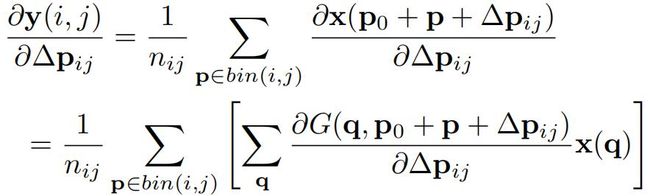Deformable CNNs论文笔记
个人博客:http://www.chenjianqu.com/
原文链接:http://www.chenjianqu.com/show-114.html
论文:17 Mar 2017.Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, Yichen Wei.MSRA.Deformable Convolutional Networks
素质三连
1.论文贡献
提出可变形卷积(Deformable convolution)和可变形RoI池化(Deformable RoI Pooling)
2.实验结果
将现存的语义分割模型和目标检测模型转换为可变形卷积神经网络,在数据集VOC,CityScapes,COCO上分别进行实验。结果表明可变形卷积额外增加的计算量不大,但是精度确实明显提升。
3.存在的问题
实现起来略复杂
摘要
卷积神经网络(CNNs)由于卷积核的固定的几何结构,在建模几何变换中具有局限性。本工作提出两个新的模块用于提高CNNs建模几何变换的能力,称之为可变形卷积和可变形RoI池化。这个两个模块的设计思路是:在没有额外监督的情况下,使用附加偏移量来增强模块中的空间采样位置,并从目标任务中学习偏移量。这两个模块可以轻易的替换现有CNNs中对应的模块,而且可以标准反向传播端到端训练。从而获得一个可变形卷积神经网络。我们对该方法进行了广泛的实验验证。首次证明了深度CNNs中学习稠密空间变换对于复杂的视觉任务比如目标检测和语义分割是有效的。代码开源在:https://github.com/msracver/Deformable-ConvNets.
引言
CV中一个很重要的问题是模型如何适应目标几何变形或目标尺度、位姿、视角的变化,通常有两种方式。第一种方式是构建一个包含足够多目标的变形的数据集,这通常通过数据增强实现。这需要大量的参数和昂贵的训练,最终可以从数据中学习到鲁棒的表示。第二种方法是使用具有变换不变性的特征和算法,比如SIFT和基于滑动窗口的目标检测范式。
上面的方法中有两个缺点,首先是要假设几何变形是固定和已知的。比如需要通过先验知识增强数据和设计特征、算法。这样难以建模存在未知几何变换的新任务。其次,手工设计具有不变性的特征和算法对于复杂变换来说可能是困难或不可行的。
当前流行的深度神经网络模型CNNs同样具有上述缺点,在建模大的、未知的变换时存在困难。这种困难来源于卷积操作的固定的几何结构:卷积运算采样的位置是固定的;池化操作以固定的比例减小空间分辨率;RoI池化分离RoI至固定的空间块。
CNNs缺少内部的机制处理几何变换,这会导致一些问题。第一个例子,同一卷积层中所有激活单元的感受野相同,这对于高层卷积层来说是不希望的,高层卷积层需要编码高层次语义信息。因为不同位置可能对应不同尺度、形状的目标,因此对于需要精确定位的任务来说需要自适应确定尺度和感受野的大小,比如语义分割使用FCN。另一个例子是,当前先进的目标检测算法都依赖于基于原始包围框的特征抽取,这很明显不是最优的,尤其对于非刚性目标。
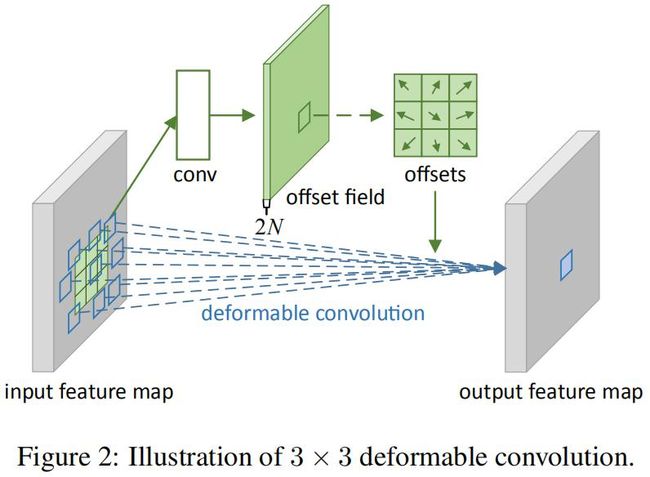
本工作提出了两个新的模块,极大的提升了CNNs对于建模几何形变的能力。第一个模块是可变形卷积,它对标准卷积中规则的网格采样位置增加2D的偏移,允许采样网格自由的变形。如下图:

偏移量通过附加的卷积层得来。由此,卷积的变形以局部、稠密、自适应的方式取决于输入特征。
第二个模块是可变形RoI池化,为每个bin位置增加一个偏移量。类似的,偏移量从特征图和RoI中学习而来,从而能对不同形状的目标自适应定位。
两个模块都是轻量的,只增加了很小的计算量。可以替换普通CNNs对应的卷积和RoI池化层,而且可以标准反向传播进行端对端训练。根据这两个模块构建的CNNs称之为deformable convolational networks或deformable ConvNets,即可变形的卷积神经网络。
可变形卷积神经网络
可变形卷积
这里以2D卷积为例。2D卷积由两部分组成:1)在特征图x的规则网格R中采样,2)采样值乘以卷积核权重w,并求和。网格R由感受野大小和膨胀系数确定,比如3x3卷积、膨胀系数为1的网格R定义为R={(-1,-1),(-1,0),...,(0,1),(1,1)}。对于输出特征图中的每个位置p0,有:

在可变形卷积中,R可以通过偏置 {Δpn | n=1,...,N} ,N=|R| 变形,则上式可变形为:

由此,采样位置不再是规则的,偏置 Δpn通常是浮点数。该偏置后的浮点数像素坐标的像素值可以通过双线性插值获取:
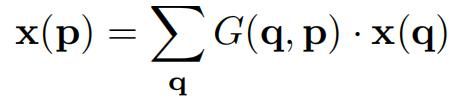
式中的 p 是增加偏置后的像素坐标,q 是浮点数坐标 p 周围的整数坐标,一共有四个。G(.,.)是双线性插值核。G(q,p)=g(qx,px) * g(qy,py),g(a,b)=max(0,1-|a-b|) 。
这里需要明确的一个问题是,这里的deforamable针对的不是卷积核,而是输入特征图。也就是说,输出特征图的每个位置的每个通道,都有一个对应的偏置。偏置可以通过offset field获取。offset field是一个附加的卷积层,学习的输入特征图每个位置的激活值。比如输入特征图的shape=(b,w,h,c),则对应的offset field的shape=(b,w,h,2c),2c即每个激活值都有2的偏置值:x和y。下图是简化为2D的可变形卷积过程:
为了学习到这些偏置,反向传播通过上面的双线性插值公式得到梯度。在2D情况下,输出特征值 y(p0) 相对于偏置 Δpn的导数为:

其中 ∂G(q,p0+pn+Δpn) / ∂Δpn可以通过进行推导。
可变形RoI池化
RoI池化最先最先提出于Fast R-CNN,广泛用于所有的基于区域生成的目标检测方法。RoI池化可以将不同大小的RoI转换为固定大小的特征。在给定输入特征图x,RoI的大小为 w*h ,RoI左上角为 p0。RoI池化将RoI划分为k*k个bin,输出k*k大小的特征图。对于特征图的第(i,j)个bin,有:

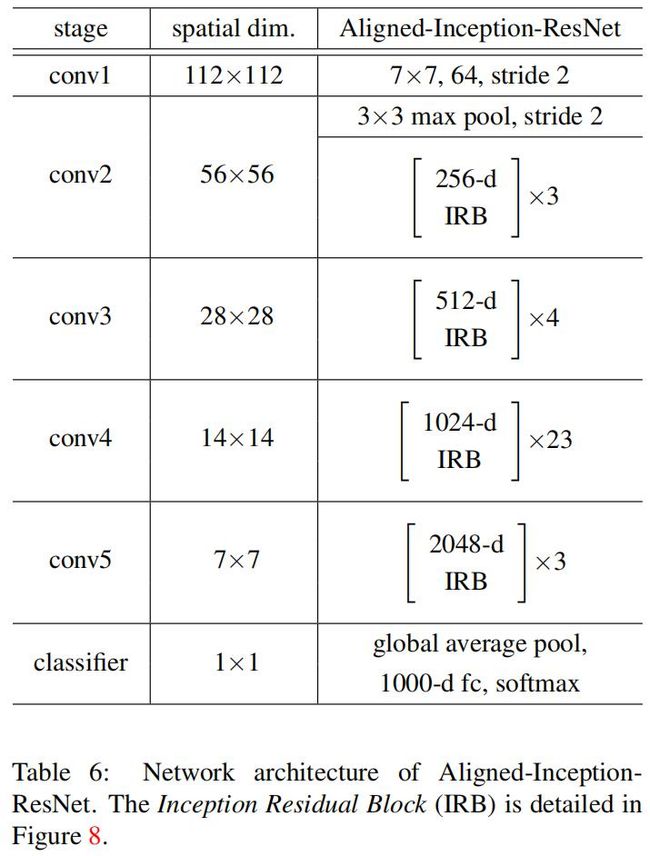
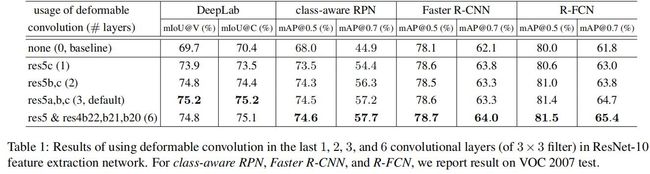
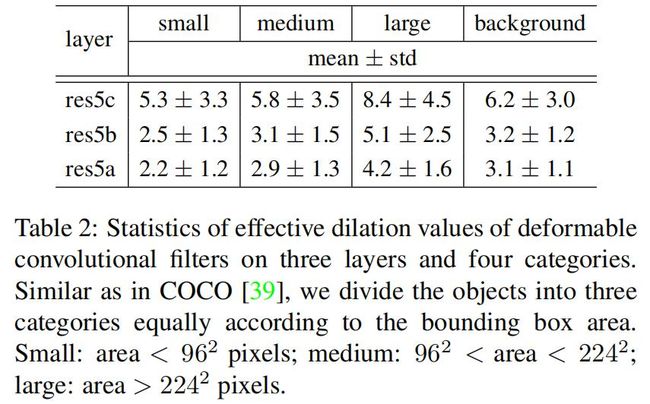
其中nij是该bins的像素数。第(i,j)个bin跨越 floor(i*w/k ) 通常 Δpij是浮点数,可以像可变形池化那样进行双线性插值。可变形RoI池化的过程为: 首先,RoI池化产生池化后的特征图。从这些特征图中,fc层生成归一化偏移 Δ^pij,然后根据公式 Δpij=λ*Δ^pij◦(w,h) 得到Δpij,其中λ是预定义的系数用于控制偏置的大小。这里经验性的设置 λ=0.1。为了使偏移对于RoI大小具有不变性,归一化偏移是必要的。 Fc层可以通过反向传播进行学习。类似与可变形卷积,可变形RoI池化模块,偏置 Δpij的梯度为: 归一化偏移的 Δ^pij的梯度很容易根据Δpij=λ*Δ^pij◦(w,h)求导得到。 位置敏感的RoI池化 R-FCN提出的方法,我没看过这篇论文,因此这里先忽略。 可变形卷积神经网络 可变形卷积和可变形RoI都跟普通的卷积和RoI有相同的输入和输出形式。因此可以直接对现存的模型中对应的层进行替换。用于学习偏移的附加的卷积层和fc层使用0进行初始化。学习率设置为该层学习率的 β 倍(默认设置β=1,对于Faster R-CNN的fc层设置β=0.01)。这种卷积神经网络模型称为可变形卷积神经网络。 特征抽取网络应用可变形卷积 作者由两个SOTA的backbone:ResNet101[Deep residual learning for image recognition]和Inception-ResNet[Inceptionv4,inception-resnet and the impact of residual connections on learning]。这两个网络都在ImageNet上进行了预训练。 最初版本的Inception-ResNet是用于图像分类的。因此如果直接用于稠密预测任务的话会存在特征误对齐问题。这里存在一个改进版本Aligned-Inception-ResNet,细节如下: 其中IRB如下: ResNet101和Aligned-Inception-ResNet都是由几个卷积块、一个平均池化和一个1000-way的fc层组成。这里去掉平均池化层和fc层,在最后增加一个随机初始化的1x1卷积将通道数减小到1024。 可变形卷积应用到DeepLab语义分割模型,class-aware RPN、Faster R-CNN、R-FCN目标检测模型的backbone:ResNet101中不同的卷积层,结果如下: 可变形卷积神经网络的理解 本工作的idea是从任务中学习偏置来增强卷积和RoI池化的采样位置。下图展示了可变形卷积与标准卷积的对比。 上图的左边是标准卷积,右边是可变形卷积。标准卷积中的感受野和采样位置在顶部特征图上都是固定的,而可变形卷积根据目标的大小和形状进行自适应调整。 下表定量展示了可变形卷积的能力: 可变形RoI的效果类似,如下图: 上图中黄框表示RoI,而红框是bin,每个RoI划分为9个bin。可以看到完全没有了普通RoI池化那种规则池化的亚子了,bin都移到目标附近了。模型的定位能力得到提高,尤其是对不规则的物体。 相关工作 STN,Active Convolution,Effective Receptive Field,Atrous convolution,DPM,DeepID-Net,Spatial manipulation in RoI pooling,平移不变特征:SIFT,ORB,Dynamic Filter,Combination of low level filters 实验 实验设置和实现 语义分割配置:数据集使用PASCAL VOC和CityScapes。使用mIoU@V作为PASCAL VOC的评估指标,mIoU@C作为Cityscapes的评估指标。训练和推断时,将PASCAL VOC图片的短边缩放至360,Cityscapes缩放置1024。迭代次数分别是30k和45k,batch_size=1,使用8GPUs训练。前2/3迭代的学习率是10^-3,后1/3的学习率是1/3。 目标检测配置:数据集使用PASCAL VOC和COCO,使用mAP指标。VOC的IoU阈值为0.5和0.7。对于COCO数据集,使用mAP@[0.5,0.95]和[email protected]。训练和推断时,将图片的短边缩放至600,batch_size=1。 消融实验 可变形卷积 下图是可变形卷积的可视化结果: 可知: 1)可变形卷积核的感受野与目标大小相同,表明可以有效的从图像内容中学习到变形。 2)背景区域中的卷积核大小在中等目标和大型目标之间,表明识别背景区域需要一个相对较大的感受野。 ResNet101在最后3个3x3卷积层默认使用 膨胀系数=2的空洞卷积,作者还尝试了其它dilation值:4,6,8,结果如下: 结果表明: 1)当使用较大的膨胀系数时,所有任务的精度都提高了,这表明默认的ResNet的感受野太小。 2)不同任务最佳膨胀系数不同。 3)可变形卷积具有最佳的膨胀系数。 模型复杂度和运行时间 从下表中可以看到,相对于原模型,替换可变形卷积神经网络额外增加的参数和计算量很小。 COCO上的目标检测对比