深入理解YOLO v3实现细节 - 第1篇 数据预处理
深入理解YOLO v3实现细节系列文章,是本人根据自己对YOLO v3原理的理解,结合开源项目tensorflow-yolov3,写的学习笔记。如有不正确的地方,请大佬们指出,谢谢!
YunYang1994 tensorflow-yolov3的开源项目地址:YunYang1994/tensorflow-yolov3github.com
深入理解YOLO v3实现细节系列
第1篇 数据预处理
第2篇 backbone&network
第3篇 构建v3的Loss_layer
目录
第1篇 数据预处理
1. 定义初始化函数
2.数据增强
3. 获取真实框(GroundTruth)的坐标和类别信息
3.1 读取真实框的注释(annotations)文件
3.2 获取真实框的坐标和类别信息
4. 获取3种不同尺寸的label和真实框
4.1 定义IOU计算公式
4.2 先验框(anchor box)的来源
4.3 定义preprocess_true_boxes函数
5. 将像素矩阵、label和真实框打包成mini_batch
补充
1. 定义初始化函数
参数初始化,参数的配置来自config.py
"""implement Dataset here"""
def __init__(self, dataset_type):
# 根据dataset_type的值,选择训练/测试的参数
# 数据注释文件的路径,此处为"./data/dataset/voc_test.txt" 或 "./data/dataset/voc_train.txt"
self.annot_path = cfg.TRAIN.ANNOT_PATH if dataset_type == 'train' else cfg.TEST.ANNOT_PATH
# 数据输入图像的大小,为了增加网络的鲁棒性,使用了随机[320, 352, 384, 416, 448, 480, 512, 544, 576, 608]
# 中任意一种大小,注意,该处必须为32的倍数
self.input_sizes = cfg.TRAIN.INPUT_SIZE if dataset_type == 'train' else cfg.TEST.INPUT_SIZE
self.batch_size = cfg.TRAIN.BATCH_SIZE if dataset_type == 'train' else cfg.TEST.BATCH_SIZE
# 数据增强
self.data_aug = cfg.TRAIN.DATA_AUG if dataset_type == 'train' else cfg.TEST.DATA_AUG
# 训练数据输入大小
self.train_input_sizes = cfg.TRAIN.INPUT_SIZE
# 3中下采样方式,为[8, 16, 32]
self.strides = np.array(cfg.YOLO.STRIDES)
# 训练数据的类别,使用VOC数据共20中,来自"./data/classes/voc.names"
self.classes = utils.read_class_names(cfg.YOLO.CLASSES)
# 种类的数目,针对VOC为20
self.num_classes = len(self.classes)
# 来自于"./data/anchors/basline_anchors.txt",该文件的生成于docs/Box-Clustering.ipynb
self.anchors = np.array(utils.get_anchors(cfg.YOLO.ANCHORS))
# 对每个gred(网格)预测几个box,该处为3
self.anchor_per_scale = cfg.YOLO.ANCHOR_PER_SCALE
# 每一下采样的最大Bounding box数量
self.max_bbox_per_scale = 150
# 根据dataset_type的类型,读取"./data/classes/voc_train.txt"或"./data/classes/voc_test.txt"中的内容
self.annotations = self.load_annotations(dataset_type)
# 计算训练样本的总数目
self.num_samples = len(self.annotations)
# 计算需要多少个mini_batchs才能完成一个EPOCHS
self.num_batchs = int(np.ceil(self.num_samples / self.batch_size))
# 当batch_count达到num_batchs代表训练了一个EPOCHS
self.batch_count = 02.数据增强
2.1 随机水平翻转
def random_horizontal_flip(self, image, bboxes):
# random.random()方法返回一个随机数,其在0至1的范围之内
if random.random() < 0.5:
_, w, _ = image.shape
# [::-1] 顺序相反操作
# a = [1, 2, 3, 4, 5]
# a[::-1]
# Out[3]: [5, 4, 3, 2, 1]
image = image[:, ::-1, :]
bboxes[:, [0,2]] = w - bboxes[:, [2,0]]
return image, bboxes2.2 随机剪裁
def random_crop(self, image, bboxes):
if random.random() < 0.5:
h, w, _ = image.shape
max_bbox = np.concatenate([np.min(bboxes[:, 0:2], axis=0), np.max(bboxes[:, 2:4], axis=0)], axis=-1)
max_l_trans = max_bbox[0]
max_u_trans = max_bbox[1]
max_r_trans = w - max_bbox[2]
max_d_trans = h - max_bbox[3]
crop_xmin = max(0, int(max_bbox[0] - random.uniform(0, max_l_trans)))
crop_ymin = max(0, int(max_bbox[1] - random.uniform(0, max_u_trans)))
crop_xmax = max(w, int(max_bbox[2] + random.uniform(0, max_r_trans)))
crop_ymax = max(h, int(max_bbox[3] + random.uniform(0, max_d_trans)))
image = image[crop_ymin : crop_ymax, crop_xmin : crop_xmax]
bboxes[:, [0, 2]] = bboxes[:, [0, 2]] - crop_xmin
bboxes[:, [1, 3]] = bboxes[:, [1, 3]] - crop_ymin
return image, bboxes2.3 随机旋转
def random_translate(self, image, bboxes):
if random.random() < 0.5:
h, w, _ = image.shape
max_bbox = np.concatenate([np.min(bboxes[:, 0:2], axis=0), np.max(bboxes[:, 2:4], axis=0)], axis=-1)
max_l_trans = max_bbox[0]
max_u_trans = max_bbox[1]
max_r_trans = w - max_bbox[2]
max_d_trans = h - max_bbox[3]
tx = random.uniform(-(max_l_trans - 1), (max_r_trans - 1))
ty = random.uniform(-(max_u_trans - 1), (max_d_trans - 1))
M = np.array([[1, 0, tx], [0, 1, ty]])
image = cv2.warpAffine(image, M, (w, h))
bboxes[:, [0, 2]] = bboxes[:, [0, 2]] + tx
bboxes[:, [1, 3]] = bboxes[:, [1, 3]] + ty
return image, bboxes3. 获取真实框(GroundTruth)的坐标和类别信息
3.1 读取真实框的注释(annotations)文件
根据dataset_type的值选取文件路径
self.annot_path = cfg.TRAIN.ANNOT_PATH if dataset_type == 'train' else cfg.TEST.ANNOT_PATH定义load_annotations函数
# 根据dataset_type的类型,读取"./data/classes/voc_train.txt"或"./data/classes/voc_test.txt"中的内容
def load_annotations(self, dataset_type):
with open(self.annot_path, 'r') as f:
txt = f.readlines()
annotations = [line.strip() for line in txt if len(line.strip().split()[1:]) != 0]
# 打乱annotations中信息的排序
np.random.shuffle(annotations)
return annotations调用load_annotations函数,加载并读取注释文件
self.annotations = self.load_annotations(dataset_type)
3.2 获取真实框的坐标和类别信息
先来看看注释文件是长什么样子的,方便后面理解

def parse_annotation(self, annotation):
# 参照上图,以(D:/VOC\train/VOCdevkit/VOC2007\JPEGImages\000017.jpg 185,62,279,199,14 90,78,403,336,12)作为例子讲解
# 空格作为分隔符,将annotation分为'D:/VOC\train/VOCdevkit/VOC2007\JPEGImages\000017.jpg','185,62,279,199,14', '90,78,403,336,12'
line = annotation.split()
# 获取图片路径 'D:/VOC\train/VOCdevkit/VOC2007\JPEGImages\000017.jpg'
image_path = line[0]
if not os.path.exists(image_path):
raise KeyError("%s does not exist ... " %image_path)
# 获取图片像素矩阵
image = np.array(cv2.imread(image_path))
# for box in line[1:]跳过图片路径,从第一个box开始逐个box进行分隔
# box.split(',')以','为分隔符,将剩余的字符串分为('185','62','279','199','14'),('90','78','403','336','12')
# map函数进行取整,然后将list列表转化为数组
bboxes = np.array([list(map(int, box.split(','))) for box in line[1:]])
# 根据data_aug的值,判断是否数据增强
if self.data_aug:
image, bboxes = self.random_horizontal_flip(np.copy(image), np.copy(bboxes))
image, bboxes = self.random_crop(np.copy(image), np.copy(bboxes))
image, bboxes = self.random_translate(np.copy(image), np.copy(bboxes))
image, bboxes = utils.image_preporcess(np.copy(image), [self.train_input_size, self.train_input_size], np.copy(bboxes))
# 最后返回图片矩阵和真实框信息(x_min, y_min, x_max, y_max,class_id)
return image, bboxesparse_annotation函数返回的是一张图片的像素信息,以及box和class_id(一张图片可能存在多个真实框)。为了更加清晰理解,我写了一小段的测试代码。
annotation = load_annotations(dataset_type)
# 获取第3张图片的注释(索引不超过16551)
line = annotation[2].split()
print(line)
# 输出注释['.../2009_002584.jpg', '31,256,375,500,14', '115,32,237,98,15', '43,133,296,284,15']
image_path = line[0]
image = np.array(cv2.imread(image_path))
print(image.shape)
# 输出随机数据增强后的图片形状(500, 375, 3)
bboxes = np.array([list(map(int, box.split(','))) for box in line[1:]])
print(bboxes.shape)
print(bboxes)
# bboxes的形状(3, 5)
[[ 31 256 375 500 14]
[115 32 237 98 15]
[ 43 133 296 284 15]]图片进行数据增强后,形状发生改变,因而真实框的大小也要改变。使用image_preporcess函数进行相关预处理,其定义在utils.py中,在 第2篇 backbone&network2.2准备图片 中有详细讲解。
4. 获取3种不同尺寸的label和真实框
4.1 定义IOU计算公式
对于IOU不了解的同学可以参考我写的这篇文章:目标检测中的IOU&升级版GIOU
def bbox_iou(self, boxes1, boxes2):
# boxes = [b_x, b_y, b_w, b_h]
# b_x, b_y 表示的是以网格左上角为原点的物体中心坐标
# b_h 和 b_w 分别表示预测框的长宽
boxes1 = np.array(boxes1)
boxes2 = np.array(boxes2)
#分别计算boxes1和boxes2的面积,area = w * h
boxes1_area = boxes1[..., 2] * boxes1[..., 3]
boxes2_area = boxes2[..., 2] * boxes2[..., 3]
# 中心坐标分别减去宽高的一半,计算boxes1左上角坐标(x1,y1):
# 中心坐标分别加上宽高的一半,计算boxes1右下角坐标(x2,y2):
# 通过np.concatenate()数组拼接函数将2个坐标拼接一个数组([x1,y1,x2,y2])
boxes1 = np.concatenate([boxes1[..., :2] - boxes1[..., 2:] * 0.5,
boxes1[..., :2] + boxes1[..., 2:] * 0.5], axis=-1)
boxes2 = np.concatenate([boxes2[..., :2] - boxes2[..., 2:] * 0.5,
boxes2[..., :2] + boxes2[..., 2:] * 0.5], axis=-1)
# 计算交集的左上角坐标
left_up = np.maximum(boxes1[..., :2], boxes2[..., :2])
# 计算交集的右下角坐标
right_down = np.minimum(boxes1[..., 2:], boxes2[..., 2:])
# 计算交集区域的宽高,如果right_down - left_up < 0,没有交集,宽高设置为0
inter_section = np.maximum(right_down - left_up, 0.0)
# 交集面积等于交集区域的宽 * 高
inter_area = inter_section[..., 0] * inter_section[..., 1]
# 计算并集面积
union_area = boxes1_area + boxes2_area - inter_area
# 计算IOU
return inter_area / union_area
4.2 先验框(anchor box)的来源
对于这点,作者在 YOLOv2 论文里给出了很好的解释:
we run k-means clustering on the training set bounding boxes to automatically find good priors.其实就是使用 k-means 算法对训练集上的 boudnding box 尺度做聚类。此外,考虑到训练集上的图片尺寸不一,因此对此过程进行归一化处理。
k-means 聚类算法有个坑爹的地方在于,类别的个数需要人为事先指定。这就带来一个问题,先验框 anchor 的数目等于多少最合适?一般来说,anchor 的类别越多,那么 YOLO 算法就越能在不同尺度下与真实框进行回归,但是这样就会导致模型的复杂度更高,网络的参数量更庞大。
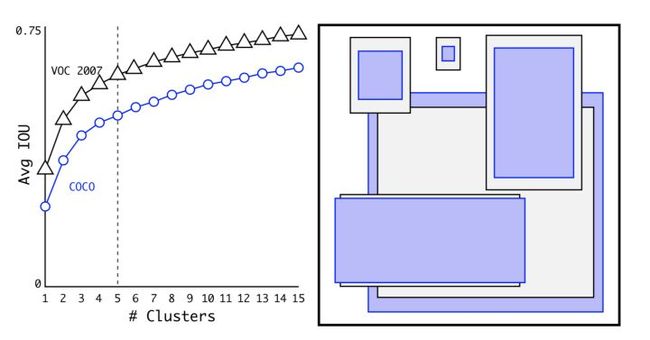
We choose k = 5 as a good tradeoff between model complexity and high recall. If we use 9 centroids we see a much higher average IOU. This indicates that using k-means to generate our bounding box starts the model off with a better representation and makes the task easier to learn.
在上面这幅图里,作者发现 k = 5 时就能较好地实现高召回率与模型复杂度之间的平衡。由于在 YOLOv3 算法里一共有3种尺度预测,因此只能是3的倍数,所以最终选择了 9 个先验框。这里还有个问题需要解决,k-means 度量距离的选取很关键。距离度量如果使用标准的欧氏距离,大框框就会比小框产生更多的错误。在目标检测领域,我们度量两个边界框之间的相似度往往以 IOU 大小作为标准。因此,这里的度量距离也和 IOU 有关。
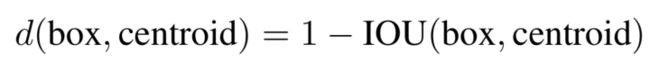
IOU计算公式
如果两个边界框之间的
IOU值越大,那么它们之间的距离就会越小。
那么,K-means 的作用有多大?
参考代码 kmeans-anchor-boxes/kmeans.py
def kmeans(boxes, k, dist=np.median,seed=1):
"""
计算k-均值聚类与交集的联合(IoU)指标
:param boxes:形状(r, 2)的numpy数组,其中r是行数
:param k: 集群的数量
:param dist: 距离函数
:返回:形状的numpy数组(k, 2)
"""
rows = boxes.shape[0]
distances = np.empty((rows, k)) ## N row x N cluster
last_clusters = np.zeros((rows,))
np.random.seed(seed)
# 将集群中心初始化为k个项
clusters = boxes[np.random.choice(rows, k, replace=False)]
while True:
# 为每个点指定聚类的类别(如果这个点距离某类别最近,那么就指定它是这个类别)
for icluster in range(k): # I made change to lars76's code here to make the code faster
distances[:,icluster] = 1 - iou(clusters[icluster], boxes)
nearest_clusters = np.argmin(distances, axis=1)
# 如果聚类簇的中心位置基本不变了,那么迭代终止。
if (last_clusters == nearest_clusters).all():
break
# 重新计算每个聚类簇的平均中心位置,并它作为聚类中心点
for cluster in range(k):
clusters[cluster] = dist(boxes[nearest_clusters == cluster], axis=0)
last_clusters = nearest_clusters
return clusters,nearest_clusters,distances在自己的数据集上对先验框进行聚类,这个作用会有多大?我个人觉得作用不大,直接默认使用COCO 数据集上得到的先验框即可。因为 YOLO 算法是去学习真实框与先验框之间的尺寸偏移量,即使你选的先验框再准确,也只能是网络更容易去学习而已。事实上,这对预测的精度没有什么影响,所以这个过程意义不大。我觉得作者在论文里这样写的原因在于你总得告诉别人你的先验框是怎么来的,并且让论文更具有学术性。
讲了这么多,来看看v3的9个anchor框是长什么样子的。

4.3 定义preprocess_true_boxes函数
preprocess_true_boxes,顾名思义对真实框进行相关预处理。为了更好地理解这个函数,有必要先说明bboxes和label分别表示什么,具体怎么操作。bboxes是用来存放真实框的中心坐标以及宽高(x,y,w,h),其shape为(3,150,4)。3表示3种网格尺寸,150表示每种网格尺寸允许存放的最大真实框数量,4就是(x,y,w,h)。label是用来存放3种网格尺寸下每一个网格的中心坐标、宽高、置信度以及所属类别(x, y, w, h, conf, classid),其中class_id用one-hot编码表示,并对其进行平滑处理。label的shape为(3,train_output_sizes,train_output_sizes,anchor_per_scale,5 + num_classes)。3表示3种网格尺寸,train_output_sizes表示每种网格尺寸的大小,anchor_per_scale表示每个网格预测多少个anchor框,5 + numclasses就不再多说了。label的初始化为0矩阵,即每个网格的信息(x, y, w, h, conf, classid)都设置为0。计算3个先验框和真实框的iou值,筛选iou值>0.3的先验框并标记索引, 然后将真实框的(x,y,w,h,class_id)填充到真实框所属的网格中(对应标记索引),网格的置信度设为1。
由于preprocess_true_boxes函数的篇幅较长,下面将分段讲解。
def preprocess_true_boxes(self, bboxes):
# 设定变量,用于存储label
label = [np.zeros((self.train_output_sizes[i], self.train_output_sizes[i], self.anchor_per_scale,
5 + self.num_classes)) for i in range(3)]
# [(150,4),(150,4),(150,4)],每张图片的每种网格尺寸最多允许存在150个真实框
bboxes_xywh = [np.zeros((self.max_bbox_per_scale, 4)) for _ in range(3)]
# 对应3种网格尺寸的bounding box数量
bbox_count = np.zeros((3,))
# 对图片中的每个真实框处理
for bbox in bboxes:
# 获取x_min, y_min, x_max, y_max坐标
bbox_coor = bbox[:4]
# 获取class_id
bbox_class_ind = bbox[4]
# 转化为one_hot编码,将物体的类别设置为1,其他为0
onehot = np.zeros(self.num_classes, dtype=np.float)
onehot[bbox_class_ind] = 1.0
# 对one_hot编码做平滑处理
uniform_distribution = np.full(self.num_classes, 1.0 / self.num_classes)
deta = 0.01
smooth_onehot = onehot * (1 - deta) + deta * uniform_distribution
# 计算中心点坐标(x,y) = ((x_max, y_max) + (x_min, y_min)) * 0.5
# 计算宽高(w,h) = (x_max, y_max) - (x_min, y_min)
# 拼接成一个数组(x, y, w, h)
bbox_xywh = np.concatenate([(bbox_coor[2:] + bbox_coor[:2]) * 0.5, bbox_coor[2:] - bbox_coor[:2]], axis=-1)
# 按8,16,32下采样比例对中心点以及宽高进行缩放,shape = (3, 4)
bbox_xywh_scaled = 1.0 * bbox_xywh[np.newaxis, :] / self.strides[:, np.newaxis]
# 新建一个空列表,用来保存3个anchor框(先验框)和真实框(缩小后)的IOU值
iou = []
# 先设置为False
exist_positive = False
# 针对 3 种网格尺寸
for i in range(3):
# 设定变量,用于存储每种网格尺寸下 3 个 anchor 框的中心位置和宽高
anchors_xywh = np.zeros((self.anchor_per_scale, 4))
# 将这 3 个 anchor 框的中心坐标移动到网格中心
anchors_xywh[:, 0:2] = np.floor(bbox_xywh_scaled[i, 0:2]).astype(np.int32) + 0.5
# 填充这 3 个 anchor 框的宽和高
anchors_xywh[:, 2:4] = self.anchors[i]
# 计算真实框与 3 个 anchor 框之间的 iou 值
iou_scale = self.bbox_iou(bbox_xywh_scaled[i][np.newaxis, :], anchors_xywh)
# 将iou值添加到iou列表中
iou.append(iou_scale)
# 找出 iou 值大于 0.3 的 anchor 框
iou_mask = iou_scale > 0.3 以下分为2种预处理方式。在该网格尺寸下,如果存在iou > 0.3 的 anchor 框,进行第1种预处理方式:
# 对于那些 iou > 0.3 的 anchor 框,做以下处理
if np.any(iou_mask):
# 根据真实框的坐标信息来计算所属网格左上角的位置. xind, yind其实就是网格的坐标
xind, yind = np.floor(bbox_xywh_scaled[i, 0:2]).astype(np.int32)
label[i][yind, xind, iou_mask, :] = 0
# 填充真实框的中心位置和宽高
label[i][yind, xind, iou_mask, 0:4] = bbox_xywh
# 设定置信度为 1.0,表明该网格包含物体
label[i][yind, xind, iou_mask, 4:5] = 1.0
# 设置网格内 anchor 框的类别概率,做平滑处理
label[i][yind, xind, iou_mask, 5:] = smooth_onehot
# 获取真实框的索引
bbox_ind = int(bbox_count[i] % self.max_bbox_per_scale)
# 填充真实框的中心位置和宽高
bboxes_xywh[i][bbox_ind, :4] = bbox_xywh
# 记录该网格尺寸下的真实框数量
bbox_count[i] += 1
# exist_positive标记为True,不进入第2种预处理方式
exist_positive = True在该真实框中,3种网格尺寸都不存在iou > 0.3 的 anchor 框,则进行第2种预处理方式:
if not exist_positive:
# reshape(-1)将矩阵排成1行,axis=-1,argmax最后返回一个最大值索引
best_anchor_ind = np.argmax(np.array(iou).reshape(-1), axis=-1)
# 获取best_anchor_ind所在的网格尺寸索引
best_detect = int(best_anchor_ind / self.anchor_per_scale)
# 获取best_anchor_ind在该网格尺寸下的索引
best_anchor = int(best_anchor_ind % self.anchor_per_scale)举个简单的例子:
0.2 0.22 0.18 i=0 8倍下采样
0.19 0.15 0.08 i=1 16倍下采样
0.25 0.28 0.23 i=2 32倍下采样将上面的iou矩阵排成一行。0.2 0.22 0.18 0.19 0.15 0.08 0.25 0.28 0.23
最大值索引best_anchor_ind = 7 (0.28最大)
best_detect = int( 7 / 3 ) = 2 对应网格尺寸 i=2 32倍下采样
best_anchor = int( 7 % 3 ) = 1 对应32倍下采样的第2个anchor
iou矩阵中第3行第2列就是0.28,这就对了。
# 根据真实框的坐标信息来计算所属网格左上角的位置
xind, yind = np.floor(bbox_xywh_scaled[best_detect, 0:2]).astype(np.int32)
label[best_detect][yind, xind, best_anchor, :] = 0
# 填充最佳网格尺寸下的真实框中心位置和宽高
label[best_detect][yind, xind, best_anchor, 0:4] = bbox_xywh
# 设定置信度为 1.0,表明该网格包含物体
label[best_detect][yind, xind, best_anchor, 4:5] = 1.0
# 设置网格内 best_anchor 框的类别概率,做平滑处理
label[best_detect][yind, xind, best_anchor, 5:] = smooth_onehot
# 获取真实框的索引
bbox_ind = int(bbox_count[best_detect] % self.max_bbox_per_scale)
# 填充真实框的中心位置和宽高
bboxes_xywh[best_detect][bbox_ind, :4] = bbox_xywh
# 记录该网格尺寸下的真实框数量
bbox_count[best_detect] += 1最后得到3种网格尺寸的label和真实框
# 获取label
label_sbbox, label_mbbox, label_lbbox = label
# 获取真实框
sbboxes, mbboxes, lbboxes = bboxes_xywh
return label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes5. 将像素矩阵、label和真实框打包成mini_batch
def __next__(self):
#切换成CPU运算,可以减少显存的负担
with tf.device('/cpu:0'):
# 从给定的[320, 352, 384, 416, 448, 480, 512, 544, 576, 608]中随机选择大小
self.train_input_size = random.choice(self.train_input_sizes)
self.train_output_sizes = self.train_input_size // self.strides
# 图像打包
batch_image = np.zeros((self.batch_size, self.train_input_size, self.train_input_size, 3))
# label框打包
batch_label_sbbox = np.zeros((self.batch_size, self.train_output_sizes[0], self.train_output_sizes[0],
self.anchor_per_scale, 5 + self.num_classes))
batch_label_mbbox = np.zeros((self.batch_size, self.train_output_sizes[1], self.train_output_sizes[1],
self.anchor_per_scale, 5 + self.num_classes))
batch_label_lbbox = np.zeros((self.batch_size, self.train_output_sizes[2], self.train_output_sizes[2],
self.anchor_per_scale, 5 + self.num_classes))
# 真实框打包
batch_sbboxes = np.zeros((self.batch_size, self.max_bbox_per_scale, 4))
batch_mbboxes = np.zeros((self.batch_size, self.max_bbox_per_scale, 4))
batch_lbboxes = np.zeros((self.batch_size, self.max_bbox_per_scale, 4))
# num_batchs(批处理个数) = num_samples(样本总数N) / batch_size(批尺寸,介于1-N之间)
# batch_count记录当前的批处理个数,num记录当前的图片处理个数(介于0 - batch_size-1之间)
# 每完成1个minbatch(批训练)输出1次
# 从第1张图片开始打包
num = 0
if self.batch_count < self.num_batchs:
while num < self.batch_size:
# 获取图片的索引
index = self.batch_count * self.batch_size + num
# 当训练完1个epoch后,进入下一个epoch,索引超出样本总数,所以减去样本总数
if index >= self.num_samples: index -= self.num_samples
# 读取对应索引的图片
annotation = self.annotations[index]
# 解析得到图片像素矩阵和boxs以及类别,当data_aug为True,随机对数据进行一些旋转,翻转等,增加数据的多样性
image, bboxes = self.parse_annotation(annotation)
# 获取每张图片的label框和真实框
label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes = self.preprocess_true_boxes(bboxes)
# 将每张图片的label和真实框存储在mini_batch中
batch_image[num, :, :, :] = image
batch_label_sbbox[num, :, :, :, :] = label_sbbox
batch_label_mbbox[num, :, :, :, :] = label_mbbox
batch_label_lbbox[num, :, :, :, :] = label_lbbox
batch_sbboxes[num, :, :] = sbboxes
batch_mbboxes[num, :, :] = mbboxes
batch_lbboxes[num, :, :] = lbboxes
# 处理完一张图片之后,num的值+1
num += 1
# 处理完一个mini_batch之后,batch_count的值+1
self.batch_count += 1
return batch_image, batch_label_sbbox, batch_label_mbbox, batch_label_lbbox, \
batch_sbboxes, batch_mbboxes, batch_lbboxes数据预处理全部完成!
补充
split()函数的使用方法:
Python3 split()方法www.w3cschool.cn
numpy.full()函数的使用方法:
numpy.full - NumPy v1.13 Manualdocs.scipy.org