伪分布式+分布式安装Hadoop(两个节点)
- 准备一个新的Linux系统,我这里从之前安装好的Linux中克隆一个



- 更改新系统的设备参数设置,参考本地硬件设置合理参数
- 启动Linux,更改主机名为master
[zhao@localhost ~]$ su #切换至root用户下
[root@localhost zhao]# vim /etc/hostname #修改主机名

[root@localhost zhao]# reboot #重启Linux系统使更改生效

4. 配置网络环境
[zhao@master ~]$ nmtui #配置网卡信息,图形化工具



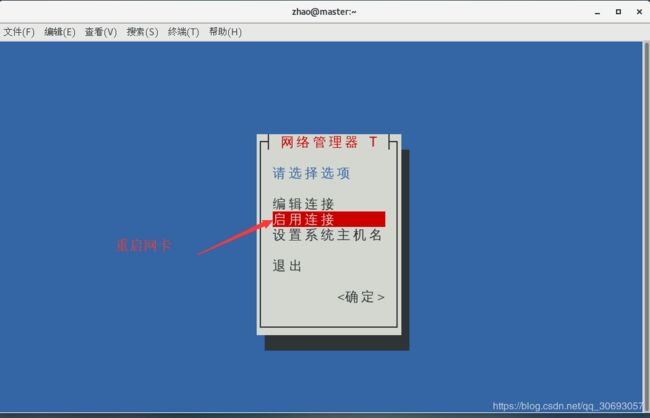
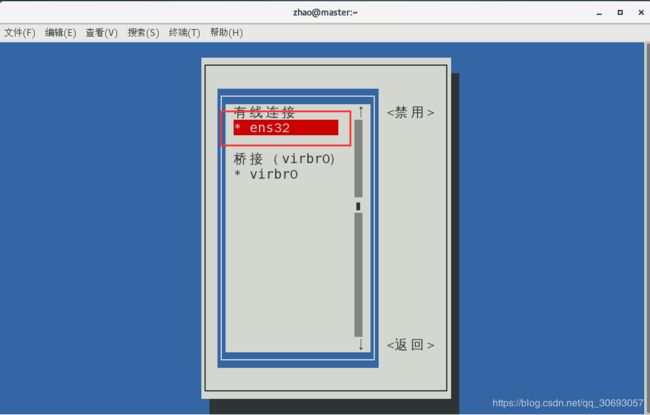
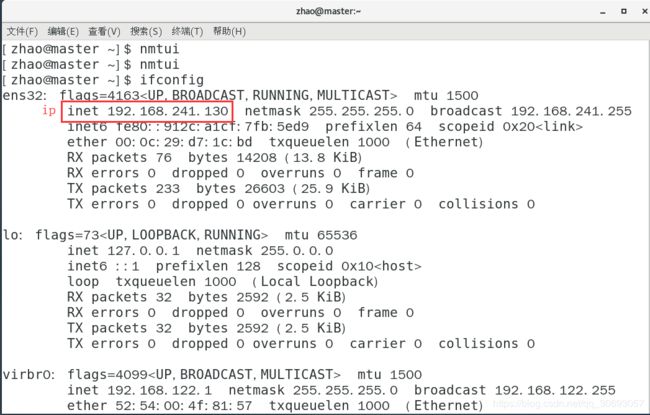
[zhao@master ~]$ ifconfig #查看网卡信息
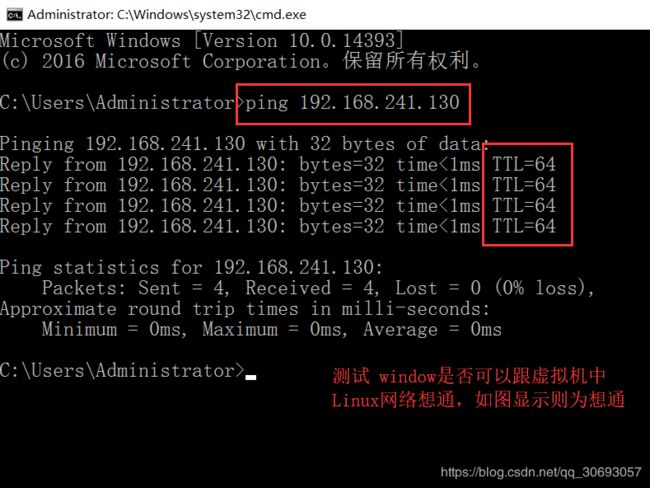
[zhao@master ~]$ ping www.baidu.com #ping 百度,测试是否成功, ctrl+c 结束测试

5.使用Xshell远程连接Linux(这样就不需要进入Vmware虚拟机中操作Linux,提高了工作效率)
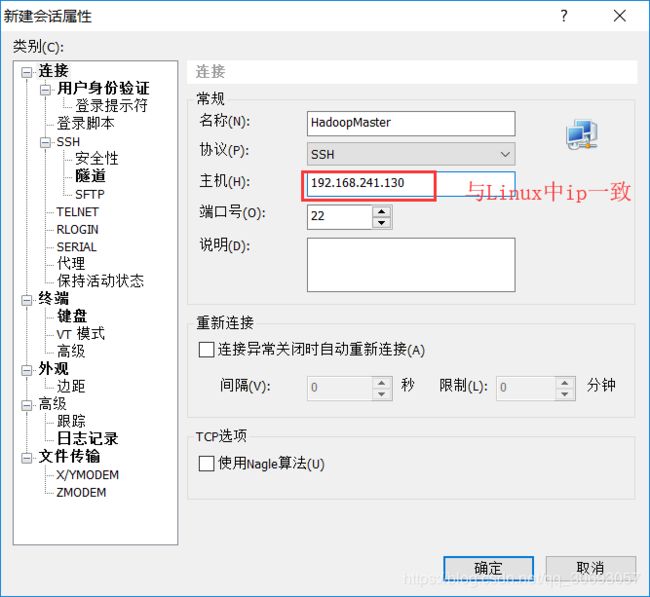

6. 安装JDK(Java环境)
步骤如下:
- 上传jdk安装包到Linux的/home/zhao目录下
- 解压jdk压缩包
- 重命名解压后的文件名(便于后续配置时书写命令)
- 配置jdk环境变量
(1)利用xshell上传下载的 jdk-8u162-linux-x64.tar.gz到/home/zhao目录下
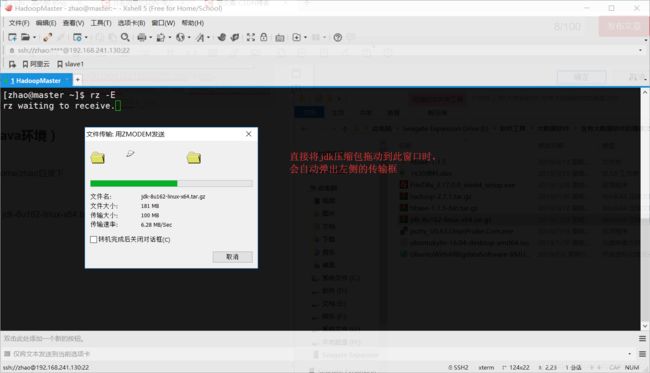
(2)解压压缩包
[zhao@master ~]$ tar -zxvf jdk-8u162-linux-x64.tar.gz

(3)将文件夹jdk1.8.0_162重命名(为了方便后续配置书写命令,也可以不修改)
[zhao@master ~]$ mv jdk1.8.0_162/ jdk #将原文件名jdk1.8.0_162更改为jdk

(4)配置jdk环境变量
[zhao@master ~]$ vim ./.bash_profile
在文件中追加,然后保存退出
export JAVA_HOME=/home/zhao/jdk
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin

[zhao@master ~]$ source ./.bash_profile #立即生效
[zhao@master ~]$ java -version #查看Java版本信息

– 注意:
如果显示的版本号不是自己安装的版本时,说明Linux系统自带了jdk,且是全局的,此时有两种解决方案。
①将自己的jdk环境变量配置到/etc/profile中,形成全局环境变量
②卸载掉系统自带的jdk
[zhao@master ~]$ rpm -qa|grep java
[zhao@master ~]$ sudo yum remove java-1.7.0-openjdk-headless.x86_64 -y # java-1.7.0-openjdk-headless.x86_64 为上述过滤中显示的后两项之一
[zhao@master ~]$ sudo yum remove java-1.8.0-openjdk-headless.x86_64 -y #java-1.8.0-openjdk-headless.x86_64 为上述过来中显示的后两项之一
③ 再次使用 source ~/.bash_profile
④ 使用 java -version 查看版本是否正确
至此jdk安装完毕
6.安装Hadoop
(一)伪分布安装步骤
- 修改/etc/hosts文件
- 配置ssh免密钥登录
- 上传Hadoop的压缩包到/home/zhao
- 解压Hadoop压缩包
- 重命名解压后文件(与jdk重命名作用相同)
- 配置Hadoop环境变量(与jdk配置类似)
- 修改Hadoop的配置文件
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- yarn-env.sh
- mapred-env.sh
- hadoop-env.sh
- slaves
- 格式化namenode
- 启动集群测试伪分布式是否安装成功
(二)分布式安装步骤
- 关闭集群
- 克隆Linux
- 修改主机名为slave
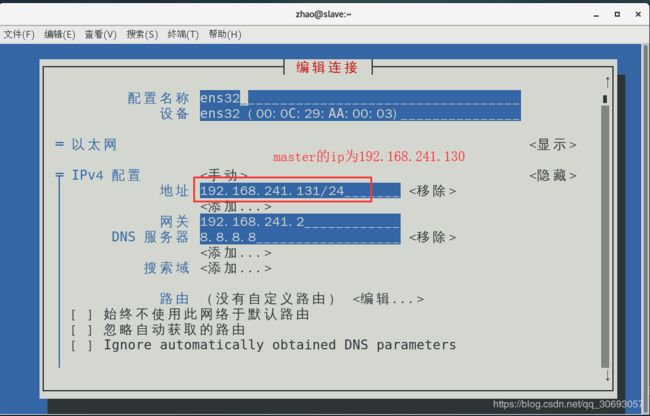
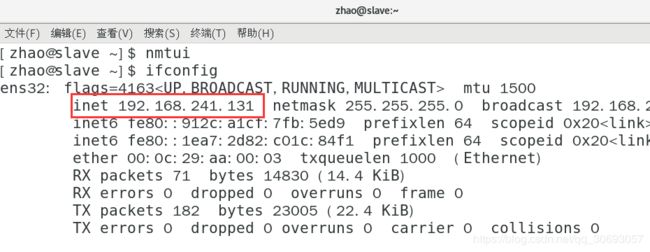
- 修改ip地址为 192.168.241.131
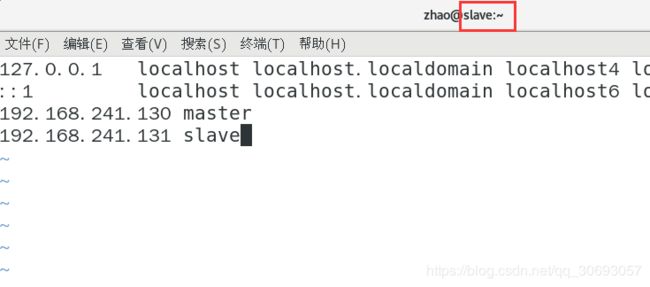
- 在/etc/hosts中添加slave(master、slave都需要做)
- 配置ssh免密登录
- 修改配置文件slaves
- 启动集群
伪分布式安装详情如下
(1) 修改/etc/hosts文件
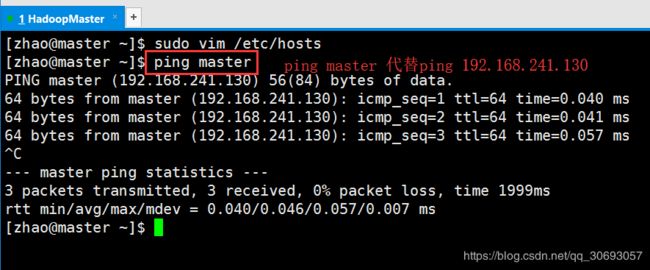
[zhao@master ~]$ sudo vim /etc/hosts
[zhao@master ~]$ ping master
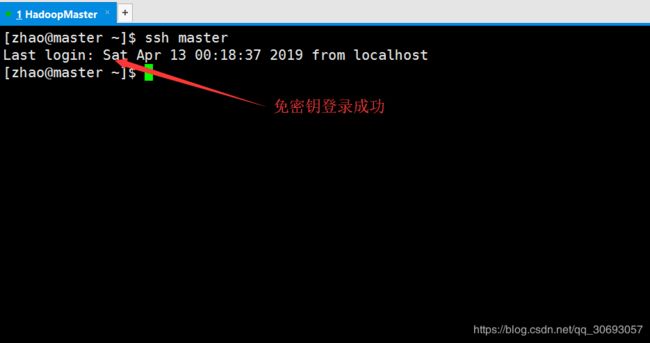
(2)配置ssh免密钥登录
[zhao@master ~]$ ssh-keygen -t rsa
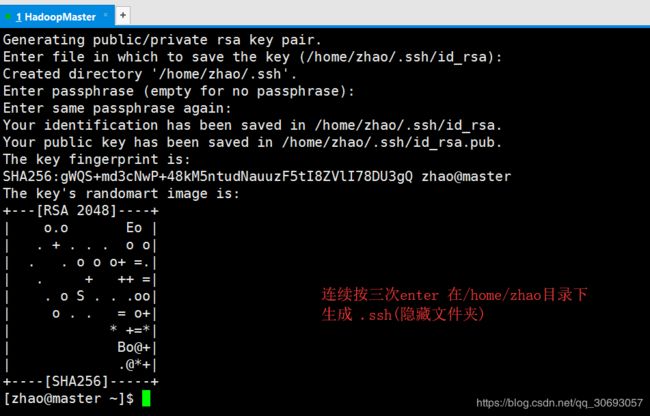
[zhao@master ~]$ cat ./.ssh/id_rsa.pub >> ./.ssh/authorized_keys #将公钥追加到authorized_keys文件。因为免密钥登录时,系统会检索authorized文件
[zhao@master ~]$ chmod 700 .ssh/ #修改.ssh文件夹权限
[zhao@master ~]$ chmod 600 .ssh/* #修改.ssh文件夹下文件权限
(3)上传Hadoop的压缩包到/home/zhao(与上传jdk类似,直接将压缩包拖入到Xshell窗口)

(4)解压Hadoop压缩包
[zhao@master ~]$ tar -zxvf hadoop-2.7.1.tar.gz

(5)重命名解压后文件(与jdk重命名作用相同)
[zhao@master ~]$ mv hadoop-2.7.1 hadoop

(6)配置Hadoop环境变量
[zhao@master ~]$ vim ./.bash_profile
# 追加信息如下
export HADOOP_HOME=/home/zhao/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
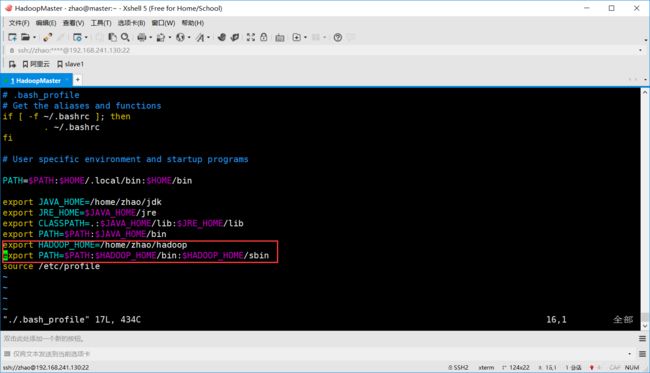
[zhao@master ~]$ source ./.bash_profile #立即生效

(7)修改Hadoop配置文件
[zhao@master ~]$ cd hadoop/etc/hadoop/ # 进入Hadoop配置文件目录
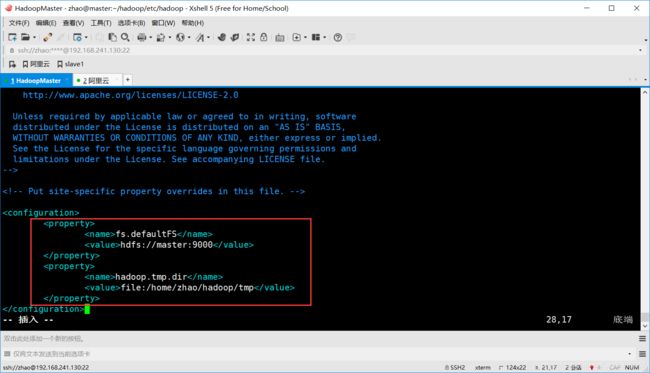
- 配置core-site.xml
[zhao@master hadoop]$ vim core-site.xml #配置信息如下
<configuration>
<property>
<name>fs.defaultFSname> #配置Hadoop默认端口
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname> #配置Hadoop临时文件保存路径
<value>file:/home/zhao/hadoop/tmpvalue>
property>
configuration>
- 配置hdfs-site.xml
[zhao@master hadoop]$ vim hdfs-site.xml
# 配置信息如下:
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname> #配置第二名称节点端口号
<value>master:50090value>
property>
<property>
<name>dfs.namenode.name.dirname> #配置namenode数据保存路径
<value>file:/home/zhao/hadoop/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname> #配置datanode数据保存路径
<value>file:/home/zhao/hadoop/tmp/dfs/datavalue>
property>
<property>
<name>dfs.replicationname> #配置数据备份个数,因为现在采用伪分布方式故先设置为1,等配置分布式方式时再修改
<value>1value>
property>
configuration>

- 配置mapred-site.xml
[zhao@master hadoop]$ cp mapred-site.xml.template mapred-site.xml #复制模板并重命名
[zhao@master hadoop]$ vim mapred-site.xml
# 配置信息如下:
<configuration>
<property>
<name>mapreduce.framework.namename> #mapReduce的资源调度框架采用yarn
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname> #jobhistory服务器端地址
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname> #jobhistory的Web端地址
<value>master:19888value>
property>
configuration>

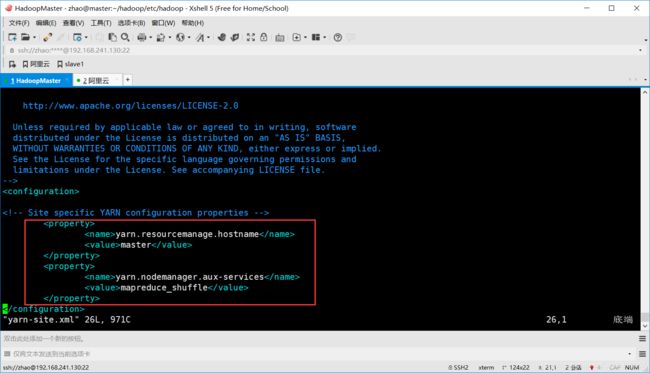
- 配置 yarn-site.xml
[zhao@master hadoop]$ vim yarn-site.xml
# 配置信息如下:
<configuration>
<property>
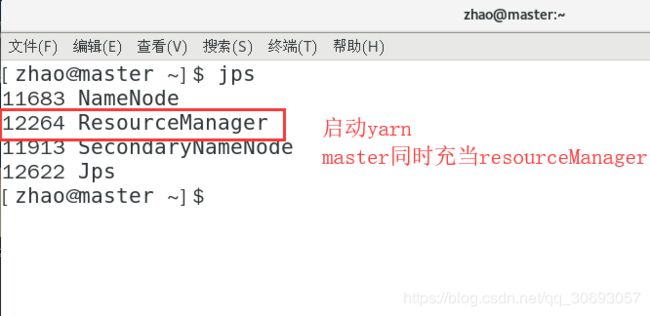
<name>yarn.resourcemanage.hostnamename> #配置担当resourcemanage的节点
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname> #reduce获取数据方式为shuffle
<value>mapreduce_shufflevalue>
property>
configuration>
- yarn-env.sh 添加jdk路径
[zhao@master hadoop]$ vim yarn-env.sh
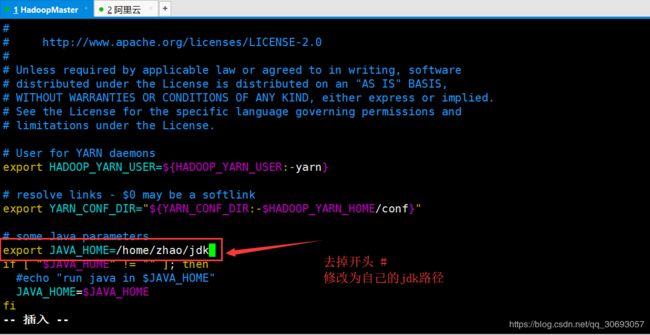
- mapred-env.sh添加jdk路径
[zhao@master hadoop]$ vim mapred-env.sh

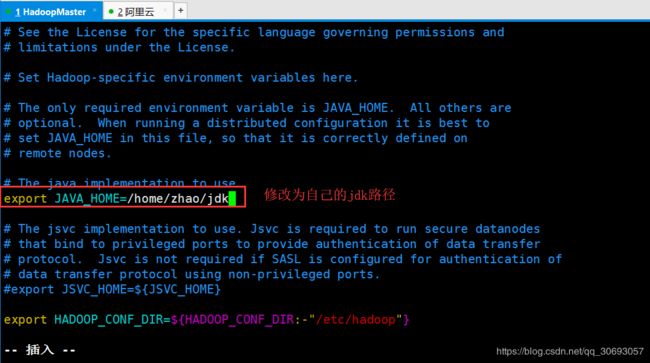
- hadoop-env.sh 添加jdk路径
[zhao@master hadoop]$ vim hadoop-env.sh
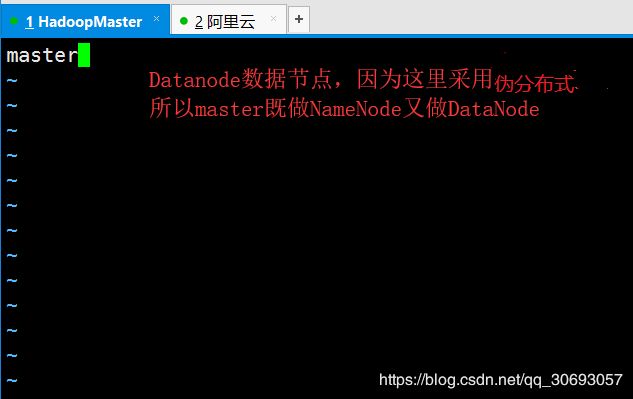
- slaves 添加Datanode主机名
[zhao@master hadoop]$ vim slaves
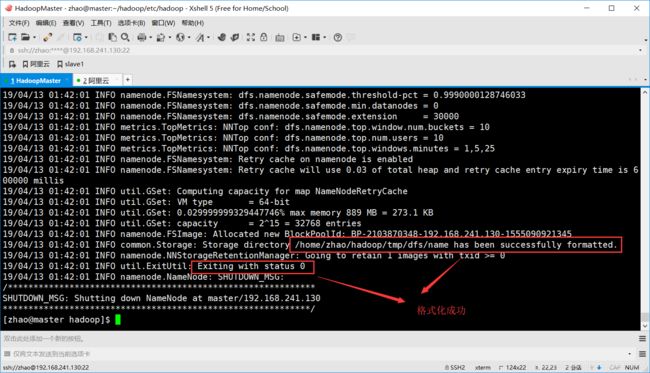
(8)格式化NameNode
[zhao@master hadoop]$ hdfs namenode -format #格式化NameNode
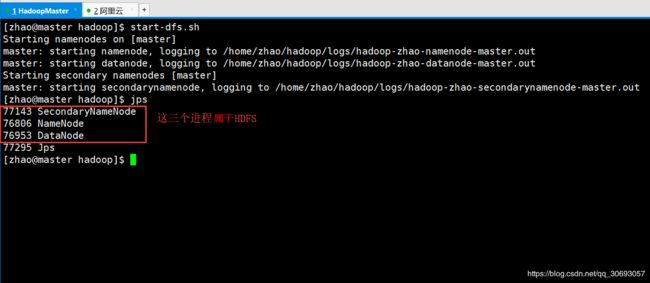
(9)启动集群 测试伪分布式是否安装成功
[zhao@master hadoop]$ start-dfs.sh #启动HDFS

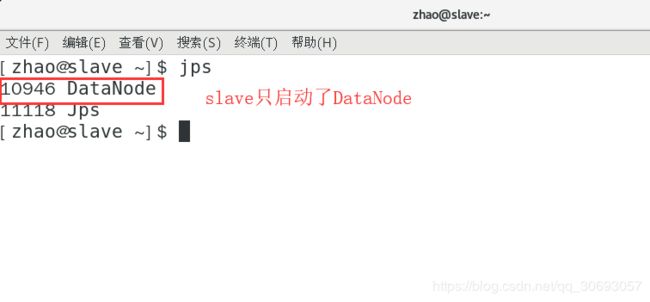
[zhao@master hadoop]$ jps #查看进程命令
[zhao@master hadoop]$ start-yarn.sh #启动yarn

分布式安装详情如下
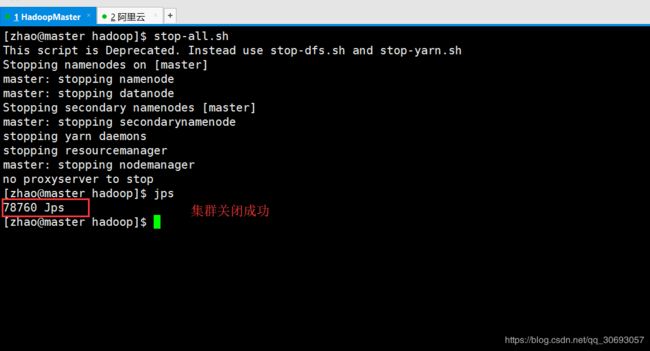
(1)关闭集群
[zhao@master hadoop]$ stop-all.sh #同时关闭 HDFS 和 YARN
(2)关闭master再克隆master,将新得到的Linux当做slave,用于充当DataNode



** 开启新克隆的Linux,以下操作在新克隆的Linux上执行,因为新克隆的Linux,两台Linux主机名称一样,注意区分
(3)修改主机名称为slave(在新克隆的Linux上执行)
[zhao@master ~]$ sudo vim /etc/hostname
[zhao@master ~]$ reboot #重启系统

之后执行命令时 先看清是在slave 执行还是在 master执行 ,通过主机名可以区分
(4)修改ip地址
[zhao@slave ~]$ nmtui #图形化修改网卡

[zhao@slave ~]$ ifconfig #查看网卡信息

(3)在/etc/hosts中添加slave(master、slave都需要做)
[zhao@slave ~]$ sudo vim /etc/hosts #在slave端
[zhao@master ~]$ sudo vim /etc/hosts #在master端

(4)配置ssh免密钥(因为slave克隆的master,所以slave可以登陆master,而master不能登录slave,故需要在slave端生成公钥发送给master)
[zhao@slave .ssh]$ ssh-keygen -t rsa #生成公钥和私钥。(因为之前克隆的master,故slave上有之前生成的master的公钥和私钥,输入该命令时会询问是否覆盖掉之前的,输入Y,这样就会生成slave的公钥和私钥,替换掉了之前master的公钥和私钥)
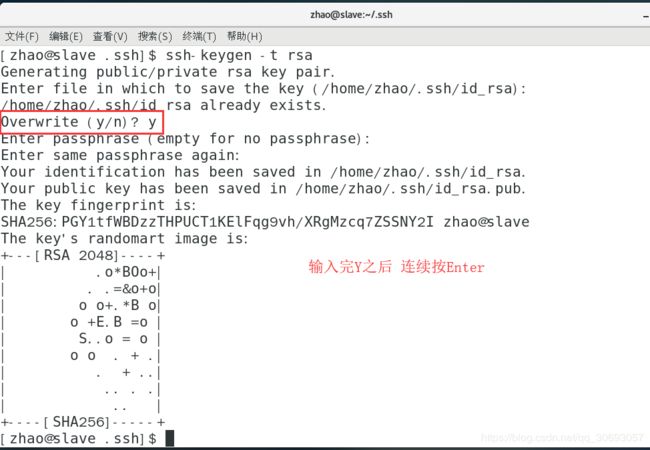
[zhao@slave ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #实现自己免密登录自己

[zhao@slave ~]$ scp ~/.ssh/authorized_keys zhao@master:/home/zhao/.ssh/
#将salve的authorized_keys远程传送到master,覆盖掉master中的authorized_keys。这样master就可以免密登录slave

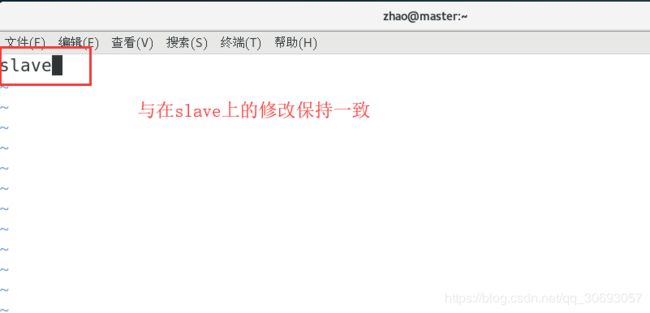
(5)修改Hadoop的配置文件slaves (master,与slave 都需要修改)
[zhao@slave ~]$ vim ~/hadoop/etc/hadoop/slaves #在slave执行

[zhao@master ~]$ vim ~/hadoop/etc/hadoop/slaves #在master执行
(6)在master上启动集群
[zhao@master ~]$ start-dfs.sh #启动HDFS

[zhao@master ~]$ start-yarn.sh #在master上启动yarn
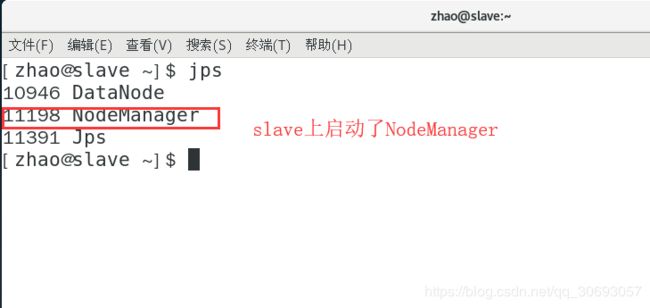
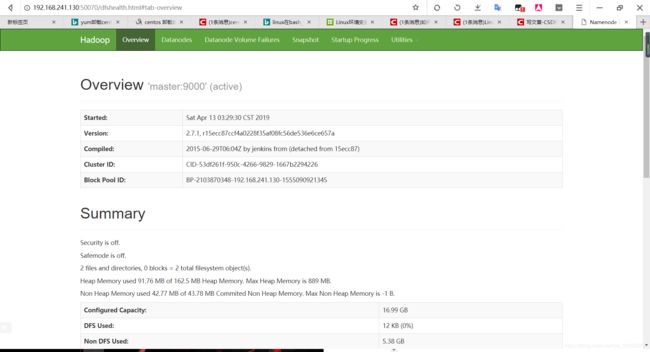
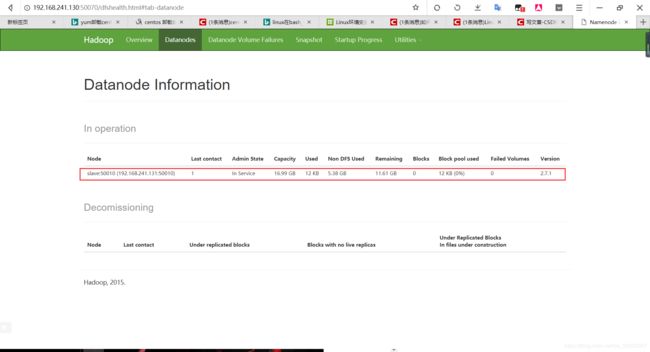
(7)通过window的Web页面查看HDFS
- 关闭master和slave的防火墙,分别在master与slave执行下列命令
[zhao@master ~]$ sudo systemctl stop firewalld
在浏览器中输入 192.168.241.130:50070