HashMap和ArrayMap实现原理的区别以及各自优势
一、ArrayMap的构成原理
1、arrayMap的存储结构。
ArrayMap是一个
arrayMap中主要存储的数据的是两个数据,
int[] mHashes;
Object[] mArray;
mHashs中存储出的是每个key的hash值,并且在这些key的hash值在数组当中是从小到大排序的。
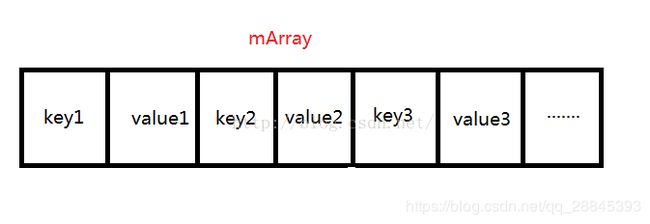
mArray的数组长度是mHashs的两倍,每两个元素分别是key和value,这两元素对应mHashs中的hash值。mArray的结构如下图所示。
ArrayMap方法:
public V put(K key, V value)//添加键值对
public V get(Objectkey)//获取数据
public V remove(Objectkey)//删除数据
public K keyAt(int index) //获取相应的key
public V valueAt(int index)//获取相应的value
public int indexOfKey(Object key)//获取下标例如:
key2和value2分别位于数组的第2位和第3位(从0开始计算)。对应的是hash值就是hash的2/2=1位,也就是mHashes[1];
2、arrayMap的get方法。
@Override
public V get(Object key) {
final int index = indexOfKey(key);
return index >= 0 ? (V)mArray[(index<<1)+1] : null;
}get方法其实就是一个计算index的过程,计算出来之后如果index大于0就代表存在,直接乘以2就是对应的key的值,乘以2加1就是对应的value的值。
3.indexOf(Object key,int hash)方法。
int indexOf(Object key, int hash) {
final int N = mSize;
// Important fast case: if nothing is in here, nothing to look for.
if (N == 0) {
return ~0;
}
int index = ContainerHelpers.binarySearch(mHashes, N, hash);
// If the hash code wasn't found, then we have no entry for this key.
if (index < 0) {
return index;
}
// If the key at the returned index matches, that's what we want.
if (key.equals(mArray[index<<1])) {
return index;
}
// Search for a matching key after the index.
int end;
for (end = index + 1; end < N && mHashes[end] == hash; end++) {
if (key.equals(mArray[end << 1])) return end;
}
// Search for a matching key before the index.
for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) {
if (key.equals(mArray[i << 1])) return i;
}
// Key not found -- return negative value indicating where a
// new entry for this key should go. We use the end of the
// hash chain to reduce the number of array entries that will
// need to be copied when inserting.
return ~end;
}二·、HashMap和ArrayMap各自的优势
1.查找效率
HashMap因为其根据hashcode的值直接算出index,所以其查找效率是随着数组长度增大而增加的。
ArrayMap使用的是二分法查找,所以当数组长度每增加一倍时,就需要多进行一次判断,效率下降。
所以对于Map数量比较大的情况下,推荐使用
2.扩容数量
HashMap初始值16个长度,每次扩容的时候,直接申请双倍的数组空间。
ArrayMap每次扩容的时候,如果size长度大于8时申请size*1.5个长度,大于4小于8时申请8个,小于4时申请4个。
这样比较ArrayMap其实是申请了更少的内存空间,但是扩容的频率会更高。因此,如果当数据量比较大的时候,还是使用HashMap更合适,因为其扩容的次数要比ArrayMap少很多。
3.扩容效率
HashMap每次扩容的时候时重新计算每个数组成员的位置,然后放到新的位置。
ArrayMap则是直接使用System.arraycopy。
所以效率上肯定是ArrayMap更占优势。
这里需要说明一下,网上有一种传闻说因为ArrayMap使用System.arraycopy更省内存空间,这一点我真的没有看出来。arraycopy也是把老的数组的对象一个一个的赋给新的数组。当然效率上肯定arraycopy更高,因为是直接调用的c层的代码。
4.内存耗费
以ArrayMap采用了一种独特的方式,能够重复的利用因为数据扩容而遗留下来的数组空间,方便下一个ArrayMap的使用。而HashMap没有这种设计。
由于ArrayMap只缓存了长度是4和8的时候,所以如果频繁的使用到Map,而且数据量都比较小的时候,ArrayMap无疑是相当的节省内存的。
5.总结
综上所述,
数据量比较小,并且需要频繁的使用Map存储数据的时候,推荐使用ArrayMap。
而数据量比较大的时候,则推荐使用HashMap。