视频分类论文阅读笔记——Learning Spatiotemporal Features With 3D Convolutional Networks
论文:Learning Spatiotemporal Features With 3D Convolutional Networks
作者:FaceBook AI研究院
来源:ICCV2015
代码:官方Caffe Code
文章目录
- 0. 摘要
- 1. 介绍
- 2. 方法
- 2.1 3D卷积和池化
- 2.2 探索卷积核时间深度
- 2.3 时空特征学习
- 2.3.5 C3D 视频描述子提取
- 2.3.6 C3D 学到了什么?
- 3. 动作识别
- 4. 动作相似度标定
- 5. 场景或者物体识别
- 6. 运行时分析
- 7. 总结分析
0. 摘要
本文主要有以下三个贡献:
- 实验表明 3D卷积神经网络(3-dimensional CNN)更适合于时空特征 的学习(同时建模外观特征和运动特征);
- 所有层的卷积核都是 3 × 3 × 3 3\times3\times3 3×3×3 同质化CNN在实验的3DCNN结构中性能最好;
- 本文提出的学习的时空特征(简称 C3D,Convolutional 3D),接上一个线性分类器后在多个基准数据集上都获得了 SOTA 性能。

1. 介绍
计算机视觉领域已经在 视频分析 领域深耕十几年了,一直在研究处理不同的问题,包括 动作识别[26],异常事件检测[2],以及活动理解[23]。
[26] Laptev and T. Lindeberg. Space-time interest points. In ICCV, 2003. 1, 2
[2] O. Boiman and M. Irani. Detecting irregularities in images and in video. IJCV, 2007. 1, 2
[3] T. Brox and J. Malik. Large displacement optical flow: Descriptor matching in variational motion estimation. IEEE TPAMI, 33(3):500– 513, 2011. 8
但是,用于解决关于大型视频数据库任务的一个通用的视频描述子仍是迫切需要的。
一个有效的视频描述符应该包含以下四个属性:
- 通用的(generic)。这样既能表示不同类型的视频,同时还有一定的区分能力;
- 紧凑的(compact)。因为视频的数据量很庞大,所以一个紧凑的描述符对处理、存储以及检索任务来说是相当灵活的;
- 高效的(efficient)。在现实系统中,每分钟都有大量的视频需要处理,所以必须是高效计算的。
- 简单的(simple)。必须是易于实现的。
虽然 3DCNN 之前已经被提出了[15,18],但是据我们所知,我们的工作在大规模监督训练数据集和现代化深度架构下使用 3DCNN, 在不同的视频分析任务中都取得了很好的性能。同时,我们也发现逐步地汇聚空间和时间信息,构建更深的网络能取得更好性能。
2. 方法
2.1 3D卷积和池化

如上图所示,2D卷积输入一张图片或者多通道图片都得到一张输出图。这样,在每一次卷积操作后都会损失输入信号的时间信息。而3D卷积则会保留输入信号的时间信息。
现在,我们经验地确定一个针对3D卷积的最优结构。因为在大型数据集上训练深度网络很耗时,所以我们在一个中型数据集 UCF101 上来搜索我们的结构。然后,我们用一个容量稍微少一点的网络在大型数据集上验证我们的结构。
根据在2D卷积神经网络上的研究[37], 3 × 3 3\times3 3×3 大小的卷积核伴着更深的网络层数能取得最好的结果。所以,我们的结构搜索会固定 空间感受野 为 3 × 3 3\times3 3×3,然后只改变时间维度上的深度。
记号:
- 记 视频片段 为 c × l × h × w c \times l \times h \times w c×l×h×w。(c 表示通道数目,l 表示帧的数目,h 和 w 表示帧的高度和宽度)
- 3D卷积核大小和卷积核大小记为 d × k × k d \times k \times k d×k×k。(d 是时间维度, k 是核的空间大小)
通用网络设置
- 我们所有设置的网络都是以 视频片段 为输入,然后预测 属于101类不同的动作的类别标签。
- 所有视频帧都拉伸为 128 × 171 128\times171 128×171(大概是 UCF101帧的一半帧率)。
- 视频被分成不重叠的 16帧剪辑,然后作为网络的输入。
- 输入尺寸为 3 × 16 × 128 × 171 3×16×128×171 3×16×128×171。
- 我们还使用了抖动,在训练的时候随机剪裁为大小为 3 × 16 × 112 × 112 3×16×112×112 3×16×112×112
- 该网络有5个卷积层和5个池化层(每个卷积层紧接着一个池化层),2个全连接层和一个用于预测动作标签的softmax损失层。
- 5层卷积层的数量分别是 64 , 128 , 256 , 256 , 256 64,128,256,256,256 64,128,256,256,256,且时间维度上的深度为 d d d;
- 所有卷积层都使用适当的填充(空间和时间),且步长设置为1,使得输入通过这些卷积层后 大小保持不变;
- 所有的池化层都是最大池化,内核大小为 2 × 2 × 2 2×2×2 2×2×2(第一层除外),最大池化步长为1;
- 第一池化层的核大小为 1 × 2 × 2 1×2×2 1×2×2,目的是不过早合并时间信号,同时满足16帧的剪辑长度(例如在完全折叠时间信号之前,我们可以使用缩放因子为2的最多进行4次池化操作);
- 两个全连接层有 2048 个输出;
- 我们使用30个clips的小批量训练网络,初始学习率为0.003,每4个epochs学习率减少10倍,训练16个epochs停止。
网络结构中的变量
为了寻找一个好的3D ConvNet架构,我们只改变卷积层的内核时间深度 d i d_i di,而保持所有其他常见设置如上文所述。
我们实验两种类型的网络结构:
- 均匀时间深度 : 所有卷积层具有相同的核时间深度;
- 变化的时间深度:内核的时间深度是跨层变化的。
- 对于齐次设置,我们用4个网络进行实验,它们的核时间深度d分别为1、3、5和7。将其命名为 depth-d,其中 d 代表时间深度。
- 对于变化的网络设置,我们实验两个网络,时间深度上升:3-3-5-5-7,时间深度下降:7-5-5-3-3。
- 我们注意到,所有这些网络在最后的池化层具有相同大小的输出(进行了适当的填充),因此它们对于完全连接层具有相同数量的参数
2.2 探索卷积核时间深度
在 UCF101的 train split 1 上进行训练,在 test split 1 上进行测试,精度如下:
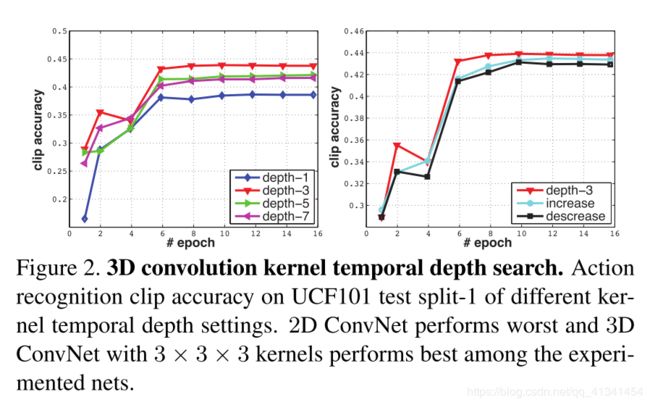
- depth-3 在同质网络中表现较好,depth-1因为没有建模运动信息,所以效果较差。
- 在变化网络结构中,depth-3表现的也很好,但是差距较小。
- 同时,我们也重新在更大的空间感受野(例如 5 × 5 5\times5 5×5)和全输入分辨率上( 240 × 320 240\times320 240×320)进行了实验。
- 表明 3 × 3 × 3 3×3×3 3×3×3是3D ConvNets的最佳内核选择(根据我们的实验子集),3D ConvNets在视频分类方面始终优于2D ConvNets。
2.3 时空特征学习
2.3.1 网络结构
由之前的讨论得出, 3 × 3 × 3 3\times3\times3 3×3×3是 3D ConvNet 比较好的选择。鉴于我们的 GPU 显存,我们设计如下结构的网络(为了简单,我们称之为 C3D):

2.3.2 数据集
我们在 Sports-1M[18] 数据集上训练我们的C3D(其是目前最大的视频分类基准数据),其包括了:1.1 million 的运动类视频(UCF101的100倍),每个视频属于 487运动类别 中的一类(UCF101的5倍)。
A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014.
2.3.3 训练
- 因为 Sport - 1M 有很多长视频,所以我们从每个训练视频中随机抽取 5个2秒长 的视频片段。
- 尺寸像之前所述: 重设为 128 × 171 128\times171 128×171,在训练的时候随机剪裁到 16 × 112 × 112 16 \times 112 \times 112 16×112×112(时间和空间上均进行抖动)。同时以50%的概率进行 随机水平翻转。
- 使用 30 个 minibatch size 的 SGD 优化器,初始学习率为 0.003,然后每 150K个 iterations 除以2。 优化过程在 1.9M iterations(大概13个epochs)停止。
- 除了重头开始训练外,我们还与在 I380K数据集 上进行预训练并进行微调的进行对比。
2.3.4 Sports-1M 分类结果

如上表所示,将我们的 C3D 和 DeepVideo[18],Convolution pooling[29] 进行比较。
18 A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014.
29 J. Ng, M. Hausknecht, S. Vijayanarasimhan, O. Vinyals, R. Monga, and G. Toderici. Beyond short snippets: Deep networks for video classification. In CVPR, 2015.
- 实验时,每个 clip 只使用 center crop,然后输入到网络进行预测。
- 对于每个视频,我们对 10个 clips 的预测结果取平均(随机从视频剪辑出来的)。
其中,在不同方法中有些差别:
- DeepVideo 和 C3D 使用 short clips, Convolution pooling 使用 much longer clips。(这也是造成最后预测精度不一致的原因之一)
- 我们注意到 Convolution pooling 中使用 clip 和 videos 的 top1 精度差异很小,因为他使用了 120-frames 的 剪辑作为输入。
2.3.5 C3D 视频描述子提取
经过训练后,C3D可以作为特征提取器用于其他视频分析任务。
为了提取 C3D特征,我们进行以下操作:
- 一个视频被分为 16 frames 长的 long clips,两个相邻的 clips 包含 8-frame 的重复;
- 然后这些 clips 输入到 C3D 网络提取 fc6 层的激活;
- 最后这些 fc6 activations 取平均得到一个 4096 维度的 video descriptor,并进行 L2 归一化。
2.3.6 C3D 学到了什么?
我们使用 反卷积方法[46] 来理解 C3D 在内部学习到了什么。
M. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. In ECCV, 2014
我们观察到C3D一开始只关注前几帧的外观(apparence),然后在接下来的几帧中 跟踪突出的运动 。

图4显示了两个激活度最高的 C3D conv5b 特征图的反卷积,并被投影回图像空间。
在第一个例子中,该特征聚焦于整个人,然后在剩下的帧跟踪撑杆跳运动。类似地,在第二个例子中,它首先关注眼睛,然后在化妆时跟踪眼睛周围发生的动作。
因此,C3D不同于标准的2D ConvNets,它有选择地兼顾运动和外观。我们在补充材料中提供了更多的可视化,以便更好地了解所学习的特性。
3. 动作识别
- 数据集:在 UCF101数据集上进行实验,包含 101类的人类动作类别,共 13,320个视频。
- 分类模型:先提取 C3D特征,然后输入一个 多分类SVM进行分类。
- 本文实验几个不同的网络:
- I380K 数据集上训练的 C3D;
- Sports-1M 数据集上训练的 C3D;
- 先在 I380K 上进行预训练然后在 Sports-1M 上进行微调;
- 最后的多网络,我们连接上述网络的 L2-正则化 描述;
- 基准:1)当时最好的人工特征——改进的密集轨迹(improved dense trajectories ,iDT[44])。2)很受欢迎的深度图像特征—— Imagenet[16](在ImageNet上预训练的Caffe特征)
-
对于 iDT 特征,使用 bag-of-word 表达(每个特征通道 (HOG, HOF, MBHx, and MBHy) 都有5000个codebook;
然后每个通道分别使用 L1范数 进行标准化,最后进行联合形成 25K长的特征向量。 -
对于 ImageNet,和C3D类似,每帧都提取fc6层得到特征然后取平均值作为最后视频的特征。
-
最终都是用 多分类SVM分类器进行分类
-
- 结果:
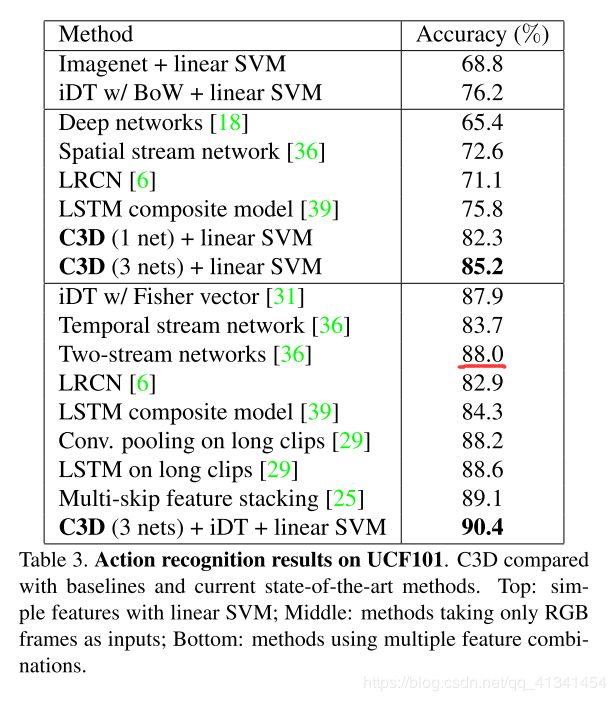
- 特别的,当 C3D(3 nets)和 iDT特征结合的时候,精度提升到 90.4%,但是当它和 ImageNet 特征结合的时候,仅仅只有 0.6% 精度的提升。 说明了 C3D 特征能够很好地捕捉到 外观信息 和 运动信息,因此结合 ImageNet 特征(深度外观特征)后提升较小。(是不是说明 C3D 特征还有一定的改进空间?)
- 事实上,iDT特征是基于 optical flow tracking and histograms of low-level gradients 的手动特征,C3D 是比较高级的 抽象/语义 特征,所以二者的结合能提高分类效果。
- 然而, C3D 需要和 iDT 特征结合才比 two-stream networks [36], the other iDT-based methods [31, 25], and the method that focuses on long-term modeling [29] 要优。
[36] K. Simonyan and A. Zisserman. Two-stream convolutional networks for action recognition in videos. In NIPS, 2014.
[25] Z. Lan, M. Lin, X. Li, A. G. Hauptmann, and B. Raj. Beyond gaussian pyramid: Multi-skip feature stacking for action recognition. CoRR, abs/1411.6660, 2014
[31] X. Peng, L.Wang, X.Wang, and Y. Qiao. Bag of visual words and fusion methods for action recognition: Comprehensive study and good practice. CoRR, abs/1405.4506, 2014.
[29] J. Ng, M. Hausknecht, S. Vijayanarasimhan, O. Vinyals, R. Monga, and G. Toderici. Beyond short snippets: Deep networks for video classification. In CVPR, 2015
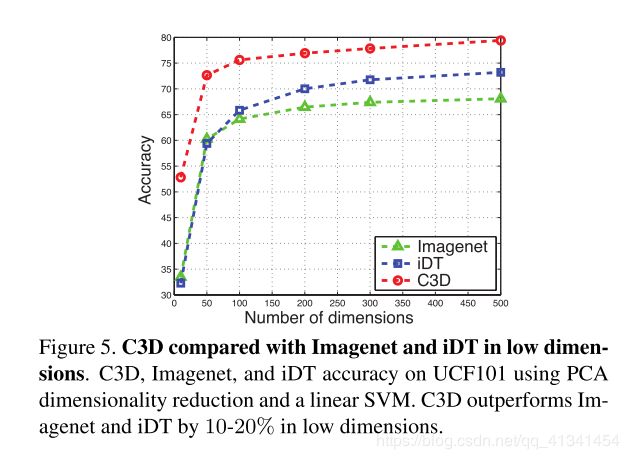
- C3D的紧凑性:我们使用 PCA 将原始特征投影到更低的维度,并比较投影后的特征在 UCF101上的分类精度(包括 C3D,iDT,和ImageNet特征),结果如下:
- Embedding可视化:
- 我们通过可视化我们的 C3D 特征在另一个数据集上的嵌入结果来定性地评估一下我们 C3D 特征是不是一个通用的特征。
我们先随机地从 UCF101数据集中 选择 100K 的 clips,再分别提取 C3D 特征和 ImageNet 特征,然后使用 t-SNE[43] 将其投影到一个二维空间,结果如下:(注意,我们没有在新的数据集上进行任何的微调,所以结果表明我们的 C3D 能有较好的跨数据集通用性)

[43] L. van der Maaten and G. Hinton. Visualizing data using t-sne. JMLR, 9(2579-2605):85, 2008.
4. 动作相似度标定
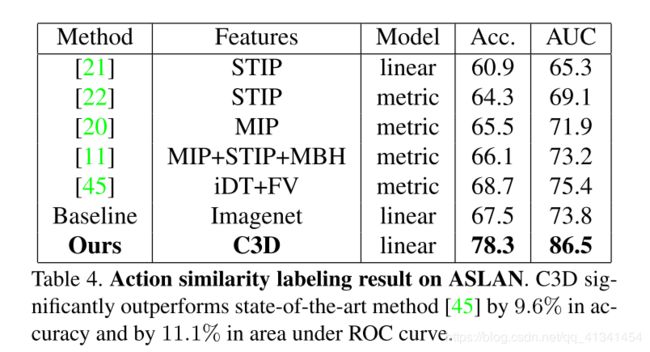
数据集: ASLAN 包含 3,631段数据,分为 432 个动作类别。
任务定义:预测给定的一对视频是否属于相同的类别。
特征:将视频划分为有 8 帧重叠的 16-frames clips,然后对每个clip提取 C3D 特征: prob, fc7,fc6, pool5。最后视频的特征通过对每种特征取平均得到。
分类模型:按照[21]中的设定,给定一队视频,我们计算12中不同的距离。对于4种特征,就有 12 × 4 = 48 12 \times 4 = 48 12×4=48 长度的特征向量,然后单独的进行归一化。 最后,再使用一个 SVM 进行分类是不是属于同一类别。
结果:
[21] O. Kliper-Gross, T. Hassner, and L. Wolf. The action similarity labeling challenge. TPAMI, 2012.
5. 场景或者物体识别
未翻。
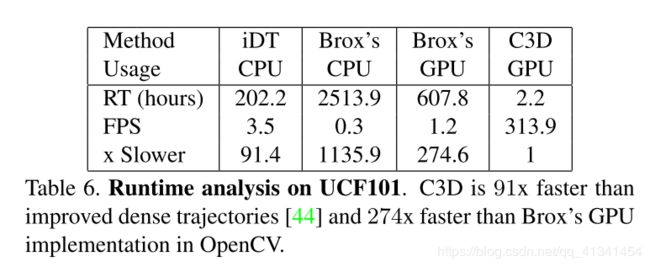
6. 运行时分析
测试了多种方法在整个 UCF101 数据集上提取特征的时间消耗(包括 IO),包括使用一个单 CPU 或者 一个单GPU K40 Tesla GPU,比较如下:
7. 总结分析
本文主要解决使用3D卷积来提取视频的时空特征,同时研究了 3D卷积核的最佳时间维度长度。 得出 C3D 能同时比较好地建模 外观和运动特征。