【Java并发编程】2.常用线程的并发工具类
文章目录
- ForkJoin
- 1.Fork/Join流程:
- 2. 工作窃取模式
- 3. demo演示
- 核心组件
- ForkJoinPool
- ForkJoinTask
- ForkJoinWorkerThread
- WorkQueue
- CountDownLatch
- CyclicBarrier
- Semaphore
- Exchange
- Callable,Future,FutureTask
- 参考

ForkJoin
1.Fork/Join流程:
ForkJoin是一种分治的思想,在1.7中引入JDK中。现实生活中的快排,队排,MapReduce都是思想的 实现,意思是在必要的情况下,将一个大任务,进行拆分(fork) 成若干个子任务(拆到不能再拆,这里就是指我们制定的拆分的临界值),再将一个个小任务的结果进行join汇总。
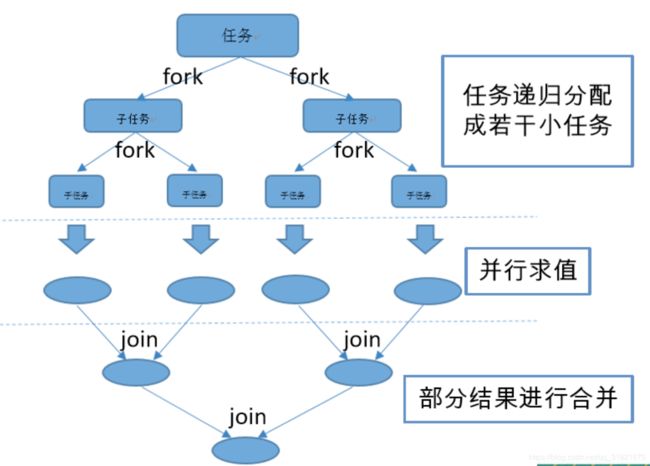
2. 工作窃取模式
从上述Fork/Join框架的描述可以看出,我们需要一些线程来执行Fork出的任务,在实际中,如果每次都创建新的线程执行任务,对系统资源的开销会很大,所以Fork/Join框架利用了线程池来调度任务。
另外,这里可以思考一个问题,既然由线程池调度,根据我们之前学习普通/计划线程池的经验,必然存在两个要素:
工作线程
任务队列
一般的线程池只有一个任务队列,但是对于Fork/Join框架来说,由于Fork出的各个子任务其实是平行关系,为了提高效率,减少线程竞争,应该将这些平行的任务放到中去,如上不同的队列图中,大任务分解成三个子任务:子任务1、子任务2,那么就创建两个任务队列,然后再创建3个工作线程与队列一一对应。
那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
满足这一需求的任务队列其实就是JUC框架中介绍过的双端阻塞队列 LinkedBlockingDeque。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。并且在进行RR跟上下文切换也会耗时的,所以不一定是多线程就一定 比单线程速度快。弹性而定,看任务量。
3. demo演示
ForkJoin有两种继承方式,RecursiveTask有返回值,RecursiveAction无返回值
任务需求:假设有个非常大的long[]数组,通过FJ框架求解数组所有元素的和。
任务类定义,因为需要返回结果,所以继承RecursiveTask,并覆写compute方法。任务的fork通过ForkJoinTask的fork方法执行,join方法方法用于等待任务执行后返回:
public class ForkJoinWork extends RecursiveTask<Long> {
private Long start;//起始值
private Long end;//结束值
public static final Long critical = 100000L;//临界值
public ForkJoinWork(Long start, Long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// return null;
//判断是否是拆分完毕
Long lenth = end - start; //起始值差值
if (lenth <= critical) {
//如果拆分完毕就相加
Long sum = 0L;
for (Long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
//没有拆分完毕就开始拆分
Long middle = (end + start) / 2;//计算的两个值的中间值
ForkJoinWork right = new ForkJoinWork(start, middle);
right.fork();//拆分,并压入线程队列
ForkJoinWork left = new ForkJoinWork(middle + 1, end);
left.fork();//拆分,并压入线程队列
//合并
return right.join() + left.join();
}
}
}
测试:
public class ForkJoinWorkTest {
@Test
public void test() {
//ForkJoin实现
long l = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();//实现ForkJoin 就必须有ForkJoinPool的支持
ForkJoinTask<Long> task = new ForkJoinWork(0L, 10000000000L);//参数为起始值与结束值
Long invoke = forkJoinPool.invoke(task);
long l1 = System.currentTimeMillis();
System.out.println("invoke = " + invoke + " time: " + (l1 - l));
//invoke = -5340232216128654848 time: 56418
//ForkJoinWork forkJoinWork = new ForkJoinWork(0L, 10000000000L);
}
@Test
public void test2() {
//普通线程实现
Long x = 0L;
Long y = 10000000000L;
long l = System.currentTimeMillis();
for (Long i = 0L; i <= y; i++) {
x += i;
}
long l1 = System.currentTimeMillis();
System.out.println("invoke = " + x + " time: " + (l1 - l));
//invoke = -5340232216128654848 time: 64069
}
@Test
public void test3() {
//Java 8 并行流的实现
long l = System.currentTimeMillis();
long reduce = LongStream.rangeClosed(0, 10000000000L).parallel().reduce(0, Long::sum);
long l1 = System.currentTimeMillis();
System.out.println("invoke = " + reduce + " time: " + (l1 - l));
//invoke = -5340232216128654848 time: 2152
}
}
结论:Java 8 就为我们提供了一个并行流来实现ForkJoin实现的功能。可以看到并行流比自己实现ForkJoin还要快。
Java 8 中将并行流进行了优化,我们可以很容易的对数据进行并行流的操作,Stream API可以声明性的通过parallel()与sequential()在并行流与串行流中随意切换!
核心组件
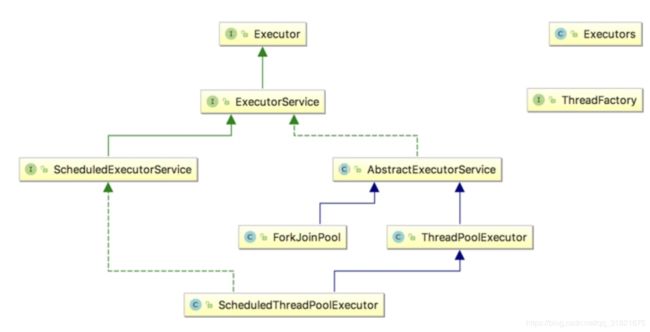
F/J框架的实现非常复杂,内部大量运用了位操作和无锁算法,撇开这些实现细节不谈,该框架主要涉及三大核心组件:ForkJoinPool(线程池)、ForkJoinTask(任务)、ForkJoinWorkerThread(工作线程),外加WorkQueue(任务队列):
- ForkJoinPool:ExecutorService的实现类,负责工作线程的管理、任务队列的维护,以及控制整个任务调度流程;
- ForkJoinTask:Future接口的实现类,fork是其核心方法,用于分解任务并异步执行;而join方法在任务结果计算完毕之后才会运行,用来合并或返回计算结果;
- ForkJoinWorkerThread:Thread的子类,作为线程池中的工作线程(Worker)执行任务;
- WorkQueue:任务队列,用于保存任务;
ForkJoinPool
ForkJoinPool作为Executors框架的一员,从外部看与其它线程池并没有什么区别,仅仅是ExecutorService的一个实现类:
ForkJoinPool的主要工作如下:
- 接受外部任务的提交(外部调用ForkJoinPool的invoke/execute/submit方法提交任务);
- 接受ForkJoinTask自身fork出的子任务的提交;
- 任务队列数组(WorkQueue[])的初始化和管理;
工作线程(Worker)的创建/管理。
注意:ForkJoinPool提供了3类外部提交任务的方法:invoke、execute、submit,它们的主要区别在于任务的执行方式上。
- 通过invoke方法提交的任务,调用线程直到任务执行完成才会返回,也就是说这是一个同步方法,且有返回结果;
- 通过execute方法提交的任务,调用线程会立即返回,也就是说这是一个异步方法,且没有返回结果;
- 通过submit方法提交的任务,调用线程会立即返回,也就是说这是一个=异步=方法,且有==返回结果(返回Future实现类,可以通过get获取结果)。
注意:ForkJoinPool支持两种模式:
同步模式(默认方式)
异步模式
这里的同步/异步并不是指F/J框架本身是采用同步模式还是采用异步模式工作,而是指其中的工作线程的工作方式。在F/J框架中,每个工作线程(Worker)都有一个属于自己的任务队列(WorkQueue),这是一个底层采用数组实现的双向队列。
同步是指:对于工作线程(Worker)自身队列中的任务,采用后进先出(LIFO)的方式执行;异步是指:对于工作线程(Worker)自身队列中的任务,采用先进先出(FIFO)的方式执行
ForkJoinTask
从Fork/Join框架的描述上来看,“任务”必须要满足一定的条件:
支持Fork,即任务自身的分解
支持Join,即任务结果的合并
因此,J.U.C提供了一个抽象类——ForkJoinTask,来作为该类Fork/Join任务的抽象定义
ForkJoinTask实现了Future接口,是一个异步任务,我们在使用Fork/Join框架时,一般需要使用线程池来调度任务,线程池内部调度的其实都是ForkJoinTask任务(即使提交的是一个Runnable或Callable任务,也会被适配成ForkJoinTask)。
除了ForkJoinTask,Fork/Join框架还提供了两个它的抽象实现,我们在自定义ForkJoin任务时,一般继承这两个类:
RecursiveAction:表示具有返回结果的ForkJoin任务
RecursiveTask:表示没有返回结果的ForkJoin任务
ForkJoinWorkerThread
Fork/Join框架中,每个工作线程(Worker)都有一个自己的任务队列(WorkerQueue), 所以需要对一般的Thread做些特性化处理,J.U.C提供了ForkJoinWorkerThread类作为ForkJoinPool中的工作线程:
public class ForkJoinWorkerThread extends Thread {
final ForkJoinPool pool; // 该工作线程归属的线程池
final ForkJoinPool.WorkQueue workQueue; // 对应的任务队列
protected ForkJoinWorkerThread(ForkJoinPool pool) {
super("aForkJoinWorkerThread"); // 指定工作线程名称
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
// ...
}
ForkJoinWorkerThread 在构造过程中,会。同时,它会通过ForkJoinPool的registerWorker方保存所属线程池信息和与自己绑定的任务队列信息法将自己注册到线程池中。
WorkQueue
任务队列(WorkQueue)是ForkJoinPool与其它线程池区别最大的地方,在ForkJoinPool内部,维护着一个WorkQueue[]数组,它会在外部首次提交任务)时进行初始化:
volatile WorkQueue[] workQueues; // main registry
当通过线程池的外部方法(submit、invoke、execute)提交任务时,如果WorkQueue[]没有初始化,则会进行初始化;然后根据数组大小和线程随机数(ThreadLocalRandom.probe)等信息,计算出任务队列所在的数组索引(这个索引一定是偶数),如果索引处没有任务队列,则初始化一个,再将任务入队。也就是说,通过外部方法提交的任务一定是在偶数队列,没有绑定工作线程。
WorkQueue作为ForkJoinPool的内部类,表示一个双端队列双端队列,既可以作为栈使用(LIFO),也可以作为队列使用(FIFO)。ForkJoinPool的“工作窃取”正是利用了这个特点,当工作线程从自己的队列中获取任务时,默认总是以栈操作(LIFO)的方式从栈顶取任务;当工作线程尝试窃取其它任务队列中的任务时,则是FIFO的方式。
线程池中的每个工作线程(ForkJoinWorkerThread)都有一个自己的任务队列(WorkQueue),工作线程优先处理自身队列中的任务(LIFO或FIFO顺序,由线程池构造时的参数 mode 决定),自身队列为空时,以FIFO的顺序随机窃取其它队列中的任务。
F/J框架的核心来自于它的工作窃取及调度策略,可以总结为以下几点:
- 每个Worker线程利用它自己的任务队列维护可执行任务;
- 任务队列是一种双端队列,支持LIFO的push和pop操作,也支持FIFO的take操作;
- 任务fork的子任务,只会push到它所在线程(调用fork方法的线程)的队列;
- 工作线程既可以使用LIFO通过pop处理自己队列中的任务,也可以FIFO通过poll处理自己队列中的任务,具体取决于构造线程池时的asyncMode参数;
- 当工作线程自己队列中没有待处理任务时,它尝试去随机读取(窃取)其它任务队列的base端的任务;
- 当线程进入join操作,它也会去处理其它工作线程的队列中的任务(自己的已经处理完了),直到目标任务完成(通过isDone方法);
- 当一个工作线程没有任务了,并且尝试从其它队列窃取也失败了,它让出资源(通过使用yields, sleeps或者其它优先级调整)并且随后会再次激活,直到所有工作线程都空闲了——此时,它们都阻塞在等待另一个顶层线程的调用。
CountDownLatch
CountDownLatch是一个非常实用的多线程控制工具类,可以简单联想到下课倒计时一起开饭,百米赛跑一起跑。常用的就下面几个方法:
CountDownLatch(int count) //实例化一个倒计数器,count指定计数个数
countDown() // 计数减一
await() //等待,当计数减到0时,所有线程并行执行
CountDownLatch在我们工作的多个场景被使用,算是用的很频繁的了,比如我们的API接口响应时间被要求在200ms以内,但是如果一个接口内部依赖多个三方/外部服务,那串行调用接口的RT必然很久,所以个人用的最多的是接口RT优化场景,内部服务并行调用。
对于倒计数器,一种典型的场景就是火箭发射。在火箭发射前,为了保证万无一失,往往还要进行各项设备、仪器的检测。只有等到所有的检查完毕后,引擎才能点火。那么在检测环节当然是多个检测项可以的。同时进行代码:
/**
* @Description: 倒计时器示例:火箭发射
*/
public class CountDownLatchDemo implements Runnable{
static final CountDownLatch latch = new CountDownLatch(10);
static final CountDownLatchDemo demo = new CountDownLatchDemo();
@Override
public void run() {
// 模拟检查任务
try {
Thread.sleep(new Random().nextInt(10) * 1000);
System.out.println("检查完毕");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//计数减一
//放在finally避免任务执行过程出现异常,导致countDown()不能被执行
latch.countDown();
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService exec = Executors.newFixedThreadPool(10);
for (int i=0; i<10; i++){
exec.submit(demo);
}
// 等待检查
latch.await(); // 外部主线程main 方法来等待下面运行!!!
// 发射火箭
System.out.println("Fire!");
// 关闭线程池
exec.shutdown();
}
}
上述代码中我们先生成了一个CountDownLatch实例。计数数量为10,这表示需要有10个线程来完成任务,等待在CountDownLatch上的线程才能继续执行。latch.countDown(); 方法作用是通知CountDownLatch有一个线程已经准备完毕,倒计数器可以减一了。atch.await()方法要求主线程等待所有10个检查任务全部准备好才一起并行执行。
latch.countDown()的调用不一定非要开启线程执行,即使你在主线程中下面这样写效果也是一样。
for (int i = 0; i < 10; i++) {
countDownLatch.countDown();
}
CyclicBarrier
这个类的中文意思是循环栅栏。大概的意思就是一个可循环利用的屏障。
它的作用就是会让所有线程都等待完成后才会继续下一步行动。
举个例子,就像生活中我们会约朋友们到某个餐厅一起吃饭,有些朋友可能会早到,有些朋友可能会晚到,但是这个餐厅规定必须等到所有人到齐之后才会让我们进去。这里的朋友们就是各个线程,餐厅就是 CyclicBarrier。
构造方法
public CyclicBarrier(int parties)
public CyclicBarrier(int parties, Runnable barrierAction)
parties 是参与线程的个数
第二个构造方法有一个 Runnable 参数,这个参数的意思是到达线程最后一个要做的任务
重要方法:
public int await() throws InterruptedException, BrokenBarrierException
public int await(long timeout, TimeUnit unit) throws InterruptedException, BrokenBarrierException, TimeoutException
线程调用 await() 表示自己已经到达栅栏
BrokenBarrierException 表示栅栏已经被破坏,破坏的原因可能是其中一个线程 await() 时被中断或者超时
demo:一个线程组的线程需要等待所有线程完成任务后再继续执行下一次任务
public class CyclicBarrierTest {
public static void main(String[] args) {
//定义一个计数器,当计数器的值累加到30,输出"放行"
CyclicBarrier cyclicBarrier = new CyclicBarrier(30,()->{
System.out.println("放行");
});
for (int i = 1; i <= 90; i++) {
final int temp = i;
new Thread(()->{
System.out.println("-->"+temp);
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
}
}
}
上面的结果会出现3次放行哦。
CyclicBarrier 与 CountDownLatch 区别
CountDownLatch 是一次性的,CyclicBarrier 是可循环利用的
CountDownLatch 参与的线程的职责是不一样的,有的在倒计时,有的在等待倒计时结束。CyclicBarrier 参与的线程职责是一样的。
CountDownLatch 做减法计算,count=0,唤醒阻塞线程,CyclicBarrier 做加法计算,count=屏障值(parties),唤醒阻塞线程。
最重要:CountDownLatch的放行由第三者控制,CyclicBarrier是由一组线程本身来控制的, CountDownLatch放行条件>=线程数。CyclicBarrier放行条件=线程数。
Semaphore
用途:控制同时访问某个特定资源的线程数据,用来流量控制。
一个超市只能容纳5个人购物,其余人排队。
public class SemaphoreTest {
public static void main(String[] args) {
//同时只能进5个人
Semaphore semaphore = new Semaphore(5);
for (int i = 0; i < 15; i++) {
new Thread(() -> {
try {
//获得许可
semaphore.acquire(); // 已经进店人+1
System.out.println(Thread.currentThread().getName() + "进店购物");
TimeUnit.SECONDS.sleep(5);
System.out.println(Thread.currentThread().getName() + "出店");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//释放许可
semaphore.release(); //已经进店人 -1
}
}, String.valueOf(i)).start();
}
}
}
实现数据库连接池
数据库连接实现:
public class SqlConnectImpl implements Connection{
/*拿一个数据库连接*/
public static final Connection fetchConnection(){
return new SqlConnectImpl();
}
}
连接池的实现:
public class DBPoolSemaphore {
private final static int POOL_SIZE = 10;
private final Semaphore useful, useless;//useful表示可用的数据库连接,useless表示已用的数据库连接
public DBPoolSemaphore() {
this.useful = new Semaphore(POOL_SIZE);
this.useless = new Semaphore(0);
}
//存放数据库连接的容器
private static LinkedList<Connection> pool = new LinkedList<Connection>();
//初始化池
static {
for (int i = 0; i < POOL_SIZE; i++) {
pool.addLast(SqlConnectImpl.fetchConnection());
}
}
/*归还连接*/
public void returnConnect(Connection connection) throws InterruptedException {
if (connection != null) {
System.out.println("当前有" + useful.getQueueLength() + "个线程等待数据库连接!!"
+ "可用连接数:" + useful.availablePermits());
useless.acquire();// 可用连接 +1
synchronized (pool) {
pool.addLast(connection);
}
useful.release(); // 已用连接 -1
}
}
/*从池子拿连接*/
public Connection takeConnect() throws InterruptedException {
useful.acquire(); // 可用连接-1
Connection conn;
synchronized (pool) {
conn = pool.removeFirst();
}
useless.release(); // 以用连接+1
return conn;
}
}
测试代码:
public class AppTest {
private static DBPoolSemaphore dbPool = new DBPoolSemaphore();
//业务线程
private static class BusiThread extends Thread {
@Override
public void run() {
Random r = new Random();//让每个线程持有连接的时间不一样
long start = System.currentTimeMillis();
try {
Connection connect = dbPool.takeConnect();
System.out.println("Thread_" + Thread.currentThread().getId()
+ "_获取数据库连接共耗时【" + (System.currentTimeMillis() - start) + "】ms.");
SleepTools.ms(100 + r.nextInt(100));//模拟业务操作,线程持有连接查询数据
System.out.println("查询数据完成,归还连接!");
dbPool.returnConnect(connect);
} catch (InterruptedException e) {
}
}
}
public static void main(String[] args) {
for (int i = 0; i < 50; i++) {
Thread thread = new BusiThread();
thread.start();
}
}
}
Exchange
两个线程间的数据交换,局限性比较大。Exchange是 阻塞形式的,两个线程要都到达执行Exchange函数才会交换。
public class UseExchange {
private static final Exchanger<Set<String>> exchange
= new Exchanger<Set<String>>();
public static void main(String[] args) {
//第一个线程
new Thread(new Runnable() {
@Override
public void run() {
Set<String> setA = new HashSet<String>();//存放数据的容器
try {
setA.add("liu");
setA.add("Liu");
setA.add("LIU");
setA = exchange.exchange(setA);//交换set
/*处理交换后的数据*/
} catch (InterruptedException e) {
}
}
}).start();
//第二个线程
new Thread(new Runnable() {
@Override
public void run() {
Set<String> setB = new HashSet<String>();//存放数据的容器
try {
setB.add("jin");
setB.add("Jie");
setB.add("JIN");
setB = exchange.exchange(setB);//交换set
/*处理交换后的数据*/
} catch (InterruptedException e) {
}
}
}).start();
}
}
Callable,Future,FutureTask
这三个组合使用,一般我们可以将耗时任务用子线程去执行,同时执行我们自己的主线程任务。主线程执行任务完毕后再调Future.get()来获得子线程任务。
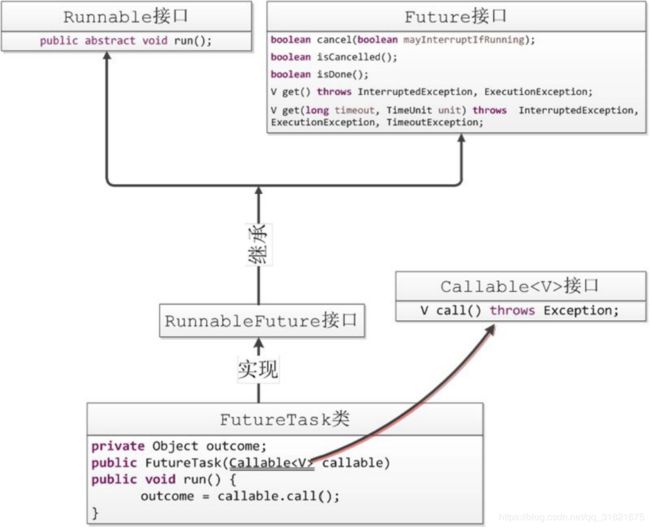
说明:
Callable有返回值可抛出异常,其中返回值有Future获得。
Future 获得返回值。
FutureTask实现Future跟Runnable。1.7前用AQS实现的,1.8以后不再是。
Future主要函数功能:
- isDone,结束,正常还是异常结束,或者自己取消,都返回true;
- isCancelled 任务完成前被取消,返回true;
- cancel(boolean):
- 任务还没开始,返回false
- 任务已经启动,cancel(true)
- 中断正在运行的任务,中断成功,返回true
- cancel(false),不会去中断已经运行的任务
- 任务已经结束,返回false
demo:
public class UseFuture {
/*实现Callable接口,允许有返回值*/
private static class UseCallable implements Callable<Integer> {
private int sum;
@Override
public Integer call() throws Exception {
System.out.println("Callable子线程开始计算");
Thread.sleep(2000);
for (int i = 0; i < 5000; i++) {
sum = sum + i;
}
System.out.println("Callable子线程计算完成,结果=" + sum);
return sum;
}
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
UseCallable useCallable = new UseCallable();
FutureTask<Integer> futureTask = new FutureTask<Integer>(useCallable);
new Thread(futureTask).start();
Random r = new Random();
SleepTools.second(1);
if (r.nextBoolean()) { // 方法调用返回下一个伪均匀分布的boolean值
System.out.println("Get UseCallable result = " + futureTask.get());
} else {
System.out.println("中断计算");
futureTask.cancel(true);
}
}
}

参考
F/J