ⋅ σ ( β x ) 2 = β x ⋅ σ ( β x ) + σ ( β x ) ( 1 − β x ⋅ σ ( β x ) ) = β f ( x ) + σ ( β x ) ( 1 − β f ( x ) ) f'(x)=\sigma (\beta x)+\beta x \cdot \sigma (\beta x)(1-\sigma (\beta x))\\ \quad \qquad = \sigma(\beta x)+\beta x \cdot \sigma (\beta x)-\beta x \cdot \sigma (\beta x)^2\\ \qquad \qquad = \beta x \cdot \sigma (\beta x)+ \sigma (\beta x)(1-\beta x \cdot \sigma (\beta x))\\ = \beta f(x)+ \sigma (\beta x)(1-\beta f(x)) f′(x)=σ(βx)+βx⋅σ(βx)(1−σ(βx))=σ(βx)+βx⋅σ(βx)−βx⋅σ(βx)2=βx⋅σ(βx)+σ(βx)(1−βx⋅σ(βx))=βf(x)+σ(βx)(1−βf(x))
对于不同的 β β β值,Swish的一阶导数在图5中示出。 β β β的比例控制一阶导数渐近0和1的速度。当 β = 1 β=1 β=1时,对于小于1.25的输入,导数的幅度小于1。因此,具有 β = 1 β=1 β=1的Swish的成功意味着ReLU的梯度保持特性(即,当x>0时具有1的导数)可能不再是现代架构中的明显优势。
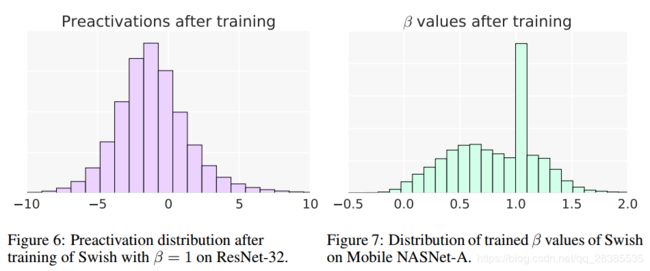
Swish和ReLU之间最显着的区别是当x <0时,Swish的非单调性( non-monotonic)。如图6所示,大部分的预激活落在凸起区域内( − 5 ≤ x ≤ 0 -5≤x≤0 −5≤x≤0), 这表明非单调凹凸是Swish的一个重要方面。可以通过改变 β β β参数来控制凸起的形状。虽然固定 β = 1 β=1 β=1在实践中是有效的,但实验部分显示训练β可以进一步改善某些模型的性能。图7绘制了来自Mobile NASNet-A模型的训练 β β β值的分布(Zoph等,2017)。训练的 β β β值分布在0和1.5之间,并且在β≈1处具有峰值,表明该模型利用了可训练β参数的额外灵活性。
实际上,Swish可以通过大多数深度学习库中的单行代码更改来实现,例如TensorFlow(例如, x ∗ t f . s i g m o i d ( b e t a ∗ x ) x*tf.sigmoid(beta *x) x∗tf.sigmoid(beta∗x),如果使用在提交此作品后发布的TensorFlow版本,则可以 t f . n n . s w i s h ( x ) ) tf.nn.swish(x)) tf.nn.swish(x)))。作为警示,如果使用BatchNorm(Ioffe&Szegedy,2015),则应设置scale参数。由于ReLU函数是分段线性的,一些高级库默认关闭scale参数,但Swish的设置不正确。为了训练Swish网络,我们发现稍微降低用于训练ReLU网络的学习率效果很好。