基于ZYNQ-7000的AI加速器设计之整体架构阐述
本次AI加速器的设计,主要利用Xilinx公司的ZYNQ-7000全可编程器件,主要目的是应对人工智能时代算力不足的问题,由于人工智能时代的到来,各种神经网络的训练,数据挖掘,机器视觉和图像处理等算法计算复杂度较高,传统计算机出现计算时间较长或无法计算的问题,工作效率较低,而FPGA作为一种并行处理器件,相比传统CPU而言,计算速度较快,因此,我们可以尝试将一些原来由CPU处理的相关计算交给FPGA来完成,从而提升计算速度和工作效率,出于以上考虑,我们开展了基于ZYNQ-7000的AI加速器的相关设计。
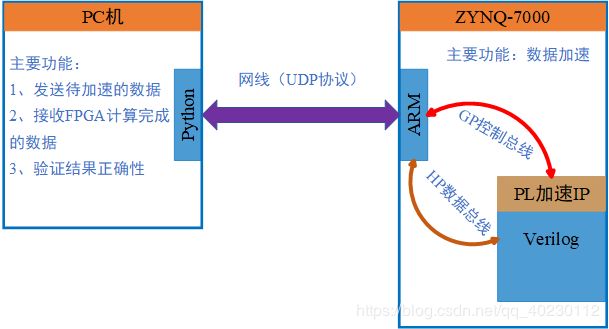
下图是整个AI加速器的整体框图,在PC端Python将需要加速计算的数据利用UDP协议通过网线发送到ZYNQ-7000的ARM端,ARM端调用PL端的加速IP,IP核采用Verilog语言编写,ARM和PL间的控制信息通过GP控制总线传递,数据信息通过HP数据总线传递。