【目标检测系列:八】RetinaNet Focal Loss for Dense Object Detection
ICCV 2017
Focal Loss for Dense Object Detection
github
解决类别不平衡,提出 Focal loss
- 解决one-stage目标检测中正负样本比例严重失衡的问题
- 该损失函数降低了大量简单负样本在训练中所占的权重
RetinaNet
- Introduce
- Focal Loss
- CE(cross-entropy) loss
- Balanced CE loss
- Focal Loss
- Class imbalance and model initialization
- class imbalance and two stage detectors
- Retina Detector
- FPN
- Anchors
- Classification Subnet
- Box Regression Subnet
- Inference and Training
- Inference
- loss
- Initialization
- Optimization
- Experiments
- Pytorch
- Reference
Introduce
two stage (proposal-drived mechanism)
- the first stage
generates a sparse set of candidate object locations - the second stage
classifier each candidate location as one of the foreground classes or as background using conv1×1
one shot
- regular 、 dense sampling of object locations,scales and aspect ratio
- the main obstacle impeding one shot detector from achieving SOTA accuracy :
class imbalance during training
Focal Loss
The Focal Loss is designed to address the one-stage object detection scenario in which there is an extreme imbalance between foreground and background classes during training (e.g., 1:1000).
starting from the cross entropy (CE) loss for binary classification
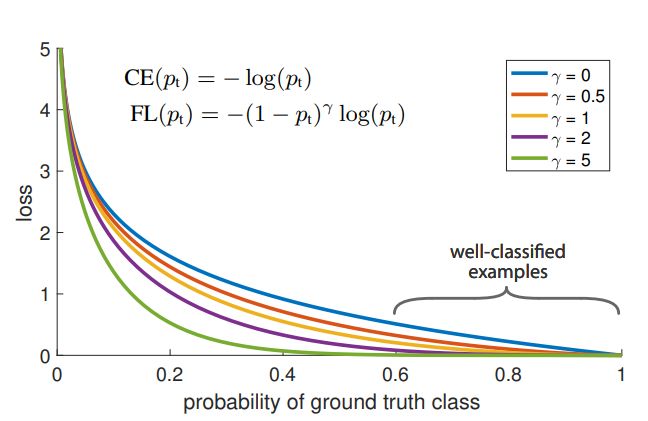
- CE
blue (top) curve- even examples that are easily classified ( p t ≥ 5 p_t≥5 pt≥5) incur a loss with non-trivial magnitude
When summed over a large number of easy examples, these small loss values can overwhelm the rare clss
- even examples that are easily classified ( p t ≥ 5 p_t≥5 pt≥5) incur a loss with non-trivial magnitude
CE(cross-entropy) loss
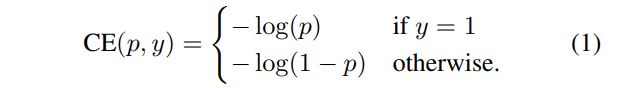
In the above y ∈ { ± 1 } y∈\{±1\} y∈{±1} pecifies the ground-truth class and $p∈ [0, 1] $ is the model’s estimated probability for the class with label y = 1. For notational convenience, we define p t p_t pt:
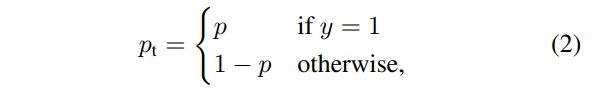
Balanced CE loss
类别不平衡问题导致对最终training loss的不利影响
我们会想到可通过在loss公式中使用与目标存在概率成反比的系数对其进行较正

Focal Loss
While α α α balances the importance of positive/negative examples, it does not differentiate between easy/hard examples.
use the focal loss on the output of the classification subnet
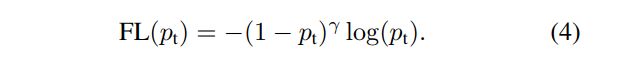
-
指数式系数可对正负样本对loss的贡献自动调节
当某样本类别比较easy,它对整体loss的贡献就比较少;而若某样本类别hard,则对整体loss的贡献就相对偏大 -
引入了一个新的 hyper parameter 即 γ γ γ
作者有试者对其进行调节,线性搜索后得出将 γ设为2 时,模型检测效果最好。

-
作者还引入了α系数,它能够使得focal loss对不同类别更加平衡
-
we note that the implementation of the loss layer combines the sigmoid operation for computing p with the loss computation,resulting in greater numerical stability
Class imbalance and model initialization
Binary classification models are by default initialized to have equal probability of outputting either y = − 1 y = −1 y=−1 or 1 1 1.
- Under such an initialization, in the presence of class imbalance, the loss due to the frequent class can dominate total loss and cause instability in early training.
To counter this
-
we introduce the concept of a ‘prior’ for the value of p estimated by the model for the rare class (foreground) at the start of training.
-
denote the prior by π and set it so that the model’s estimated p for examples of the rare class is low,e.g. 0.01.
-
improve training stability for both the cross entropy and
focal loss in the case of heavy class imbalance
class imbalance and two stage detectors
two stage 交叉熵的损失没有使用 α-balancing 和我们提出的focal loss
two stage 解决class imbalance :
- a two-stage cascade
- biased minibatch sampling
sampling 正负样本1:3 其实就是一张隐式 α-balancing 的实现
Retina Detector
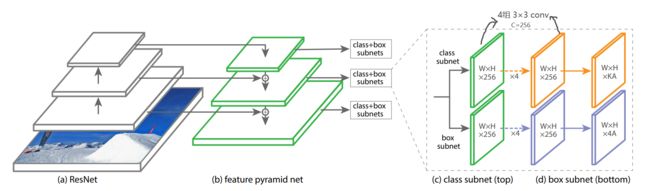
FPN
-
在 ResNet 上构建 FPN,构建一个从 P 3 P_3 P3 到 P 7 P_7 P7 的金字塔
P l P_l Pl 分辨率比输入低 2 l 2_l 2l , 所有 C = 256 C=256 C=256 channels -
original FPN

-
differs slightly from FPN
- not use P 2 P2 P2
(computational reasons) - P 6 P6 P6 is computed by strided conv instead of downsampling
- include P 7 P7 P7
(to improve large object detection)
- not use P 2 P2 P2
Anchors
The anchors have areas of 3 2 2 32^2 322 to 51 2 2 512^2 5122 on pyramid levels P 3 P3 P3 to P 7 P7 P7
at each pyramid level we use anchors at three aspect ratios { 1 : 2 , 1 : 1 , 2 : 1 } \{1:2, 1:1, 2:1\} {1:2,1:1,2:1}.
at each level we add anchors of sizes { 2 0 , 2 1 / 3 , 2 2 / 3 } \{2^0 , 2^{1/3} , 2^{2/3}\} {20,21/3,22/3} of the original set of 3 aspect ratio anchors (improve AP)
In total
-
A = 9 A=9 A=9 anchors per level
( cover the sacle range 32 - 813 pixels with respect to the network’s input image) -
eack anchor is assigned
-
a length K K K one-hot vector of classification targets
K K K is number of object classes -
4 − v e c t o r 4-vector 4−vector of box regression targets
-
-
use the assignment rule from RPN but modified for multi-class detection and with adjusted thresholds
- positive anchors are assigned to ground-truth object boxes
I o U ≥ 0.5 IoU≥0.5 IoU≥0.5
set the corresponding entry in its length K label vector to 1 and all other entries to 0
Box回归目标被计算为每个锚点与其分配的对象框之间的偏移量 - negative anchors are assigned to background
I o U ∈ [ 0 , 0.4 ) IoU∈ [0, 0.4) IoU∈[0,0.4) - ignore anchors
I o U ∈ [ 0.4 , 0.5 ) IoU∈[0.4,0.5) IoU∈[0.4,0.5)
- positive anchors are assigned to ground-truth object boxes
-
分别使用了两个FCN子网络(它们有着相同的网络结构却各自独立,并不share参数)用来完成目标框类别分类与位置回归任务
Classification Subnet
predict the probability of object presence at each spatial position for each of the A A A anchor and K K K object classes
- is a small FCN attached to each FPN level
parameters of this subnet are shared across all pyramid levels

- 4 * ( conv3×3 c=256 , ReLU)
- 1 * ( conv3×3 c=KA , ReLU)
- sigmoid activations
output the KA binary predictions per spatial location
特点
- uses only 3×3 conv
- our object classification subnet is deeper
- does not share parameters with the box regression subnet
Box Regression Subnet
网络和Classification Subnet相同 ,除了最后 输出为 W × H × 4 K W×H×4K W×H×4K
-
这四个输出预测锚和groundtruth框之间的相对偏移量
-
使用了一个类不可知的边界框回归器,使用更少的参数,与 Box Regression Subnet 不共享参数
Inference and Training
Inference
- only decode box predictions from at most 1k top-scoring predictions per FPN level
threshold I o U ≥ 0.05 IoU ≥ 0.05 IoU≥0.05 - the final detections
- The top predictions from all levels are merged
- NMS threshold I o U ≥ 0.5 IoU ≥ 0.5 IoU≥0.5
loss
loss = focalloss(分类) + smooth L1 loss ( 回归loss和faster-rcnn一样 )
-
focalloss
- The total focal loss of an image is computed as the sum of the focal loss over all ∼100k anchors, normalized by the number of anchors assigned to a ground-truth box
- γ = 2, α = 0.25 works best
Initialization
-
pre-trained on ImageNet1k
-
All new conv layers except the final one in the RetinaNet subnets are initialized with bias b = 0 and a Gaussian weight fill with σ = 0.01.
-
For the final conv layer of the classification subnet
- bias initialization to b = − log((1 − π)/π)
π specifies that at the start of training every anchor should be labeled as foreground with confidence of ∼π. We use π = .01 in all experiments, although results are robust to the exact value.
- bias initialization to b = − log((1 − π)/π)
Optimization
- SGD
- batch 16
- initial lr 0.01 ,在60k,80k分别÷10
Experiments
Pytorch
# fp16 settings
fp16 = dict(loss_scale=512.)
# model settings
model = dict(
type='RetinaNet',
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs=True,
num_outs=5),
bbox_head=dict(
type='RetinaHead',
num_classes=81,
in_channels=256,
stacked_convs=4,
feat_channels=256,
octave_base_scale=4,
scales_per_octave=3,
anchor_ratios=[0.5, 1.0, 2.0],
anchor_strides=[8, 16, 32, 64, 128],
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0],
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=0.11, loss_weight=1.0)))
# training and testing settings
train_cfg = dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.4,
min_pos_iou=0,
ignore_iof_thr=-1),
allowed_border=-1,
pos_weight=-1,
debug=False)
test_cfg = dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_thr=0.5),
max_per_img=100)
RetinaNet(
(backbone): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
)
(neck): FPN(
(lateral_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1): ConvModule(
(conv): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
)
(2): ConvModule(
(conv): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(fpn_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(2): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(3): ConvModule(
(conv): Conv2d(2048, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
(4): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
)
)
(bbox_head): RetinaHead(
(loss_cls): FocalLoss()
(loss_bbox): SmoothL1Loss()
(relu): ReLU(inplace)
(cls_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(activate): ReLU(inplace)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(activate): ReLU(inplace)
)
(2): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(activate): ReLU(inplace)
)
(3): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(activate): ReLU(inplace)
)
)
(reg_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(activate): ReLU(inplace)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(activate): ReLU(inplace)
)
(2): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(activate): ReLU(inplace)
)
(3): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(activate): ReLU(inplace)
)
)
(retina_cls): Conv2d(256, 180, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(retina_reg): Conv2d(256, 36, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
Reference
https://www.jianshu.com/p/8e501a159b28
https://github.com/open-mmlab/mmdetection/blob/b287273c11166f0fc11cd3318d1711550d925587/mmdet/models/detectors/single_stage.py