论文阅读笔记Saliency Detection with Recurrent Fully Convolutional Networks
摘要
深度网络已经被证明可以编码高级语义特征,并在显着性检测中提供卓越的性能。 在本文中,我们通过使用循环完全卷积网络(RFCN)开发新的显着性模型更进一步。此外,循环体系结构使我们的方法能够通过纠正其先前的错误自动学习优化显着性映射。 为了训练具有多个参数的这样的网络,我们提出了使用语义分割数据的预训练策略,其同时利用对分割任务的强有力的监督以进行更好的训练,并使网络能够捕获对象的通用表示以用于显著性检测。 通过广泛的实验评估,我们证明了所提出的方法优于最先进的方法,并且所提出的循环深度模型以及预训练方法可以显著提高性能。
1.简介
显着性检测一般可分为两个子类别:显着对象分割[12,38,16]和眼部注意点检测[26,7]。 本文主要关注显著对象分割,旨在突出图像中最引人注目和吸引眼球的对象区域。 它已被用作预处理步骤,以促进广泛的视觉应用,并越来越受到该领域的关注。 尽管取得了很大进展,但开发能够处理现实世界不利情景的有效算法仍然是一项非常具有挑战性的任务。
大多数现有方法通过手工制作的模型和启发式显着性先验来解决显着性检测问题。例如,对比度先验将显著性检测作为中心周围的对比度分析,并捕获突出的区域,这些区域要么以全局罕见为特征,要么在局部脱颖而出。

另外,边界先验将边界区域视为背景,并通过将背景信息传播到其余图像区域来检测前景对象。虽然这些显著性先验已被证明在某些情况下是有效的(图1第一行),但它们不足以发现复杂场景中的显着物体(图1第二行)。此外,基于显着性先验的方法主要依赖于低级手工制作的特征,这些特征无法捕获对象的语义概念。如图1的第三行所示,在某些情况下,高级语义信息在区分前景对象与具有相似外观的背景中起着重要作用。
最近,深度卷积神经网络(CNN)在许多视觉任务中实现了创纪录的性能,例如,图像分类[15,28],目标检测[5,27],目标跟踪[32,33],语义分割[22,21]等。现有方法表明深层CNN也可以有利于显著性检测,并且非常有效。通过准确识别语义上突出的对象来处理复杂场景(图1第三行)。虽然已经实现了更好的性能,但是现有的基于CNN的显着性检测方法仍然存在三个主要问题。首先,大多数基于CNN的方法完全抛弃了在以前的工作中有效的显着性先验。其次,CNN仅考虑局部图像块的有限尺寸来预测像素的显着性标签。它们大多不能强制执行空间一致性,并且可能不可避免地做出不正确的预测。但是,对于前馈架构,CNN很难完善输出预测。最后,显着性检测主要被公式化为二元分类问题,即前景或背景。与具有数千个类别的图像分类任务相比,二进制标签的监督相对较弱,无法有效地训练具有大量参数的深度CNN。
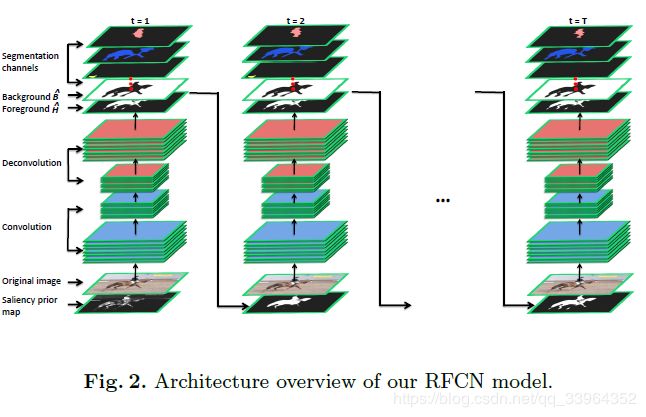
为了缓解上述问题,我们研究了用于显着性检测的循环全卷积网络(RFCN)。在每个时间步长中,我们通过RFCN向前馈送输入的RGB图像和显着性先验图,以获得预测显着图,该预测显着图又用作下一时间步中的显着性先前图。通过结合指示潜在显着区域的显着性先验来初始化第一时间步骤中的先验映射。我们的RFCN架构与现有的基于CNN的方法相比具有两个优势:a)利用显着性先验使训练深度模型更容易并且产生更准确的预测; b)与前馈网络相反,我们的RFCN网络的输出作为反馈信号提供,使得RFCN能够通过纠正其先前的错误来改进显着性预测,直到在最后时间步骤中产生最终预测。为了训练RFCN进行显着性检测,开发了一种新的预训练策略,该策略利用语义分割数据的丰富属性信息进行监督。图2演示了所提出的RFCN模型的架构概述。
总之,这项工作的贡献是三份。 首先,我们提出了一种使用循环完全卷积网络的显着性检测方法,该方法能够改进先前的预测。 其次,将显着性先验纳入网络以促进训练和推理。 第三,我们使用语义分割数据设计用于显着性检测的RFCN预训练方法,以利用来自多个对象类别的强监督并捕获通用对象的内在表示。 所提出的显着性检测方法产生更准确的显着性图,并且在四个基准数据集上具有相当大的优势,优于最先进的方法。
2.相关工作
现有的显着性检测方法可以主要分为两类,即手工制作的模型或基于学习的方法。大多数手工制作的方法可以追溯到特征整合理论[30],其中选择重要的视觉特征并将其组合以模拟视觉注意力。后来,Itti等人。 [8]建议通过颜色,强度和方向特征的中心 - 环绕对比度来测量显着性。谢等人。 [34]在贝叶斯框架中制定显着性检测,并通过似然概率估计视觉显着性。在[3]中,通过考虑用于显着性测量的图像像素的外观相似性和空间分布来开发软图像抽象。同时,背景优先也被许多手工制作的模型[36,10,38,6]常用,其中基本假设是图像边界区域更可能是背景。然后可以通过使用边界区域作为背景种子的标签传播来识别突出区域。
手工制作的显着性方法既高效又有效,但在处理复杂场景时却不够稳健。最近,基于学习的方法受到了社区的更多关注。这些方法可以通过在具有注释的图像数据上训练检测器(例如,随机森林[12,19],深度网络[31,37,17]等)来自动学习检测显着性。其中,基于深度网络的显着性模型表现出非常有竞争力的表现。例如,Wang等人。 [31]建议分别通过训练DNN-L和DNN-G网络进行局部估计和全局搜索来检测显着区域。在[16]中,通过采用周围区域的多尺度CNN特征,训练完全连接的网络以回归每个超像素的显着度。这两种方法进行逐片扫描以获得输入图像的显着图,计算代价很高。此外,他们直接训练显着性检测数据集的深层模型,忽略二元标签监管不力的问题。为了解决上述问题,Li等人。 [17]建议使用在多任务学习框架下训练的完全卷积网络(FCN)来检测显着性。虽然具有相似的精神,但我们的方法在三个方面与[17]有显着的不同。首先,显着性先验被用于网络训练和推理,在[17]中被忽略。其次,我们设计了一种能够改进生成的预测的循环体系结构,而不是[17]中的前馈体系结构。第三,我们的深度网络预训练方法允许使用分割数据学习特定于类的特征和通用对象表示。相比之下,[17]仅针对区分不同类别的对象的任务训练网络分割数据,这与显着对象检测的任务本质上不同。
递归神经网络(RNN)已应用于许多视觉任务[20,25]。我们方法中的循环体系结构主要用作纠正先前错误的细化机制。与强烈依赖上一步隐藏单元的现有RNN相比,RFCN仅将最后一步的最终输出作为先验。因此,它需要更少的步骤来收敛并且更容易训练。
3.循环网络的显着性预测
用于图像分类的传统CNN包括卷积层,接着是全连接层,其采用固定空间大小的图像作为输入,并产生指示输入图像的类别的标签矢量。 对于需要空间标签的任务,例如分割,深度预测等,一些方法以逐个补丁的扫描方式应用CNN进行密集预测。 然而,补丁之间的重叠导致冗余计算,因此显着增加了计算开销。 与现有方法不同,我们考虑完全卷积网络(FCN)架构[22]用于我们的循环模型,该模型生成具有相同输入图像大小的预测。 在3.1节中,我们正式引入了FCN网络进行显着性检测。第3.2节介绍了基于RFCN网络的显着性方法。 最后,我们将在3.3节中展示如何训练RFCN网络进行显着性检测。
3.1用于显著性目标检测的全卷积网络
作为CNN的构建块的卷积层是在平移不变的基础上定义的,并且具有跨不同空间位置的共享权重。 卷积层的输入和输出都是称为特征映射的3D张量,其中输出特征映射是通过将输入特征映射上的卷积核卷积为![]()
其中X是输入要素图; W和b分别表示内核和偏差; * s表示带有步幅的卷积运算。 结果,输出特征映射fs(X; W; b)的分辨率被下采样s。 通常,卷积层与最大池化层和非线性单元(例如,ReLU)交织,以进一步改善平移不变性和表示能力。 然后可以将最后一个卷积层的输出特征映射馈送到完全连接的层的堆栈中,这些层丢弃输入的空间坐标并为输入图像生成全局标签(参见图3(a))。
对于有效的密集推理,[22]将CNN转换为全卷积网络(FCN)(图3(b)),将全连接层转换为卷积层,其中内核覆盖整个输入区域。 这允许网络获取任意大小的输入图像并通过一次前向传递产生空间输出。 然而,由于卷积和池化层的步幅,最终输出特征图仍然是粗略的,并且从输入图像下采样一个网络总步幅的因子。 为了将粗糙特征图映射到输入图像的按像素预测,FCN通过一堆反卷积层对粗糙图进行上采样(图3(c))

其中I代表输入图像; FS(![]() ·;)表示由FCN的卷积层生成的输出特征映射,其总步幅为S,并由
·;)表示由FCN的卷积层生成的输出特征映射,其总步幅为S,并由 参数化; US(·;
参数化; US(·; )表示通过参数化的FCN网络的反卷积层,其通过因子S对输入进行上采样以确保输出预测的
)表示通过参数化的FCN网络的反卷积层,其通过因子S对输入进行上采样以确保输出预测的 和输入图像I相同空间大小。不同于简单的双线性插值,反卷层的参数是联合学习的。为了探索输入图像的精细尺度的局部外观,跳过架构[22]也可用于组合下卷积层和最终卷积层的输出特征图,以进行更准确的推断。
和输入图像I相同空间大小。不同于简单的双线性插值,反卷层的参数是联合学习的。为了探索输入图像的精细尺度的局部外观,跳过架构[22]也可用于组合下卷积层和最终卷积层的输出特征图,以进行更准确的推断。

在显着性检测的背景下,我们感兴趣的是测量图像中每个像素的显着性程度。为此,FCN采用大小为h的RGB图像大小为h×w × 3作为输入并生成大小为h×w×2的输出特征映射= US(FS(I;);)。我们将的两个输出通道表示为背景图![]() 和显着前景图
和显着前景图![]() ,分别表示所有像素的背景和前景的得分。通过应用softmax函数,将这两个分数转换为前景概率
,分别表示所有像素的背景和前景的得分。通过应用softmax函数,将这两个分数转换为前景概率

![]() 表示由(i; j)索引的像素的前景/背景标签。 背景概率p(
表示由(i; j)索引的像素的前景/背景标签。 背景概率p(![]() = bg|,)可以以类似的方式计算。 给定包含训练图像I及其像素显着注释C的训练集{Z=(I,C)}
= bg|,)可以以类似的方式计算。 给定包含训练图像I及其像素显着注释C的训练集{Z=(I,C)}![]() ,可以通过最小化以下损失来端对端地训练FCN网络以进行显着性检测。
,可以通过最小化以下损失来端对端地训练FCN网络以进行显着性检测。
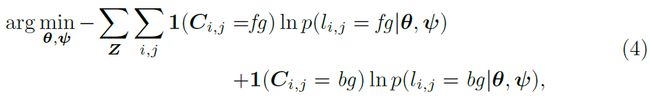
其中1(·)是指标函数。 网络参数 和 然后可以使用随机梯度下降(SGD)算法迭代地更新。
和 然后可以使用随机梯度下降(SGD)算法迭代地更新。
3.2用于显著性检测的迭代网络
训练上述FCN网络以近似从原始像素到显着值的直接非线性映射,并忽略在现有方法中广泛使用的显着性先验。 尽管启发式显着性先验有其局限性,但它们易于计算并且在各种情况下都显示出非常有效。 因此,我们认为利用显着性先验信息可以促进更快的训练和更准确的推理。 这已通过我们的实验验证。 我们还注意到FCN的输出预测可能非常嘈杂并且缺乏标签一致性。 但是,FCN的前馈架构无法考虑反馈信息,这使得无法纠正预测错误。 基于这些观察,我们对FCN网络进行了两项改进,并通过以下方式设计RFCN:i)在训练和推理中结合显着性先验; ii)迭代地精细化输出预测。

显着优先映射。我们将先验知识编码到显着性先验图中,该映射用作网络的输入。 我们首先将输入图像转换为M个超像素
{Si}![]() 。 si的颜色对比度通过计算得出
。 si的颜色对比度通过计算得出

其中u 和p表示平均RGB值和超像素中心位置 ,分别; ?i是归一化因子; 和? 是一个比例参数(xed为0.5)。 通过用对应的特征值替换(5)中的颜色值,可以以类似的方式计算强度对比度I(si)和取向特征对比度O(si)。 显着性先验图P通过获得
![]()
其中P(si)表示超像素si的显着性先验值; 并且中心先验[11] U(si)惩罚从超像素si到图像中心的距离。
迭代结构。为了将显着性先验映射纳入我们的方法,我们考虑了RFCN网络的两种循环架构。 如3.1节所述,我们将网络分为两部分,即卷积部分F(?;?)和反卷积部分U(?;)。 我们的第一个循环结构(图3(d))通过修改第一个卷积层将显着性先验映射P合并到卷积部分中
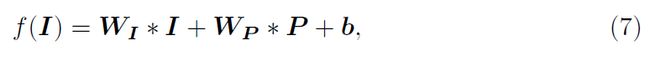
其中I和P分别表示输入图像和显着性; WI和WP代表相应的卷积核; b是偏置参数。 在第一个时间步骤中,RFCN网络将输入图像和显着性先前映射作为输入并产生最终特征映射^ Y 1 = U(F(I; P;?);)包括前景映射^ H 1和背景 在下面的每个时间步骤中,将在上一时间步骤中生成的前景映射^Ht?1作为显着性先前映射反馈到输入。 然后,RFCN通过将输入图像和最后预测都视为,来确定显着性预测

对于上述循环结构,整个网络的前向传播在每个时间步进行,这在计算和存储方面都是非常昂贵的。 另一种循环结构是将显着性先验图合并到反卷积部分((图3(e)))。 具体地,在第一时间步骤中,我们将输入图像I馈送到卷积部分以获得卷积特征图F(I;?)。 然后,去卷积部分将卷积特征图以及显着性先验图P作为输入来推断显着性预测^ Y 1 = U(F(I;?); P;)。 在第t个时间步骤中,最后一个时间步骤中的预测前景图^Ht?1用作显着性先验图。反卷积部分采用卷积特征图F(I;?)以及前景图^ H t?1进行显着性预测^ Y t:

注意,对于每个输入图像,反卷积部分的前向传播在每个时间步骤中重复进行,而卷积部分仅需要在第一时间步骤中前馈一次。由于反卷积部分的参数比卷积部分少大约10倍,因此这种循环结构可以有效地降低计算复杂度并节省存储器。然而,我们在初步实验中发现,与基于FCN的方法相比,第二次循环结构只能实现类似的性能(即,没有重复发生)。这可能归因于以下事实:先前显着图被严格下采样到最后卷积特征图F(I;?)的相同空间大小(从输入下采样1/32倍)。利用较少的先验信息,下采样的先验显着图很难促进网络推断。因此,我们在这项工作中采用了第一个循环结构。在我们的实验中,我们观察到显着图的精确度在第二个时间步之后几乎收敛(比较图5(a)和(e))。因此,我们将RFCN的总时间步长设置为T = 2。

3.3训练用于显著性检测的RFCN
我们的RFCN培训方法包括两个阶段:预培训和微调。在PASCAL VOC 2010语义分割数据集上进行预训练。灵敏度检测和语义分割高度相关,但本质上不同,显着性检测旨在将通用显着对象与背景分离,而语义分割则侧重于区分不同类别的对象。 我们的预训练方法受到分段数据的强大监督,并且还使网络能够学习前景对象的一般表示。 具体地,对于包含图像I和逐像素语义注释S的每个训练对Z =(I; S),我们生成对象图G以将每个像素标记为前景(fg)或背景(bg),如下

其中Si; j 2 f0;1; :::; Cg表示像素(i; j)和Si的语义类标签; j = 0表示属于背景的像素。 在预训练阶段,由RFCN生成的最终特征图^ Y t(第3.1节)由C + 3个通道组成,其中第一个C + 1通道对应于语义分割和最后2个通道的类别分数, 即,^ H t和^ B t(第3.1节)表示前景/背景分数。 通过应用softmax函数,我们得到RFCN预测的条件概率p(ci; j jI; ^Ht?1;?;)和p(li; j jI; ^ Ht?1;?;)用于分割和 前景检测,分别。 所有时间步骤的预训练损失函数定义为


其中T是总时间步长,并且由显着性先验图P(第3.2节)初始化^ H0。 通过随时间的反向传播进行预训练。
在预训练之后,我们通过移除最后一个特征映射的第一个C + 1通道并且仅维持最后两个通道(即,预测的前景和背景图)来修改RFCN网络架构。 最后,我们如第3.2节所述,在显着性检测数据集上微调RFCN网络。如图6(c)所示,预训练模型由多个对象类别的语义标签监控,捕获通用对象特征和 已经可以将前景对象(预训练中看不见的类别)与背景区分开来。对显着性数据集进行精细调整可以进一步提高RFCN网络的性能(图6(d))。
3.4后处理
经过训练的RFCN网络能够准确识别显着对象。 为了更精确地描绘紧凑和边界保留对象区域,我们采用了有效的后处理方法。 给定RFCN预测的最终显着性得分图^ H T,我们首先通过阈值^ H T及其平均显着性得分将图像分割为前景和背景区域。 针对每个像素(i; j)计算空间置信度SCi; j和颜色对象CCi; j。考虑像素到前景区域的中心的空间距离来定义空间置信度。

其中loci; j和loc分别表示像素(i; j)和前景中心的坐标;? 是一个比例参数。 定义颜色置信度以测量RGB颜色空间中像素与前景区域的相似性

其中Ni; j是具有与像素(i; j)相同的颜色特征的前景像素的数量,并且Ns是前景像素的总数。
然后,我们通过空间和颜色置信度对预测显着性分数进行加权,以扩大前景区域
![]()
在扩张显着性得分图~H上的边缘感知侵蚀程序[4]之后,我们获得最终显着性图。 如图6(e)所示,后处理步骤可以在一定程度上提高检测精度。