【计算机系统结构】样例试卷及参考答案
计算机系统结构样例试卷
一、选择题(每小题2分,共20分)
1、关于计算机系统结构、计算机组成和计算机实现间的关系说法正确的是( )。
A.计算机组成是计算机系统结构的逻辑实现
B.一种计算机系统结构只可以有一种计算机组成
C.一种计算机组成只可以有一种计算机实现
D.同一系列机中各种型号的机器具有相同的系统结构,以及相同的组成和实现技术
2、关于RISC和CISC处理机的指令系统结构说法正确的是( )。
A.RISC采用变长编码 B.CISC采用定长编码
C.RISC只有load/store指令可以访存 D.CISC 的CPI为1
3、将计算机系统中某一部件的处理速度提高为原来的10倍,但该部件的处理时间占整个系统运行时间的50%,则系统加速比约为( )。
A.1.2 B.1.6 C.1.8 D.2.0
4、load-store指令集结构的优点是( )。
A.无需“浪费”寄存器保存变量 B.其目标代码量较小
C.可以直接对存储器操作数进行访问 D.各种指令的执行时钟周期数相近
5、关于流水线瓶颈段说法错误的是( )。
A.瓶颈段指时间最长的段 B.瓶颈段指时间最短的段
C.细分瓶颈段是常用解决方法 D.重复设置瓶颈段是常用解决方法
6、MIPS流水寄存器不包括( )。
A.IF / ID B.ID / EX C.EX / WB D.MEM / WB
7、关于3C失效与Cache的相联度、容量的关系说法正确的是( )。
A.相联度越高,冲突失效就越少
B.强制性失效和容量失效会受相联度的影响
C.强制性失效会受Cache容量的影响
D.容量失效随着容量的增加而增加
8、对于两级Cache,假设在1000次访存中,第一级Cache失效40次,第二级Cache失效20次,则第二级Cache的局部失效率为( )。
A.2% B.4% C.40% D.50%
9、低速或中速的外围设备适合连接到( )。
A.选择通道 B.字节多路通道 C.数组多路通道 D.任意一种通道
10、关于目前较为流行的并行编程工具说法错误的是( )。
A.OpenMP可用于多核编程开发
B.OpenMP提供一个共享存储并行系统上的应用编程接口
C.MPI是基于消息传递的工具,而PVM不是基于消息传递的工具
D.HPF是一个支持数据并行的并行语言标准
二、问答题(共26分)
1、(8分)解决流水线数据冲突的方法主要有哪四种?并对各种方法做简要说明。
2、(10分)“Cache-主存”和“主存-辅存”层次的主要区别是什么?
3、(8分)降低Cache失效率有哪些方法?至少对四种方法做简要说明。
三、分析题(共9分)
通过展开循环两次,列举出下面循环中的所有相关,包括输出相关、反相关、真数据相关。
for (i=2 ;i<100 ; i=i+1)
a[i] = b[i] + a[i] ;
c[i+1] = a[i] +d[i] ;
a[i-1] = 2 * b[i] ;
b[i+1] = 2 * b[i] ;
四、计算题(共45分)
1、(18分)动态多功能流水线由5段组成,如下图所示。
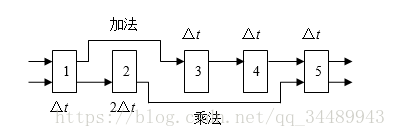
其中,加法用1、3、4、5段,乘法用1、2、5段,第2段的时间为2△t,其余各段的时间均为△t,而且流水线的输出可以直接返回输入端或暂存于相应的流水寄存器中。若在该流水线上计算:。要求:
(1)选择适合于流水线工作的算法;
(2)画出其流水线时空图;
(3)计算其吞吐率、加速比和效率。
2、(12分)给定以下的假设,
(1)对指令Cache的访问占全部访问的75%,对数据Cache的访问占25%;
(2)Cache的命中时间为1个时钟周期,失效开销为50个时钟周期;
(3)在混合Cache中一次load或store操作访问Cache的命中时间都要增加1个时钟周期;
(4)32KB的指令Cache的失效率为0.39%,32KB的数据Cache的失效率为4.82%,64KB的混合Cache的失效率为1.35%;
(5)采用写直达策略,且有一个写缓冲器,并且忽略写缓冲器引起的等待。
要求:
(1)对于指令Cache和数据Cache容量均为32 KB的分离Cache,计算其失效率,且计算其平均访存时间;
(2)计算容量为64 KB的混合Cache的平均访存时间;
(3)分别从失效率和平均访存时间两个方面,比较分离Cache与混合Cache的性能。
3、(15分)假设某台计算机的特性及性能为:
(1)存储器总线宽度为1个字(32位),送地址需要4个时钟周期,每个字的访问时间为24个时钟周期,传送1个字的数据需4个时钟周期;
(2)Cache块大小为1个字时,Cache失效率为3%;
(3)平均每条指令访存1.2次;
(4)在不考虑Cache失效时,平均CPI为2。
要求:
(1)计算Cache失效开销,存储器的带宽以及在考虑Cache失效时的CPI;
(2)若Cache块大小为2个字时,Cache失效率为2%,计算相应的CPI;
(3)若Cache块大小为2个字时,讨论在采用2路多体交叉存取以及将存储器和总线宽度增加一倍时,对提高性能(用CPI说明)各有何作用?
参考答案
一、选择题(每小题2分,共20分)
1、A 2、C 3、C 4、D 5、B 6、C 7、A 8、D 9、B 10、C
二、问答题(共26分)
1、解决流水线数据冲突的方法有:
(1)定向技术:在某条指令产生一个结果之前,其他指令并不真正需要该计算结果,如果将该结果从其产生的地方直接送到其他指令需要它的地方,就可以避免暂停。
(2)暂停技术:设置一个“流水线互锁”的功能部件,一旦流水线互锁检测到数据相关,流水线暂停执行发生数据相关指令后续的所有指令,直到该数据相关解决为止。
(3)采用编译器调度:为了减少停顿,对于无法用定向技术解决的数据冲突,可通过在编译时让编译器实现指令调度或流水线调度来消除冲突。
(4)重新组织代码顺序:重新组织指令顺序,以加大相关指令的距离,进而减少数据冲突的可能性。
2、
存储层次 比较项目 |
“Cache-主存”层次 |
“主存-辅存”层次 |
目的 |
为了弥补主存速度的不足 |
为了弥补主存容量的不足 |
存储管理的实现 |
全部由专用硬件实现 |
主要由软件实现 |
访问速度的比值 (第一级比第二级) |
几比一 |
几万比一 |
典型的块(页)大小 |
几十个字节 |
几百到几千个字节 |
CPU对第二级的访问方式 |
可直接访问 |
均通过第一级 |
不命中时CPU是否切换 |
不切换 |
切换到其他进程 |
3、降低Cache失效率方法有:
(1)增加Cache块大小:可减少强制性失效,但由于增加块大小会减少Cache中块的数目,会增加失效开销,所以有可能会增加冲突失效。因此,对于给定的Cache容量,当块大小增加时,失效率开始是下降,后来反而上升了。(2)提高相联度:会降低失效率,但可能是以增加命中时间为代价。 实际应用中所采用的相联度不会超过8。(3)增加Cache的容量:最直接的方法,但增加成本,可能会增加命中时间。该方法在片外Cache中用得比较多。(4)Victim Cache:一种能减少冲突失效次数而又不影响时钟频率的方法。其基本思想是在Cache和它从下一级存储器的数据通路之间设置一个全相联的小Cache,用于存放被替换出去的块(称为Victim),以备重用。对于减小冲突失效很有效,特别是对于小容量的直接映象数据Cache,作用尤其明显。(5)伪相联Cache:具有命中时间小和失效率低的优点。其基本思想是在逻辑上把直接映象Cache的空间上下平分为两个区。对于任何一次访问,伪相联Cache先按直接映象Cache的方式去处理。若命中,则其访问过程与直接映象Cache的情况一样。若不命中,则再到另一区相应的位置去查找。若找到,则发生了伪命中,否则就只好访问下一级存储器。要保证绝大多数命中都是快速命中。(6)硬件预取技术:指令和数据都可以预取。预取内容既可放入Cache,也可放在外缓冲器中。指令预取通常由Cache之外的硬件完成。(7)由编译器控制的预取:目的是使执行指令和读取数据能重叠执行。在编译时加入预取指令,在数据被用到之前发出预取请求。在预取数据的同时,处理器应能继续执行,通常采用非阻塞Cache。循环是预取优化的主要对象。(8)编译器优化:其基本思想是在编译时,对程序中的指令和数据进行重新组织,以降低Cache失效率。数据对存储位置的限制比指令的少,因此更便于优化。通过把数据重新组织,使得一块数据在被从Cache替换出去之前,能最大限度利用其中的数据(访问次数最多)。
三、分析题(共9分)
展开循环两次,如下:
a[i] = b[i] + a[i] ; /* S1 */
c[i+1] = a[i] +d[i] ; /* S2 */
a[i-1] = 2 * b[i] ; /* S3 */
b[i+1] = 2 * b[i] ; /* S4 */
a[i+1] = b[i+1] + a[i+1] ; /* H1 */
c[i+2] = a[i+1] +d[i+1] ; /* H2 */
a[i] = 2 * b[i+1] ; /* H3 */
b[i+2] = 2 * b[i+1] ; /* H4 */对于单次循环,其中:
输出相关:无。
反相关:无。
真相关:S1 和S2。
由于循环引入的相关,其中:
输出相关:S1 和H3
反相关:S1 和H3、S2 和H3。
真相关:S4 和H1、S4 和H3、S4 和H4。
四、计算题(共45分)
1、(18分)
解:
(1)选择适合于流水线工作的算法
先计算A1×B1、A2×B2、A3×B3和A4×B4;
再计算(A1×B1)+(A2×B2)和(A3×B3)+(A4×B4);
然后求总的累加结果。
(2)画出其流水线时空图
图中阴影部分表示该段在工作。

完成加乘运算的多功能动态流水线时空图
(3)计算其吞吐率、加速比和效率
在18个△t时间中,给出了7个结果。吞吐率为:![]()
若不用流水线,由于一次求积需4△t,一次求和需4△t, 则产生上述7个结果共需(4×4+3×4)△t = 28△t 。
加速比为:![]()
该流水线的效率可由阴影区和5个段总时空区的比值求得:![]()
2、(12分)
解:
(1)对于分离Cache的总体失效率为:
(75%×0.39%)+(25%×4.82%)=1.4975%
平均访存时间公式可以分为指令访问和数据访问两部分:
平均访存时间 = 指令所占的百分比×(指令命中时间+指令失效率×失效开销+数据所占的百分比×(数据命中时间+数据失效率×失效开销)
分离Cache的平均访存时间=75%×(1+0.39%×50)+25%×(1+4.82%×50)
=1.74875
(2)混合Cache的平均访存时间=75%×(1+1.35%×50)+25%×(1+1+1.35%×50)
=1.925
(3)从失效率方面来看,分离Cache为1.4975%,其大于混合Cache的失效率1.35%,混合Cache的性能优于分离Cache。
但从平均访存时间来看,分离Cache为1.74875个时钟周期,其小于混合Cache的1.925个时钟周期,分离Cache的性能优于混合Cache。
因此,尽管分离Cache的实际失效率比混合Cache的高,但分离Cache提供了两个端口,消除了结构冲突,其平均访存时间反而较低。
3、(15分)
解:
(1)当Cache块大小为一个字时,
Cache失效开销为4+24+4=32个时钟周期。
存储器的带宽为每个时钟周期4/32=1/8字节。
在考虑Cache失效时的CPI为2+(1.2×3%×32) = 3.15个时钟周期。
(2)若Cache块大小为2个字时,Cache失效率为2%,
相应的CPI为2+(1.2×2%×2×32) = 3.54个时钟周期。
(3)若Cache块大小为2个字且采用2路多体交叉存取时,
相应的CPI为2+1.2×2%×(4+24+8)= 2.86个时钟周期。
性能相对于不采用2路多体交叉存取,提高了(3.54-2.86)/ 3.54 =19.21%。
若Cache块大小为2个字且采用64位总线和存储器,不采用多体交叉时,
相应的CPI为2+1.2×2%×1×32 = 2.77个时钟周期。
性能相对于不采用存储器和总线宽度增加一倍,提高了(3.54-2.77)/ 3.54 =21.75%。