PWN学习整理栈溢出到堆利用(含举例)
文章将整理从入门栈溢出到堆house系列的梳理。
0x01栈知识
call
将当前的IP或者CS和IP压入栈中。
转移
汇编:call xxx
push IP
jmp xxx
ret
将程序的返回地址弹出到ip寄存器中
程序继续执行
汇编:
pop IP
有call就要有传参,32位系统用栈来传参参数是倒着传进去也就是最后的参数先push
64位系统用寄存器来传参前三个参数是用rdi,rsi,rdx
32位函数调用(__cdecl 调用约定)
C语言函数
write(1, "Hello, World!\n", 0xEu);
汇编语言
push 0Eh ; n 传递第三个参数
push offset aHelloWorld ; "Hello, World!\n" 第二个参数
push 1 ; fd 第一个参数
call _write
add esp, 10h 在call返回之后平衡堆栈
64位传参
read(0, &buf,0x200uLL);
mov edx, 200h ; nbytes
mov rsi, rax ; buf
mov edi, 0 ; fd
call _read

运行时程序的栈:
上面高地址处存放的是环境变量和main函数的信息
往下是主调函数的栈内存,包括临时变量和控制信息(控制信息包括返回地址和ebp等用来保存的寄存器的值)
调用约定:
每个函数调用的时候都会自己平衡自己的堆栈。
每个被调函数被调用的时候先push ebp所以栈里面会有返回地址和ebp
两个表
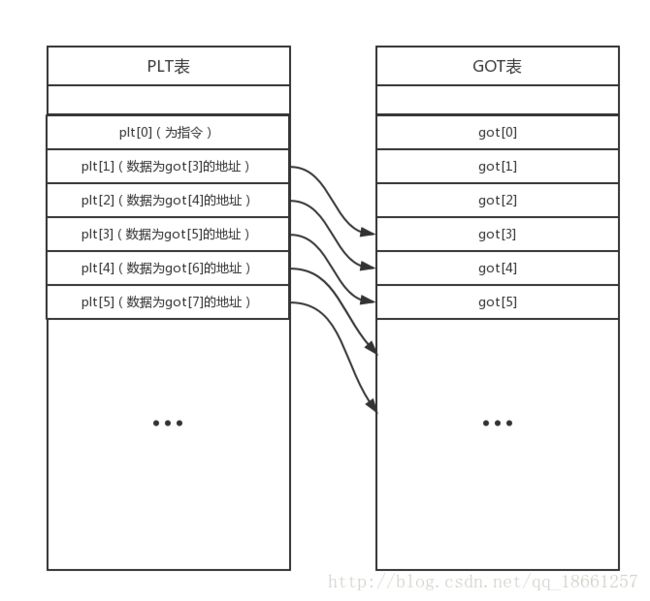 plt表:函数调用的时候先使用的。PLT表中的每一项的-数据内容都是对应的GOT表中一项的地址这个是固定不变的,PLT表中的数据是跳转到GOT表项的地址。
plt表:函数调用的时候先使用的。PLT表中的每一项的-数据内容都是对应的GOT表中一项的地址这个是固定不变的,PLT表中的数据是跳转到GOT表项的地址。
got表:一个指向真正运行函数首地址的指针。
注意函数
scanf函数
scanf("%d %d",&a,&b);
遇到空格(0x20)停止读取
read函数
ssize_t read (int fd, void *buf, size_t count);
读取数据遇到\n(0x0a)结束,\x0a会读进去
fd为0从键盘读取
gets函数
gets(str);
输入遇到\n(0x0a)结束
\x0a不会读进去
printf函数
printf("%s", i);
输出直到\x00
write函数
ssize_t write(int fd, const void *buf, size_t nbyte);
fd为1输出到显示器
puts函数
puts(char *)
相当于printf("%s\n",s)
输出字符串(遇到\x00结束)
strcpy函数
char *strcpy(char *dst, const char *src);
一直复制直到遇到\x00
memcpy函数
void *memcpy(void *dest, const void *src, size_t n);
复制任意内容
strncpy函数
char *strncpy(char *dest,char *src,int size_t n);
如果n
32位利用方式
 举例https://blog.csdn.net/qq_38204481/article/details/80944927
举例https://blog.csdn.net/qq_38204481/article/details/80944927
64位利用方式
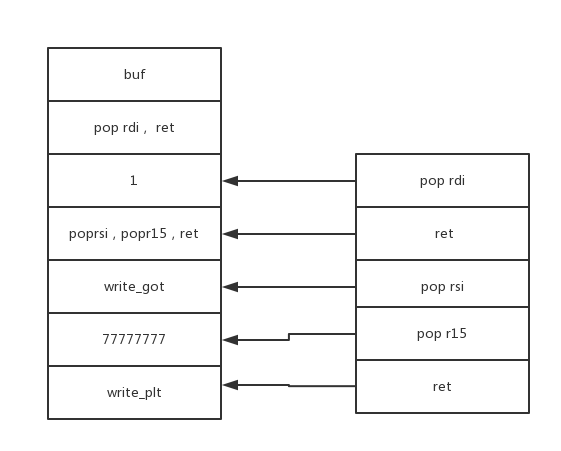 https://blog.csdn.net/qq_38204481/article/details/80955065
https://blog.csdn.net/qq_38204481/article/details/80955065
通用rop作为rop的进阶
disassemble __libc_csu_init
0x0000000000400690 <+64>: mov rdx,r13
0x0000000000400693 <+67>: mov rsi,r14
0x0000000000400696 <+70>: mov edi,r15d
0x0000000000400699 <+73>: call QWORD PTR [r12+rbx*8]
0x000000000040069d <+77>: add rbx,0x1
0x00000000004006a1 <+81>: cmp rbx,rbp
0x00000000004006a4 <+84>: jne 0x400690 <__libc_csu_init+64>
0x00000000004006a6 <+86>: add rsp,0x8
0x00000000004006aa <+90>: pop rbx
0x00000000004006ab <+91>: pop rbp
0x00000000004006ac <+92>: pop r12
0x00000000004006ae <+94>: pop r13
0x00000000004006b0 <+96>: pop r14
0x00000000004006b2 <+98>: pop r15
0x00000000004006b4 <+100>: ret
https://blog.csdn.net/qq_38204481/article/details/80984318
0x02保护
-
RELRO
介绍:got表不可写
绕过方法:hook函数,覆盖返回地址,导入shellcode
-
NX
栈内数据不可执行
不能导入shellcode
绕过方法:ROP
-
STACK
介绍:程序会在栈里面放入一个canary返回时检测canary是否发生了改变,如果改变会输出程序名字然后退出。
绕过方法:leak canary,SSP(Stack Smashes Protect),爆破canary,用格式化字符串复写check_got再触发。
-
PIE
程序加载地址随机
SSP
fork函数会复制原进程的环境,然后运行新内容。
当栈被损坏canary会打印出程序的名字,如果用覆盖掉name程序会打印出需要的数据。
但是这种方法会让程序退出,所以一般需要伴随着fork函数

https://blog.csdn.net/qq_38204481/article/details/82318179(GUESS)
leak canary

1.覆盖掉canary最后的00输出的时候会把canary输出.但是要求在泄露之后函数返回之前要获取shell
2.如果在设置数组数组的时候没有清空栈空间,保留了上次调用留下的canary也可以泄露,一般需要递归。
抬高栈帧
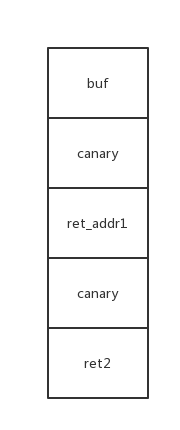 https://tower111.github.io/2018/09/09/%E7%BD%91%E9%BC%8E%E6%9D%AF4-impossible
https://tower111.github.io/2018/09/09/%E7%BD%91%E9%BC%8E%E6%9D%AF4-impossible
执行pop之后逻辑上栈内数据不存在但是物理上依然存在。
如果直接通过覆盖\x00泄露ret2的canary改变了打印出之后会退出,所以可以利用其它函数写入canary,然后leakret_addr1的canary
GOT表不可写(RELRO)
大部分函数都有一个hook函数。
以__hook_malloc为例。
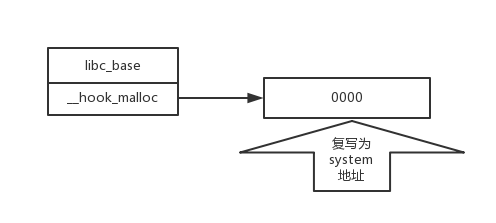
1.得到libc就能得到它的真是加载地址
默认地址设置位0,如果地址处不为0,执行malloc之前会执行这里的内容。(一般复写的是_free_hook函数)
0x03格式化字符串
输出
printf("%s %d %d %d %x %x\n",buf,a,b,c)

%s会输出buf指向的内容
三个%d会输出a,b,c
二个%x会输出继续往下的栈空间的内容

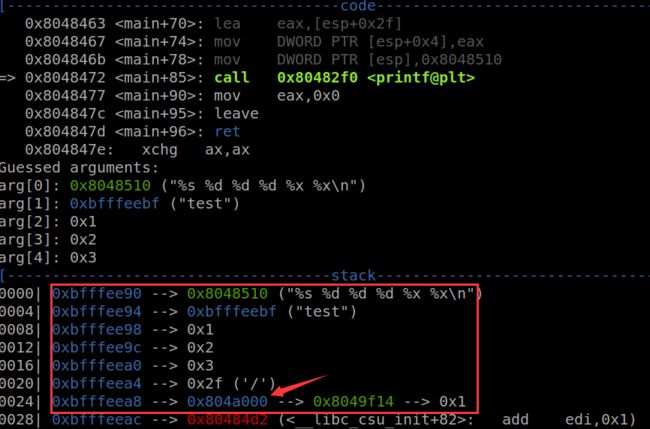
buf=test
printf(“%s %d %d %d %x %x”,buf)
如图反映了上图的输出和栈的内存。
分别输出test 1 2 3 2f 804a000
写入
%n是一个不经常用到的格式符,它的作用是把前面已经打印的长度写入某个内存地址
 可以看到我们的num值被改为了100,
可以看到我们的num值被改为了100,
这里可以看出1.用%.100可以控制写入数据是十进制100(0x64)
2.写入的地址是%n对应的参数指向的内容
补充
用%2$x(或n)可以实现定点输出(或输入)不加$
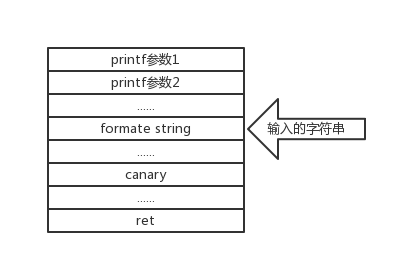
利用
用%n的字符加上got表数据可以实现复写
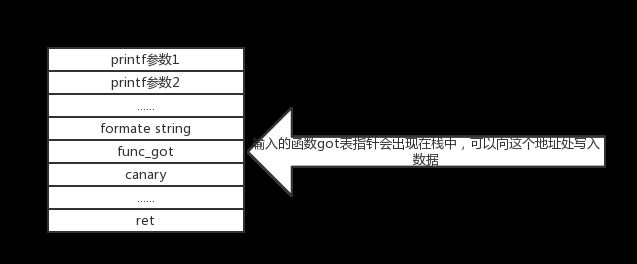 ****
****
0x04堆漏洞
分配过的chunk
- 32位机,8字节对齐,64位机,16字节对齐
- 位P指明前一个chunk的状态 空闲(0),使用(1)
- prev_size表示前一个chunk的大小
当前chunk释放时,可用于定位前一个chunk,并将两个chunk合并为一个更大的chunk
当P为1时,prev_size无意义,该区域(4B)可被前一个chunk使用

fast bin
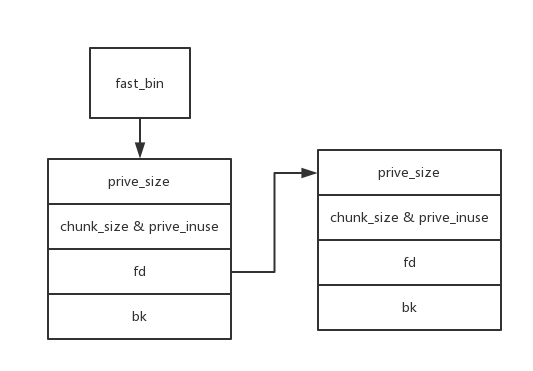 - 在chunk被free的时候如果大小小于0x80会被放入fast bin
- 在chunk被free的时候如果大小小于0x80会被放入fast bin
- 需要注意的是这里的prive_inuse位不会置0
- 可以在这里泄露出来heap的地址。(因为fd指向了下一个chunk的开始)
unsort bin
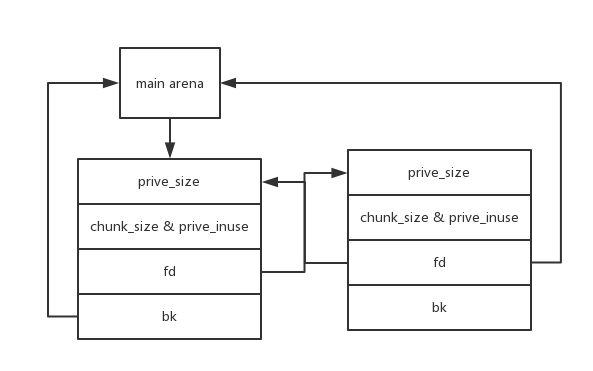
- 在chunk合并之后大于0x80或者是大于0x80的chunk被释放之后会放入unsort bin
- 这里是双向链表连接
- 其中main_arena和libc_base之间的偏移是固定的,可以用来leak libc_base
注意点
- 定义的read函数
可以输入比size多一位。
可以输入size之后又加上\x00
- free掉chunk之后指针是否清零
- 是否存在堆溢出
利用方法fastbin attack
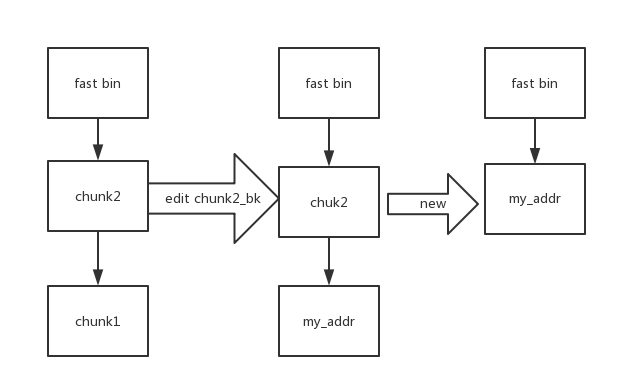 注意在申请空间时有一个size验证。
注意在申请空间时有一个size验证。
上图由
malloc(0x20) malloc(0x20)
free(1) free(2) #到这里形成上图第一列
edit(2,my_addr) #形成上图第二列
(my_addr=0x6020xx
my_addr_size=0x31)#括号内的是说明需要的条件不是代码
malloc(0x20) #形成上图第三列
malloc(0x20) #申请到伪造chunk空间
完成上述过程需要条件:
my_addr_size需要满足
1.0x80以内
2.prive_inuse为1
https://blog.csdn.net/qq_38204481/article/details/82318179
补充利用FILE结构
struct _IO_FILE_plus
{
_IO_FILE file;
IO_jump_t *vtable;
}
void * vtablt[] = {
1 NULL, // "extra word"
2 NULL, // DUMMY
3 exit, // finish
4 NULL, // overflow
5 NULL, // underflow
6 NULL, // uflow
7 NULL, // pbackfail
8 NULL, // xsputn #printf
9 NULL, // xsgetn
安装gdb的pwndbg插件用print *(struct _IO_FILE_plus*)0x6020a0命令可以输出结构
详情参考https://ctf-wiki.github.io/ctf-wiki/pwn/linux/io_file/introduction/
举例参考https://blog.csdn.net/qq_38204481/article/details/82318094(blind)
利用方式double free
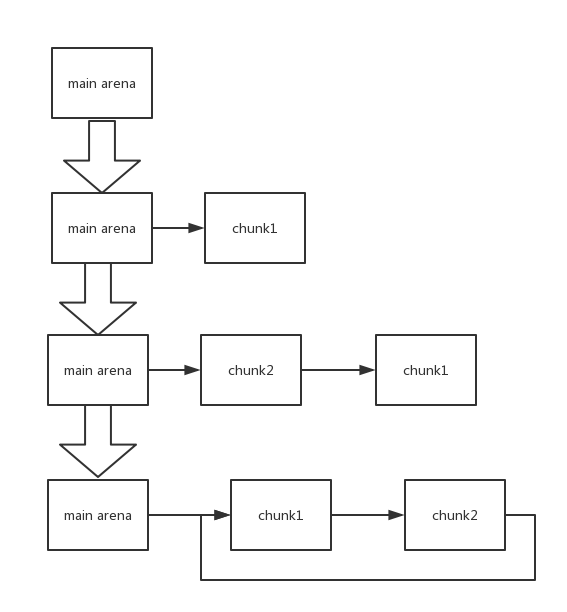
上图形成过程:
free chunk1 free chunk2 free chunk1(途中三个箭头对应三个操作)
说明
- 所谓的free其实就是数据结构里面的头插。就是一些指针的变化
- 达到上图在经过三次malloc再次malloc就能申请到想要的空间
- 限制:需要一个合适的size
举例参见https://tower111.github.io/2018/08/30/ISG-babynote/(文中提到的获取执行流的 方法总结:https://blog.csdn.net/qq_38204481/article/details/82318227)
unlink
 unlink的发生:
unlink的发生:
- glibc 判断这个块是 small chunk。
- 判断前向合并,发现前一个 chunk 处于使用状态,不需要前向合并。
- 判断后向合并,发现后一个 chunk 处于空闲状态,需要合并。
- 继而对 nextchunk 采取 unlink 操作。
可见,要进行unlink的不是刚释放的chunk而是与这个chunk物理相邻的chunk
执行函数unlink§ 可以看出:unlink函数知道的只有一个指针,函数的第一步是找到前一个逻辑相邻的chunk,后一个逻辑相邻的chunk(其实就是指针的赋值操作,包括上图描述的unlink过程)
实际上进行unlink的时候会进行一个教研P->fd->bk==P
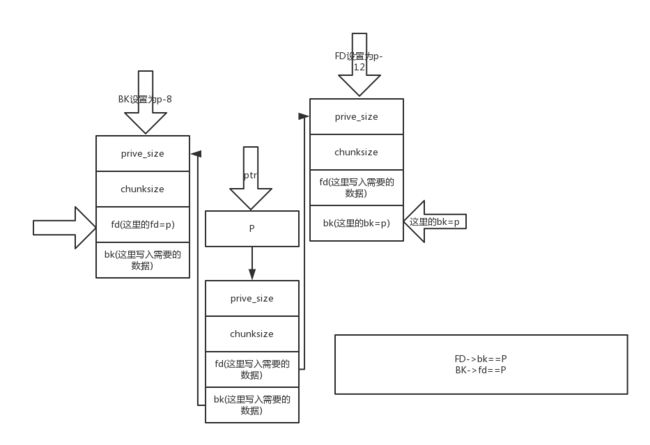 上图三列其实占了同一个空间,也就是地址是重合的,这样就能满足上述的校验
上图三列其实占了同一个空间,也就是地址是重合的,这样就能满足上述的校验

例子参考https://blog.csdn.net/qq_38204481/article/details/82808011
0x05补充堆分配与释放过程
内存分配
内存释放