JUC_并发容器
- 并发容器
- 1、概述
- 2、CopyOnWrite
- 3、ConcurrentHashMap
- 1、底层数据结构
- 2、相关内部类
- 3、核心方法
- 1、get()
- 2、put()
- 4、总结
- 4、ConcurrentSkipListMap
- 1、概述
- 2、跳表(skip list)
- 5、BlockingQueue
- 1、概述
- 2、ArrayBlockingQueue
- 3、LinkedBlockingQueue
- 4、LinkedBlockingDeque
- 5、ConcurrentLinkedQueue
- 6、SynchronusQueue
- 7、LinkedTransferQueue
并发容器
1、概述
JUC提供了用于多线程上下文中的Collection实现与高效的、可伸缩的、线程安全的非阻塞FIFO队列。

1、List
- CopyOnWriteArrayList
- CopyOnWriteArrayList相当于线程安全的ArrayList。
2、Set
- CopyOnWriteArraySet
- 相当于线程安全的 HashSet,但是性能优于 HashSet
- ConcurrentSkipListSet
- 相当于线程安全的TreeSet基于 ConcurrentSkipListMap 的可缩放并发 NavigableSet 实现
3、Map
- ConcurrentHashMap
- 是线程安全的哈希表,相当于线程安全的HashMap
- ConcurrentSkipListMap
- 是线程安全的有序的哈希表,相当于线程安全的TreeMap。
4、Queue
- ArrayBlockingQueue
- 是一个由基于数组的、线程安全的、有界阻塞队列。
- LinkedBlockingQueue
- 是一个基于单向链表的、可指定大小的阻塞队列。
- LinkedBlockingDeque
- 是一个基于单向链表的、可指定大小的双端阻塞队列。
- ConcurrentLinkedDeque
- 是一个基于双向链表的、无界的队列。
- ConcurrentLinkedQueue
- 是一个基于单向链表的、无界的队列。
2、CopyOnWrite
CopyOnWrite 写时复制
所谓写时复制,即进行读操作时不加锁以保证性能不受影响,进行写操作时加锁,复制资源的一份副本,在副本上执行写操作,写操作完成后将资源的引用指向副本。高并发环境下,当读操作次数远远大于写操作次数时这种做法可以大大提高读操作的效率。
CopyOnWriteArrayList可以看做是线程安全的ArrayList,所有的写操作都是通过对底层数组进行一次新的复制实现的
CopyOnWriteArrayList就是一种符合写时复制思想的容器
//部分源码, 凑到一块的
final transient ReentrantLock lock = new ReentrantLock();
//底层数组,volatile保证内存可见性
private transient volatile Object[] array;
//复制一份容器的副本
final Object[] getArray() {
return array;
}
//将当期容器的引用指向修改后的副本。
final void setArray(Object[] a) {
array = a;
}//add()方法是写操作,可以看出执行的顺序是先加锁,复制一份副本,
//修改副本,将当前容器的引用指向修改后的副本,解锁。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}//get()方法就是一种最简单的读操作,可以看出是没有加锁的。
//因为每次add的时候,修改的都是副本,原来的引用并没有修改,所以说原来的引用
//只能用来读,而不能用来写,所以不会产生多线程问题
//因为读没有加锁所以效率高
@SuppressWarnings("unchecked")
private E get(Object[] a, int index) {
return (E) a[index];
}
public E get(int index) {
return get(getArray(), index);
}总结
- CopyOnWriteArrayList底层仍是数组
- 写操作时使用的锁是ReentrantLock。
- 为了当写操作改变了底层数组array时,读操作可以得知这个消息,需要使用volatile来保证array的可见性。
- 读操作都是没有加锁的。写操作都加了锁。
- 有利就有弊,写时复制提高了读操作的性能,但写操作时内存中会同时存在资源和资源的副本,可能会占用大量的内存。
3、ConcurrentHashMap
1、底层数据结构

在JDK1.7中,ConcurrentHashMap通过“分段锁”来实现线程安全。ConcurrentHashMap将哈希表分成许多片段(segments),每一个片段(table)都类似于HashMap,它有一个HashEntry数组,数组的每项又是HashEntry组成的链表。每个片段都是Segment类型的,Segment继承了ReentrantLock,所以Segment本质上是一个可重入的互斥锁。这样每个片段都有了一个锁,这就是“锁分段”。线程如想访问某一key-value键值对,需要先获取键值对所在的segment的锁,获取锁后,其他线程就不能访问此segment了,但可以访问其他的segment。
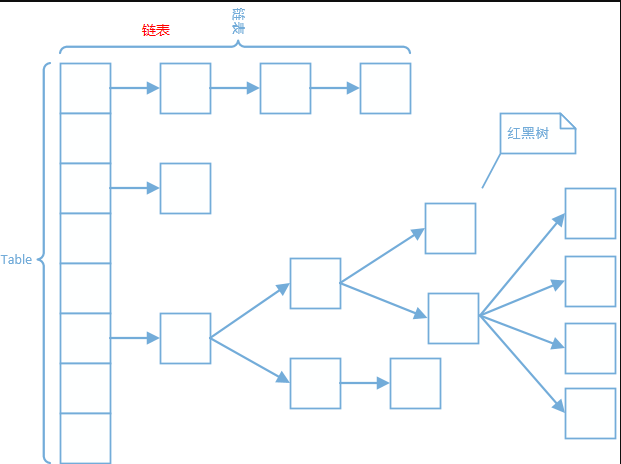
在JDK1.8中,ConcurrentHashMap放弃了“锁分段”,取而代之的是类似于 HashMap的数组+链表+红黑树结构,使用CAS算法和synchronized实现线程安全。
2、相关内部类
- Node。最基本的内部类,key-value键值对,不支持setValue方法。
- TreeNode。红黑树节点,供TreeBins使用。
- TreeBin。红黑树结构。该类并不包装key-value键值对,而是TreeNode的列表和它们的根节点。这个类含有读写锁。
- ForwardingNode。不是传统的节点,不包含key-value键值对,包含一个nextTable指针,和find方法 。
3、核心方法
简单介绍一下 ConcurrentHashMap 的核心方法
- get(Object)、
- put(K key, V value)
==sizeCtl最重要的属性之一,看源码之前,这个属性表示什么意思,一定要记住==。
//控制标识符
private transient volatile int sizeCtl;官方翻译:
- 负数代表正在进行初始化或扩容操作 ,其中-1代表正在初始化 ,-N 表示有N-1个线程正在进行扩容操作
- 正数或0代表hash表还没有被初始化,这个数值表示初始化或下一次进行扩容的大小,类似于扩容阈值。它的值始终是当前ConcurrentHashMap容量的0.75倍,这与loadfactor是对应的。实际容量>=sizeCtl,则扩容。
1、get()
public V get(Object key) {
Node[] tab; Node e, p; int n, eh; K ek;
//计算key的哈希值
int h = spread(key.hashCode());
//如果表不为空,表长度大于0,key所在的桶的头结点不为null
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
////如果查到的桶的头结点的key哈希值与参数key的哈希值相同
if ((eh = e.hash) == h) {
//如果查到的桶的头结点的key参数key相等,返回桶的头结点的value
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//如果查到的桶的头结点的key哈希值小于0,即要找的在树上
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
//如果要找的节点既不是桶的头结点也不是在树上,那就说明在链表上
while ((e = e.next) != null) {
//遍历链表,找到节点,返回值
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
//如果都没找到,返回null
return null;
} 可以将步骤总结如下:
- 通过key计算哈希值
- 通过哈希值找到桶
- 找到桶了,再根据 Hash 值查找节点
3.1. 以此判断桶的头结点是不是要找的节点
3.2. 如果不是,判断桶的头节点的哈希值是否小于0,如果是则说明要找的节点在树上
3.3. 如果以上两个条件都不满足,则说明要找的节点在链表上,遍历链表,查找节点- 如果通过以上步骤找到了节点,返回节点的value。没找到,就返回null。
从源码中可以看出,上面的步骤并没有加锁。
2、put()
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//计算哈希值
int hash = spread(key.hashCode());
int binCount = 0;
//死循环,只有插入成功才能跳出循环
for (Node[] tab = table;;) {
Node f; int n, i, fh;
//如果table没有初始化,初始化table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//根据哈希值计算在table中的位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//如果这个位置没有值,直接将键值对放进去,不需要加锁
if (casTabAt(tab, i, null,
new Node(hash, key, value, null)))
// no lock when adding to empty bin
break;
}
//如果要插入的位置是一个forwordingNode节点,表示正在扩容,那么当前线程帮助扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//进行到这一步,说明要插入的位置有值,需要加锁
synchronized (f) {
//确定f是tab中的头节点
if (tabAt(tab, i) == f) {
//如果头结点的哈希值大于等于0,说明要插入的节点在链表中
if (fh >= 0) {
binCount = 1;
//遍历链表中的所有节点
for (Node e = f;; ++binCount) {
K ek;
//如果某一节点的key哈希值和key与参数相等,替换节点的value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node pred = e;
//遍历到了最后一个节点,还没找到key对应的节点,
//根据参数新建节点,插入链表尾部
if ((e = e.next) == null) {
pred.next = new Node(hash, key,
value, null);
break;
}
}
}
//如果要插入的节点在树中,则按照树的方式插入或替换节点
else if (f instanceof TreeBin) {
Node p;
binCount = 2;
if ((p = ((TreeBin)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//如果binCount不为0,说明插入或者替换操作完成了
if (binCount != 0) {
//判断节点数量是否大于8,如果大于就需要把链表转化成红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
//如果在链表中找到了指定key的节点,返回被替换的value
return oldVal;
break;
}
}
}
//能执行到这一步,说明节点不是被替换的,是被插入的,所以要将map的元素数量加1
addCount(1L, binCount);
return null;
} 可以将步骤总结如下:
- 计算key哈希值
- 根据哈希值计算在table中桶的位置
- 根据哈希值执行插入或替换操作
3.1 如果这个位置没有值,直接将键值对放进去,不需要加锁。
3.2 如果要插入的位置是一个forwordingNode节点,表示正在扩容,那么当前线程帮助扩容
3.3 加锁。以下操作都需要加锁。
3.4 如果要插入的节点在链表中,遍历链表中的所有节点,如果某一节点的key哈希值和key与参数相等,替换节点的value,记录被替换的值;如果遍历到了最后一个节点,还没找到key对应的节点,根据参数新建节点,插入链表尾部。
3.5 如果要插入的节点在树中,则按照树的方式插入或替换节点。如果是替换操作,记录被替换的值- 判断节点数量是否大于8,如果大于就需要把链表转化成红黑树
- 如果操作3中执行的是替换操作,返回被替换的value。程序结束。
- 能执行到这一步,说明节点不是被替换的,是被插入的,所以要将map的元素数量加1。
可以看出,修改table结构使用了synchronized。进入addCount方法看看,
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
} 可以看出,修改table大小时使用了CAS算法。
4、总结
看完ConcurrentHashMap整个类的源码,给自己的感觉就是和HashMap的实现基本一模一样,当有修改操作时借助了 synchronized 来对table[i]进行锁定保证了线程安全以及使用了CAS来保证原子性操作,其它的基本一致
例如:ConcurrentHashMap的 get(int key) 方法的实现思路为:根据key的hash值找到其在table所对应的位置i,然后在table[i]位置所存储的链表(或者是树)进行查找是否有键为key的节点,如果有,则返回节点对应的value,否则返回null。思路是不是很熟悉,是不是和HashMap中该方法的思路一样。所以,如果你也在看ConcurrentHashMap的源码,不要害怕,思路还是原来的思路,只是多了些许东西罢了。
4、ConcurrentSkipListMap
1、概述
ConcurrentSkipListMap 是线程安全的有序的哈希表。
与同是有序的哈希表TreeMap相比:
- ConcurrentSkipListMap是线程安全的,TreeMap则不是,
- ConcurrentSkipListMap是通过跳表(skip list)实现的,而TreeMap是通过红黑树实现的。
至于为什么ConcurrentSkipListMap不像TreeMap一样使用红黑树结构,在ConcurrentSkipListMap源码中Doug Lea已经给出解释:
原因在于,对于搜索树,目前还没有有效的无锁插入和删除算法。
2、跳表(skip list)
传统意义的单链表是一个线性结构,向有序的链表中插入一个节点需要O(n)的时间,查找操作需要O(n)的时间。
具体请查阅
5、BlockingQueue
1、概述
Java 5 提供了一个 BlockingQueue 接口,虽然也是 Queue 的子接口,但是他的主要作用不是作为容器而是作为线程的同步工具:
- 当生产者线程向队列中添加元素时,如果队列已满,则该线程阻塞
- 当消费者线程视图从队列中取出元素时,如果该队列已空则该线程阻塞
当程序的多个线程,交替着向队列中添加、取出元素,可以很好的控制通信
//支持阻塞的两个方法
//将指定的元素插入此队列的尾部,如果该队列已满,则一直等到(阻塞)。
void put(E e) throws InterruptedException;
//获取并移除此队列的头部,如果没有元素则等待(阻塞),
//直到有元素将唤醒等待线程执行该操作
E take() throws InterruptedException; //将指定的元素插入到此队列的尾部(如果立即可行且不会超过该队列的容量)
//在成功时返回 true,如果此队列已满,则抛IllegalStateException。
boolean add(E e);
//将指定的元素插入到此队列的尾部(如果立即可行且不会超过该队列的容量)
// 将指定的元素插入此队列的尾部,如果该队列已满,
//则在到达指定的等待时间之前等待可用的空间,该方法可中断
boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException;
//获取并移除此队列的头部,在指定的等待时间前一直等到获取元素, //超过时间方法将结束
E poll(long timeout, TimeUnit unit) throws InterruptedException;
//从此队列中移除指定元素的单个实例(如果存在)。
boolean remove(Object o);
}
//除了上述方法还有继承自Queue接口的方法
//获取但不移除此队列的头元素,没有则跑异常NoSuchElementException
E element();
//获取但不移除此队列的头;如果此队列为空,则返回 null。
E peek();
//获取并移除此队列的头,如果此队列为空,则返回 null。
E poll();2、ArrayBlockingQueue
ArrayBlockingQueue是一个基于数组的有界阻塞队列:
- 有界”表示数组容量是固定的。这是一个典型的“有界缓存区”,固定大小的数组在其中保持生产者插入的元素和使用者提取的元素。
- 试图向已满队列中放入元素会导致操作受阻塞
- 试图从空队列中提取元素将导致类似阻塞。
- ArrayBlockingQueue内部的阻塞队列是通过重入锁ReenterLock和Condition条件队列实现的,所以存在公平访问跟非公平访问的区别
源码分析
3、LinkedBlockingQueue
LinkedBlockingQueue是一个基于单向链表的、可指定大小的阻塞队列。
可选的容量范围构造方法参数作为防止队列过度扩展的一种方法。如果未指定容量,则它等于 Integer.MAX_VALUE。除非插入节点会使队列超出容量,否则每次插入后会动态地创建链接节点。
emmm 操作还是跟上面是一样的,就是长度不限制而已
4、LinkedBlockingDeque
LinkedBlockingDeque是一个基于链表的、可指定大小的阻塞双端队列:
- “双端队列”意味着可以操作队列的头尾两端
- 所以LinkedBlockingDeque既支持FIFO,也支持FILO。
5、ConcurrentLinkedQueue
ConcurrentLinkedQueue是一个基于链表的、无界的、线程安全的队列:
- 此队列按照FIFO原则对元素进行排序
- 此队列不允许使用null元素,采用CAS算法
//构造方法摘要
ConcurrentLinkedQueue()
//创建一个最初为空的 ConcurrentLinkedQueue。
ConcurrentLinkedQueue(Collection c)
//创建一个最初包含给定 collection 元素的 ConcurrentLinkedQueue,按照此 collection 迭代器的遍历顺序来添加元素。
//方法摘要
boolean add(E e)
//将指定元素插入此队列的尾部。
boolean contains(Object o)
//如果此队列包含指定元素,则返回 true。
boolean isEmpty()
//如果此队列不包含任何元素,则返回 true。
Iterator iterator()
//返回在此队列元素上以恰当顺序进行迭代的迭代器。
boolean offer(E e)
//将指定元素插入此队列的尾部。
E peek()
//获取但不移除此队列的头;如果此队列为空,则返回 null。
E poll()
//获取并移除此队列的头,如果此队列为空,则返回 null。
boolean remove(Object o)
//从队列中移除指定元素的单个实例(如果存在)。
int size()
//返回此队列中的元素数量。
Object[] toArray()
//返回以恰当顺序包含此队列所有元素的数组。
T[] toArray(T[] a)
//返回以恰当顺序包含此队列所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。 6、SynchronusQueue
作为 BlockingQueue 中的一员,SynchronousQueue 与其他 BlockingQueue 有着不同特性:
- SynchronousQueue没有容量。与其他BlockingQueue不同,SynchronousQueue是一个不存储元素的BlockingQueue。每一个put操作必须要等待一个take操作,否则不能继续添加元素,反之亦然。
- 因为没有容量,所以对应 peek, contains, clear, isEmpty … 等方法其实是无效的。例如clear是不执行任何操作的,contains始终返回false,peek始终返回null。
- SynchronousQueue分为公平和非公平,默认情况下采用非公平性访问策略,当然也可以通过构造函数来设置为公平性访问策略(为true即可)。
- 若使用 TransferQueue, 则队列中永远会存在一个 dummy node(这点后面详细阐述)。
SynchronousQueue非常适合做交换工作,生产者的线程和消费者的线程同步以传递某些信息、事件或者任务。
public class T09_SynchronusQueue {
public static void main(String[] args) throws InterruptedException {
//容量为0的队列,来的东西必须马上消费掉否则会出问题
BlockingQueue strs = new SynchronousQueue<>();
new Thread(()->{
try {
System.out.println(strs.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
//阻塞等待消费者消费
strs.put("aaa");
//不能调用add方法
//strs.add("aaa");
System.out.println(strs.size());
}
}
7、LinkedTransferQueue
public class T08_TransferQueue {
public static void main(String[] args) throws InterruptedException {
//更高的线程并发的时候
LinkedTransferQueue strs = new LinkedTransferQueue<>();
//消费者
/*new Thread(() -> {
try {
System.out.println(strs.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();*/
//使用 transfer的话,是直接给消费者线程,不给容器
//如果容器这时满了,那么就会阻塞
//strs.transfer("aaa");
strs.put("aaa");
//生产者
new Thread(() -> {
try {
System.out.println(strs.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}