c++ 通信演进level3 ----多线程同步 非阻塞通信(NIO)
本篇文章的源码同样来自网络上,自己稍加整理,并做一下源码方面的分析。本例子的作用一方面是为了理解http服务器,另一方面,是作为学习流操作的NIO模型层次。 地址在这里:地址。
代码结构如下:
首先,定义一个结构体,用于存储 接收的socket链表:
//标识客户端的节点 链表
typedef struct _NODE_
{
SOCKET s;
sockaddr_in Addr;
_NODE_* pNext;
}Node,*pNode;
服务端的开发,还是跟上一篇差不多,但是 采用了 winsock2的api,它是非阻塞的。
int main()
{
if (!InitSocket())
{
printf("InitSocket Error\n");
return -1;
}
GetCurrentDirectory(512,HtmlDir);
strcat(HtmlDir,"\\..\\html\\"); // 寻找 html 所在目录
strcat(HtmlDir,FileName);
std::cout<<"the path is:"<它的作用是,开启了一个线程专门用于接收。同时开启一个工作者线程,它会定时的遍历socket链表。 接收线程的中的关键代码段:
//创建一个监听套接字
SOCKET sListen = WSASocket(AF_INET,SOCK_STREAM,0,NULL,0,WSA_FLAG_OVERLAPPED); //使用事件重叠的套接字
.....
int Ret = bind(sListen,(sockaddr*)&LocalAddr,sizeof(LocalAddr));
.....
listen(sListen,5);
.....
//我们要为新的连接进行接受并申请内存存入链表中
SOCKET sClient = WSAAccept(sListen, (sockaddr*)&ClientAddr, &nLen, NULL, NULL);
.....
AddClientList(sClient,ClientAddr);//当接收到的soccket放入内存中
.....需要注意的是,这里的WSAAccept不是阻塞的,它会立即返回。 当然,这样的话会导致大部分时间做无意义的操作,而它的触发,通过事件机制是一个比较好的方式,这样既兼顾了 效率,也兼顾了 易用性(因为它带来了非阻塞的好处)。我刚刚思考了下,貌似这里accept阻塞并不会对接入程序带来很大的影响,只是说服务端在接入后可以立即做其它操作而已。
工作者线程的核心代码如下:
WSAEVENT Event = WSACreateEvent(); //该事件是与通信套接字关联以判断事件的种类
WSANETWORKEVENTS NetWorkEvent;
while (1){
pNode _ptr_tmp = pHead;
while (_ptr_tmp){
//将事件 与当前 的套接字 进行关联
WSAEventSelect(_ptr_tmp->s, Event, FD_READ | FD_WRITE | FD_CLOSE); //关联事件和套接字
DWORD dwIndex = 0;
dwIndex = WSAWaitForMultipleEvents(1,&Event,FALSE,100,FALSE);
dwIndex = dwIndex - WAIT_OBJECT_0;
if (dwIndex==WSA_WAIT_TIMEOUT||dwIndex==WSA_WAIT_FAILED)
{
//向后遍历
_ptr_tmp =_ptr_tmp->pNext;
}
// 分析什么网络事件产生
WSAEnumNetworkEvents(_ptr_tmp->s,Event,&NetWorkEvent);
//其他情况
if(!NetWorkEvent.lNetworkEvents)
{
//向后遍历
_ptr_tmp =_ptr_tmp->pNext;
}
if (NetWorkEvent.lNetworkEvents & FD_READ)
{
//开辟客户端线程用于通信
CreateThread(NULL,0,ClientThread,(LPVOID)_ptr_tmp,0, nullptr);
}
if(NetWorkEvent.lNetworkEvents & FD_CLOSE)
{
//在这里我没有处理,我们要将内存进行释放否则内存泄露
//todo: 需要释放的内存包括:socket句柄,thread句柄,以及thread句柄中所动态申请的资源
//向后遍历
_ptr_tmp =_ptr_tmp->pNext;
}
}
}工作者线程遍历当前的socket链表,对链表中的socket进行事件选择,如有读事件,则开启一个客户线程。(注意,当前例子中,对链表的操作尚不是线程安全的。)
客户线程关键代码如下:
......
Ret = WSARecv(sClient,&Buffers,dwBufferCount,&NumberOfBytesRecvd,&Flags,NULL,NULL);
......
Ret = WSASend(sClient,&Buffers,1,&NumberOfBytesSent,0,0,NULL);
......也就是说,它的实际操作仍然是先从客户端读取 消息,然后发送消息给客户端。 注意,此时的客户端是 浏览器,而此时的应用层协议为 http。 整体通信流程跟上一篇是差不多,但是这里采用非阻塞的方式处理信息的接收。
另外,与http协议有关的部分处理代码:
char szRequest[1024]={0}; //请求报文
char szResponse[1024]={0}; //响应报文
......
Ret = WSARecv(sClient,&Buffers,dwBufferCount,&NumberOfBytesRecvd,&Flags,NULL,NULL);
memcpy(szRequest,szBuffer,NumberOfBytesRecvd);
......
parseRequest部分
{
char pResponseHeader[512]={0};
char szStatusCode[20]={0};
char szContentType[20]={0};
strcpy(szStatusCode,"200 OK");
strcpy(szContentType,"text/html");
char szDT[128];
struct tm *newtime;
time_t ltime;
time(<ime);
newtime = gmtime(<ime);
strftime(szDT, 128,"%a, %d %b %Y %H:%M:%S GMT", newtime);
//读取文件
//定义一个文件流指针
FILE* fp = fopen(HtmlDir,"rb");
......
// 返回响应
sprintf(pResponseHeader, "HTTP/1.0 %s\r\nDate: %s\r\nServer: %s\r\nAccept-Ranges: bytes\r\nContent-Length: %d\r\nConnection: %s\r\nContent-Type: %s\r\n\r\n",
szStatusCode, szDT, SERVERNAME, length, bKeepAlive ? "Keep-Alive" : "close", szContentType); //响应报文
}
......
Ret = WSASend(sClient,&Buffers,1,&NumberOfBytesSent,0,0,NULL);
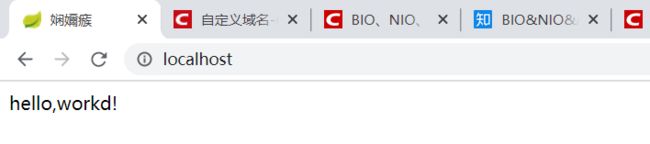
......运行结果:

总结:
1.http协议作为应用层协议的一种,实际上跟端对端通信没什么两样,不要过于神秘化,以上代码足以证明;
2.当前的这个例子中,一个socket对应着一个线程,事实上,这也是最简单的方式支持多个并发连接。 但是简单的不一定是最好的,当连接数量很多时,线程调度将变为灾难(要知道操作系统中可不仅仅只有当前的应用线程)。 同时对于频繁的连接操作,会导致线程资源的频繁回收,降低效率。(很早以前,我也觉得服务器没啥大不了嘛,要处理并发连接这还不简单。。。)
3.就当前的通信流程而言,我目前暂时看不出 非阻塞 较之于 阻塞的优点在哪(因为当前的线程实际上只做了一件事,那就是socket的读写,并未用于其它操作,即当前线程的任务本来就已经很单一了。)。 我猜想可能时 阻塞占用 cpu时间,而非阻塞不占用cpu时间吧(它等待的是内核对象)。
4.对BIO看了一些文章不是很懂。 目前的大致理解是: 通过内核事件,知道当前有要读取的信息,然后读取(读取是io操作,它的作用是 数据从 内核空间复制到用户空间,这个过程仍然是阻塞的。但是它不会阻塞当前线程)。
参考:

BIO、NIO、AIO 区别和应用场景