电影推荐系统(推荐系统的hello work)
什么是推荐系统?
互联网的信息越来越多,用户面对大量数据信息的时候,无法获得对自己真正有用的部分,造成信息超载问题。
推荐系统就是解决信息超载的一个办法。
推荐系统依据用户的历史行为、社交关系、兴趣点等信息去判断用户当前需要或感兴趣物品/服务的应用。
推荐是去预测用户对某个他没有使用过的物品/服务的喜欢程度(一般是打分机制),物品/服务可以是电影、书、音乐、新闻等;
推进系统核心任务主要是把用户和信息关联起来,
- 对用户而言:推荐系统可以帮助用户找到喜欢的物品/服务, 帮忙进行决策,发现用户可能喜欢的新事物
- 对商家而言:可以给用户提供个性化的服务,提高用户信任度,关注。增加营利收益。
背景介绍
推荐问题的发展历史
1994年, Minncsota, GroupLcns 研究组论文
- 提出 “协同过滤” 的概念
- 推荐问题的形式化
- 影响深远
目前已经广泛应用到很多商业应用系统
尤其是网络购物平台: 亚马逊,京东,淘宝等
Google新闻: 38%的点击量来自推荐等等。
新闻:今日头条
视频:抖音推荐短视频
推荐系统的输入(三元组)
user(用户) + item(物品/服务) + review(用户对物品的评价)
User & user Profile(用户画像)
- 描述一个用户的 “个性”
- 两种构建 (用户画像)
- 与item Profile 类似,如用户的性别、年龄、年收入、活跃时间
- 难以与item 建立具体的联系
- 隐私问题
- 很少直接使用
- 利用item Profile 构建User Profile
- 信息检索(IR)
- 与item Profile 类似,如用户的性别、年龄、年收入、活跃时间
Item(物品) & Item Profile(物品对应特征)
- 电影: 类别、导演、主演、国家等
- 新闻: 标题、本文、关键词、时间等
Review (user 对 item 的评价)
- 最简单的Review:打分(Rating)
- 一般是 1 - 5 的星级
- 其他Review:
- 评论
- 评分
- 标签
推荐系统的输出
-
推荐列表( TOP-N)
- 按照排序给出对该用户的推荐
-
推荐理由
- 与 IR(信息索引) 系统不同
- 基于统计
- 比如购买了某物品的用户有90%也购买了该物品。(找图)
- 该物品在某类别中人气最高
- 重要性
- 解决推荐的合理性问题
- 受到越来越多的重视
应用场景
-
亚马逊个性化推荐
-
亚马逊相关推荐
-
电影和视频网站
-
个性化音乐网络电台
-
抖音视频的推荐
-
网易云音乐
-
Facebook
-
其他
- 个性化阅读
- 基于位置的服务
- 个性化邮件
- 个性化广告
基本原理
利用用户行为数据
-
用户行为在个性化推荐系统中一般分为两种
- 显性反馈行为
- 用户明确表示对物品喜好的行为
- 隐性反馈行为
- 指那些不能明确反应用户喜好的行为(比如:页面浏览)
- 显性反馈行为
-
协同过滤算法
- 协同过滤: 用户通过不断与网页互动,使自己的推荐列表能够不断过滤掉自己不敢兴趣的物品,从而越来越满足自己的 需求。
- 基于用户的协同过滤算法(UserCF): 依据跟他兴趣相似的其他用户,推荐其他用户喜欢的物品。
- 基于物品的协同过滤算法(ItemCF): 依据他之前(喜欢的物品)推荐相似的物品
-
UserCF推荐步骤
-
(先找到和他有相同兴趣的其他用户):
比如下面的图: 分为 用户 A、B、C、D。 物品: a、b、c、d

找出对某个物品有共同兴趣的用户,比如对物品a 有兴趣的有用户A和用户B
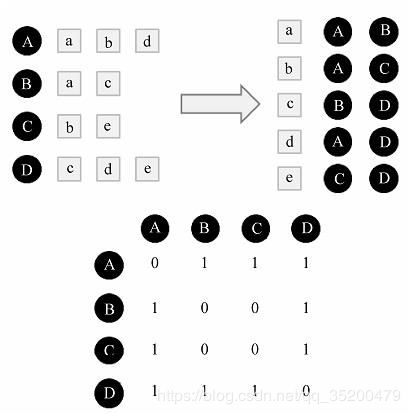
采用余弦相识度公式:
越接近 1 ,相似度越高 ,A 和 B只有a ,1个,总共 3 × 2 个组合
W u v = ∣ N ( u ) ⋂ N ( v ) ∣ ∣ N ( u ) ∣ ∣ N ( v ) ∣ 则 用 户 A 和 B 相 似 度 : W A B = ∣ { a , b , d } ∣ ⋂ ∣ { a , c } ∣ ∣ { a , b , d } ∣ ∣ { a , c } ∣ = 1 6 W_{uv} = \frac{|N(u)\bigcap N(v)|}{\sqrt{|N(u)|\ \ |N(v)|}} \\ 则用户A 和 B 相似度:\ \ \ \ \ \ W_{AB} = \frac{|\{a,b,d\}|\bigcap|\{a,c\}|} {\sqrt{|\{a,b,d\}|\ \ |\{a,c\}|}} = \frac{1}{\sqrt{6}} Wuv=∣N(u)∣ ∣N(v)∣∣N(u)⋂N(v)∣则用户A和B相似度: WAB=∣{a,b,d}∣ ∣{a,c}∣∣{a,b,d}∣⋂∣{a,c}∣=61
然后 UserCF 算法会给用户推荐和他感兴趣最相近的 K 个用户喜欢的物品 -
p ( u , i ) = ∑ v ϵ S ( u , K ) ⋂ ( i ) W u v R v i p(u,i) = \sum_{v\epsilon S(u,K)\bigcap(i)}\ W_{uv}R_{vi} p(u,i)=vϵS(u,K)⋂(i)∑ WuvRvi
参数说明:u 用户, i 物品
1. S(u, K): 包含和用户u 兴趣最接近的 K 个用户
2. N(i): 对物品 i 有过行为的用户集合
3. Wuv : 用户u 和 用户 v 的兴趣相似度
4. Rvi: 代表用户v 对物品 i 的兴趣
- 基于图的推荐算法
- 二分图又称作二部图,是图论中的一种特殊模型。
利用用户标签数据
- 通过一些特征联系用户和物品,给用户推荐那些具有用户喜欢的特征的物品
利用上下文信息
- 用户所处的上下文(context), 包括用户访问推荐系统的时间、地点、心情等,对于提高推荐系统的推荐效果是非常重要的。
利用社交网络
- 依据调查结果显示,90%的用户相信朋友对他们的推荐,70%的用户相信网上其他用户对广告商品的评论。
MovieLens 数据集
- MovieLens 包含了电影推荐服务的5星评分和文本标记数据
使用 jupyter notebook分析MovieLens 数据集
导入需要的模块
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
读取对应的数据集显示
header = ['user_id', 'item_id', 'rating', 'timestamp']
src_data = pd.read_csv('ml-100k/u.data', sep='\t', names = header)
src_data.head()
按user_id 排序
user_data = pd.DataFrame(src_data)
user_data.sort_values(by='user_id')
对应的数据集
# 用户信息: 用户ID,年龄,性别,职业,邮政编码
u_cols = ['user_id', 'age', 'sex', 'occupation', 'zip_code']
users = pd.read_csv('ml-100k/u.user', sep='|', names=u_cols, encoding='latin-1')
# 评分信息: 用户ID,电影ID,评分,时间戳
r_cols = ['user_id', 'movie_id', 'rating', 'unix_timestamp']
ratings = pd.read_csv('ml-100k/u.data', sep='\t', names=r_cols, encoding='latin-1')
# 电影信息:电影ID,电影标题,发布时间,上映时间,IMBD地址
m_cols = ['movie_id', 'title', 'release_date', 'video_release_date', 'imbd_url']
movies = pd.read_csv('ml-100k/u.item', sep='|', names=m_cols, usecols=range(5), encoding='latin-1')
把用户,物品,评分这些表结合
# 把这些数据融合
movie_ratings = pd.merge(users, ratings)
merge_data = pd.merge(movie_ratings, movies)
merge_data.head()
找出评论次数最多的电影
安装电影标题分为不同的组(groups), 并且用size()函数得到
每一部电影的个数(即每部电影被评论的次数),按照从大到小排序,取最大的前20部电影
title_size = merge_data.groupby('title').size()
sort_val = title_size.sort_values(ascending=False)[:20]
print(sort_val)
评分最高的十部电影
按照电影名称分组
取出至少被评论过100次的电影按照平均评分从大到小排序,取最大的10部电影
movie_stats = merge_data.groupby('title')
# 使用agg 函数通过一个字典{’rating':[np.size, np.mean]}来按照key即rating
rating_agg = movie_stats.agg({'rating': [np.size, np.mean]})
# 依据布尔(true, false)排序
take_100 = rating_agg['rating']['size'] >= 100
# print(take_100)
sort_raring = rating_agg[take_100].sort_values([('rating', 'mean')], ascending=False)
sort_raring[:10]
直方图查看用户的年龄分布
plt.hist(users.age, bins=30, color='red', alpha=0.75)
plt.xlabel('age')
plt.ylabel('count of users')
plt.show()
用户年龄分组
# 将用户年龄分组
labels = ['10-19', '20-29', '30-39', '40-49', '50-59', '60-69', '70-79']
merge_data['age_group'] = pd.cut(merge_data.age, range(10, 81, 10), right=False, labels=labels)
merge_data[['age', 'age_group']].drop_duplicates()[:10]
# 每个年龄段用户评分偏好
merge_data.groupby('age_group').agg({'rating':[np.size, np.mean]})
推荐系统框架: surprise
摘自官网surprise简要概述:
Surprise was designed with the following purposes in mind:
- Give users perfect control over their experiments. To this end, a strong emphasis is laid on documentation, which we have tried to make as clear and precise as possible by pointing out every detail of the algorithms.
- Alleviate the pain of Dataset handling. Users can use both built-in datasets (Movielens, Jester), and their own custom datasets.
- Provide various ready-to-use prediction algorithms such as baseline algorithms, neighborhood methods, matrix factorization-based ( SVD, PMF, SVD++, NMF), and many others. Also, various similarity measures (cosine, MSD, pearson…) are built-in.
- Make it easy to implement new algorithm ideas.
- Provide tools to evaluate, analyse and compare the algorithms performance. Cross-validation procedures can be run very easily using powerful CV iterators (inspired by scikit-learn excellent tools), as well as exhaustive search over a set of parameters.
大体上是说,推荐系统被设计时,充分考虑了用户控制,减轻数据集的处理,可以使用内置的数据集(Movielens, Jester), 提供了大量的基本算法,能更容易实现新的想法, 提供算法分析、模型评估、比较算法性能的工具。一个简单的Python 推荐系统引擎库
安装方法
pip install numpy
pip install scikit-surprise
也可以 anaconda 安装:
conda install -c conda-forge scikit-surprise
也可以从git clone github官网安装最新版本
pip install numpy cython
git clone https://github.com/NicolasHug/surprise.git
cd surprise
python setup.py install
基本算法
| 算法类名 | 描述 |
|---|---|
random_pred.NormalPredictor |
依据训练集的分布特征随机给预测值 |
baseline_only.BaselineOnly |
给定用户和Item, 给出基于baseline的估计值 |
knns.KNNBasic |
最基础的协同过滤 |
knns.KNNWithMeans |
将每个用户评分的均值考虑在内的协同过滤实现 |
knns.KNNWithZScore |
一种基本的协同过滤算法,考虑到每个用户的Z分数标准化。 |
knns.KNNBaseline |
考虑基线评级的协同过滤 |
matrix_factorization.SVD |
SVD(奇异值)实现 |
matrix_factorization.SVDpp |
SVD++ |
matrix_factorization.NMF |
基于矩阵分解的协同过滤 |
| slope_one.SlopeOne | 一个简单但精确的协同过滤算法 |
| co_clustering.CoClustering | 基于协同聚类的协同过滤算法 |
交叉验证迭代器
KFold |
一个基本的交叉验证迭代器。 |
|---|---|
RepeatedKFold |
重复KFold交叉验证。 |
ShuffleSplit |
具有随机顺练集和测试集的基本交叉验证迭代器。 |
LeaveOneOut |
交叉验证迭代器,其中每个用户在测试集合中只有一个评级。 |
PredefinedKFold |
使用load_from_folds 方法加载数据集时的交叉验证迭代器。 |
相识度准则
cosine |
计算所有用户(或物品)对之间的余弦相似度。 |
|---|---|
msd |
计算所有用户(或物品)对之间的均方差异相似度 |
pearson |
计算所有用户(或物品)对之间的Pearson相关系数。 |
pearson_baseline |
计算所有用户(或项目)对之间的(缩小的)Pearson相关系数,使用基线进行居中而不是平均值。 |
精度评估
rmse |
计算RMSE (均方根误差). |
|---|---|
mae |
计算MAE (平均绝对误差). |
fcp |
计算 FCP (协调对的分数). |
自带三个数据集
-
movielens-100k 数据集:1700部电影的1000名用户获得100,000评级。 发布于4/1998。
-
movielens-1m 数据集: 4000部电影的6000名用户获得100万评级。 2003年2月发布。
-
Jester 数据集:在线笑话评分。
上面的都可以在各自的网站下载到,都分有时间段收集的数据集。
加载数据集
Dataset.load_builtin |
加载内置数据集。 |
|---|---|
Dataset.load_from_file |
从(自定义)文件加载数据集。 |
Dataset.load_from_folds |
加载数据集,其中折叠(用于交叉验证)由某些文件预定义。 |
Dataset.folds |
生成器函数迭代数据集的折叠。 |
DatasetAutoFolds.split |
将数据集拆分为折叠以供接下来的交叉验证。 |
surprise官方实例
from surprise import SVD
from surprise import Dataset
from surprise.model_selection import cross_validate
# Load the movielens-100k dataset (download it if needed).
data = Dataset.load_builtin('ml-100k')
# Use the famous SVD algorithm.
algo = SVD()
# Run 5-fold cross-validation and print results.
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
Output
评估5次分裂的算法SVD的RMSE,MAE。 Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Mean Std RMSE 0.9311 0.9370 0.9320 0.9317 0.9391 0.9342 0.0032 MAE 0.7350 0.7375 0.7341 0.7342 0.7375 0.7357 0.0015 Fit time 6.53 7.11 7.23 7.15 3.99 6.40 1.23 Test time 0.26 0.26 0.25 0.15 0.13 0.21 0.06
- 但是官网自带的大量实例,只能看到算法评估效果。
如何计算某一个用户(user)对某一个物品(item)的评分?
根据预测结果,获取TOP-N的函数
def get_top_n(predictions, n = 10):
top_n = defaultdict(list)
# uid: 用户ID
# iid: 物品ID
# est: 估计得分
for uid, iid, true_r, est, _ in predictions:
top_n[uid].append((iid, est))
# 为每一个用户都寻找 K 个得分最高的item
for uid, user_ratings in top_n.items():
user_ratings.sort(key=lambda x: x[1], reverse=True)
top_n[uid] = user_ratings[:n]
return top_n
自带 ml-100k数据TOP-N 推荐
每一个用户评分最高的10个物品Item
# 首先在movielens数据集上训练SVD算法。
data = Dataset.load_builtin('ml-100k')
# 转换,这样才能获取数据集详细信息
trainset = data.build_full_trainset()
algo = SVD()
algo.fit(trainset)
testset = trainset.build_anti_testset()
predictions = algo.test(testset)
top_n = get_top_n(predictions, n = 10)
for uid, user_ratings in top_n.items():
print(uid, [iid for (iid, _) in user_ratings])
在自己的数据上做TOP-N推荐
from surprise import SVD
from surprise import Dataset, print_perf, Reader
from surprise.model_selection import cross_validate
import os
# 指定文件所在路径,mydata是自己制作的数据集
file_path = os.path.expanduser('mydata.csv')
# sep: 指定数据集以什么方式去读
reader = Reader(line_format='user item rating', sep=',')
# 加载数据
data = Dataset.load_from_file(file_path, reader=reader)
trainset = data.build_full_trainset()
#训练SVD算法
algo = SVD()
algo.fit(trainset)
测试用户获取第一个用户分别对第1,2,3个item的得分
testset = [('1', '1', 0),
('1', '2', 0),
('1', '3', 0),
]
predictions = algo.test(testset)
我们如何使用协同过滤?
基于用户的协同过滤算法(UserCF):
from surprise import KNNWithMeans
from surprise import Dataset, print_perf, Reader
from surprise.model_selection import cross_validate
import os
# 指定文件所在路径
file_path = os.path.expanduser('mydata.csv')
reader = Reader(line_format='user item rating timestamp', sep='\t')
# 加载数据
data = Dataset.load_from_file(file_path, reader=reader)
trainset = data.build_full_trainset()
# 读取数据
header = ['user', 'item', 'rating', 'timestamp']
src_data = pd.read_csv('mydata.csv', sep='\t', names = header)
user_data = pd.DataFrame(src_data)
user_data.sort_values(by='user').head()
# user-base CF 得分计算
algo = KNNWithMeans(k=50, sim_options={'user_based': True})
algo.fit(trainset)
uid = str(5)
iid = str(1)
pred = algo.predict(uid, iid)
pred
基于物品的协同过滤算法(ItemCF)
# item-based CF 得分计算
# 取最相似的用户计算时,只取最相似的k个
algo = KNNWithMeans(k=50, sim_options={'user_based': False})
algo.fit(trainset)
uid = str(1)
iid = str(1)
pred = algo.predict(uid, iid)
pred