虚拟机搭建单机版Hadoop教程(惨痛经历)
虚拟机搭建Hadoop教程(惨痛经历)
- 目录
- 1. JDK环境
- 2. 防火墙和SELinux关闭
- 3. ssh免密登录配置(多台服务器一样的配置)
- 3.1 设置主机名
- 3.2 配置hosts
- 3.3 配置sshd
- 3.4 配置密钥
- 3.4.1 创建免密账户
- 3.4.1 生成公私钥(root和新账户都需要)
- 4. Hadoop配置
- 4.1 配置文件配置
- 4.2 环境变量配置
- 5. 问题集锦
- 5.1 ATTEMPTING TO OPERATE ON HDFS NAMENODE AS ROOT(start-all.sh)
- 5.2 Cannot execute /home/hadoop/hadoop/libexec/hadoop-config.sh.
- 需要多注意一下报错的内容是什么,多注意发现一下报错的是不是配置文件的某个配置写错了,细心尝试,多查问题,总会有结果
- 6. 思考
目录
说来惭愧,搭建了一天,遇到了各种问题,最终好歹实现了,现在记录一下整个搭建过程,也算是一点点收获了。
最后,希望以后的自己每天都开心啦。
1. JDK环境
首先搭建好jdk1.8环境,hadoop的配置中需要用到的,这个就不多说了,给个下载地址咯:
jdk1.8下载地址
2. 防火墙和SELinux关闭
1、Redhat使用了SELinux来增强安全,关闭方法:
修改 /etc/selinux/config 文件中的 SELINUX=enforcing 修改为 SELINUX=disabled
2、防火墙关闭命令
#停止防火墙
systemctl stop firewalld.service
#禁止防火墙开机启动
systemctl stop firewalld.service
3. ssh免密登录配置(多台服务器一样的配置)
3.1 设置主机名
编辑 /etc/sysconfig/network 文件,使用命令:
vim /etc/sysconfig/network
将A服务器的主机名设置为 server1。
NETWORKING=yes
HOSTNAME=server1
3.2 配置hosts
编辑/etc/hosts文件,使用命令:
vim /etc/hosts
添加上自己的服务器配置
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.127.14 server1
3.3 配置sshd
编辑两台服务器的 /etc/ssh/sshd_config (注意不是/etc/ssh/ssh_config) 文件,使用命令:
vim /etc/ssh/sshd_config
在文件中看看是否有下面的配置,有"#"则注释,没有则新加:
PermitRootLogin yes
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
重启sshd服务,使用命令:
/sbin/service sshd restart
3.4 配置密钥
3.4.1 创建免密账户
新增用户并设置密码
useradd testadmin
passwd testadmin
3.4.1 生成公私钥(root和新账户都需要)
用户切换使用:
su root
su testadmin
切换完用户,开始生成密钥,输入完命令直接回车即可,命令如下:
ssh-keygen -t rsa
生成密钥后,root用户的公私钥路径是:~/.ssh,其他用户的公私钥路径是:/home/testadmin/.ssh

然后,将公钥导入到认证文件,使用命令:
cat id_dsa.pub >> authorized_keys
最后,设置文件访问权限,使用命令:
chmod 700 /home/testadmin/.ssh
chmod 600 /home/testadmin/.ssh/authorized_keys
配置成功后,可以使用不同用户先测试一下,使用命令:
ssh localhost
最终测试成功,将认证文件复制到其他机器,即可ssh免密登录。
4. Hadoop配置
Hadoop下载可直接去官网进行下载,下载到压缩包,解压即可,下面直接上手Hadoop的配置:
先进入Hadoop安装路径:
然后,进入etc/hadoop目录,进行配置文件的配置。
4.1 配置文件配置
4.1配置hdfs-site.xml文件,命令如下:
dfs.reolication</name>
1</value>
</property>
dfs.namenode.name.dir</name>
file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
dfs.datanode.data.dir</name>
file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置core-site.xml文件,命令如下:
fs.defaultFS</name>
hdfs://localhost:9000</value>
</property>
hadoop.tmp.dir</name>
file:/usr/local/hadoop/tmp</value>
Abase for other temporary directories.</description>
</property>
</configuration>
配置hadoop-env.sh文件,命令如下:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64
export HADOOP_HOME=/usr/local/hadoop-3.2.1
配置mapred-site.xml文件,命令如下:
mapreduce.framework.name</name>
yarn</value>
</property>
</configuration>
配置yarn-site.xml文件,命令如下:
yarn.nodemanager.aus-services</name>
mapreduce_shuffle</value>
</property>
</configuration>
最后执行命令进行格式化:
hadoop namenode -format
4.2 环境变量配置
输出命令:
vim /etc/profile
然后进行如下配置:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64
export HADOOP_HOME=/usr/local/hadoop-3.2.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后输入命令使配置生效:
source /etc/profile
最后到Hadoop的sbin目录下,执行start-all.sh即可(执行这个则一次将其他sh一起启动了):
./start-all.sh
然后执行以下jps,查看是不是都启动了:
jps
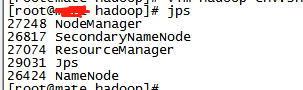
5. 问题集锦
5.1 ATTEMPTING TO OPERATE ON HDFS NAMENODE AS ROOT(start-all.sh)
解决方法:
需要在start-dfs.sh、stop-dfs.sh、start-yarn.sh和stop-yarn.sh这四个文件中新增配置:
start-dfs.sh和stop-dfs.sh文件:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh和stop-yarn.sh文件:
YARN_RESOURCEMANAGER_USER=root
YARN_DATANODE_SECURE_USER=yarn
YARN_NODEMANAGER_USER=root
5.2 Cannot execute /home/hadoop/hadoop/libexec/hadoop-config.sh.
解决方法:
删除/etc/profile中的HADOOP_HOME全局变量,然后执行命令:
source /etc/profile
最后在 ~/.bashrc最后一行添加unset HADOOP_HOME:
vim ~/.bashrc
unset HADOOP_HOME
需要多注意一下报错的内容是什么,多注意发现一下报错的是不是配置文件的某个配置写错了,细心尝试,多查问题,总会有结果
6. 思考
这是自己写的第一篇博客,因为呢觉得自己要是不记录下点什么,好像果断时间又忘了,又要去各种查资料,就会很浪费时间(主要是会鄙视自己很废物),虽然知道自己不是很喜欢这碗饭,但是呢,生活总要继续下去,也可以以这种方式来让这碗饭慢慢的变成自己的兴趣饭。哈哈,不知道未来的自己是什么样的,只要不断地在进步就行了,只要进步,未来的自己就会变得越来越好啦。嘻嘻