SparkStreaming应用解析(一)
文章目录
- 一、SparkStreaming是什么
- SparkStreaming的关键抽象
- SparkStreaming的整体架构
- SparkStreaming的背压机制
- SparkStreaming的入口
- StreamingContext
- 牛刀小试
- <1>首先要在linux上安装netcat
- <2>书写wordcount
- 二、入门
- 1.DStream的输入
- <1>基本数据源
- <2>高级数据源
一、SparkStreaming是什么
实时流计算,流,可以理解为像水流那样,源源不断的流动,而计算,也都是不停歇的一直在伴随着计算,所以SparkStreaming不是一种全量计算,是相当于水的过滤器一样,过滤掉水中的杂质。而流式计算,目前流行的就是storm,spark,flink,处理日志数据,经常会采用流式计算,而水流的最小数据单位就是一条日志数据,我们就可以一条数据一条数据去计算,也可以分段计算,比如一个段落有100条日志数据,然后当做批处理来做,也是一种微批次处理,而SparkStreaming就是后者,准实时处理系统,微批次处理架构。
而SparkStreaming处理方式就是,先用接收器接收数据,然后以时间n秒分割接收到的数据,每n秒接收到的数据当做一个RDD,然后再交给spark-core去对rdd进行计算。
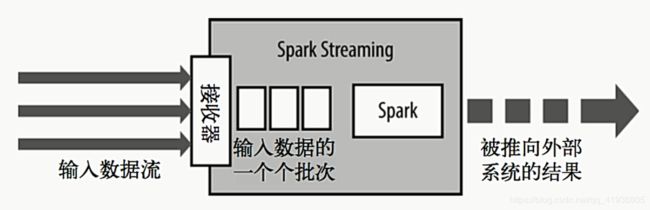
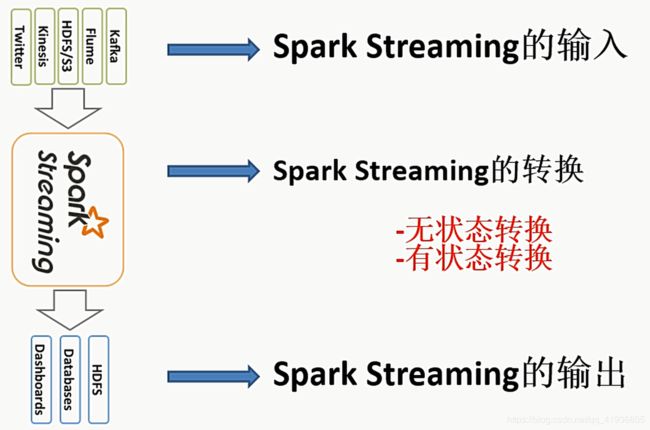
所以SparkStream主要涉及到的就是
- SparkStreaming的输入
主要涉及到Kafka,HDFS,Flume… - SparkStreaming的转换
有状态转换
无状态转换 - SparkStreaming的输出
HDFS,数据库,Dashboards(javaEE系统中)
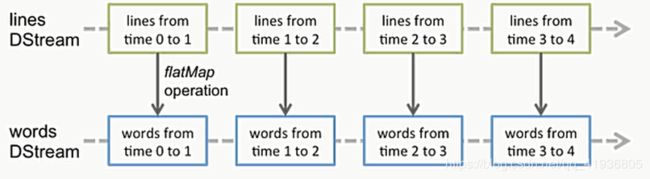
SparkStreaming的关键抽象
如上图所示,中间是有一个系统专门做转换操作的,而我们把它叫做DStream,我们一开始先会按照时间对进来的数据进行分段处理,也就是RDD@time1 RDD@time2 RDD@time3 …

但是必须要知道的就是,这几个东西,他是不共存的,因为每进来一个time分段好的rdd时,之前处理好的就已经把段落分好了,进入转换操作了。
然后接下来,就是所谓的流的转换操作了,针对wordcount去解释一下,之前分区好的数据变成一行一行的,然后按照时间分区好的行,去进行了flatMap操作,转换完成之后,形成words DStream,但是实质上还是对rdd进行操作,和我们之前的wordcount相比,这就是一个多次转换的行为
SparkStreaming的整体架构
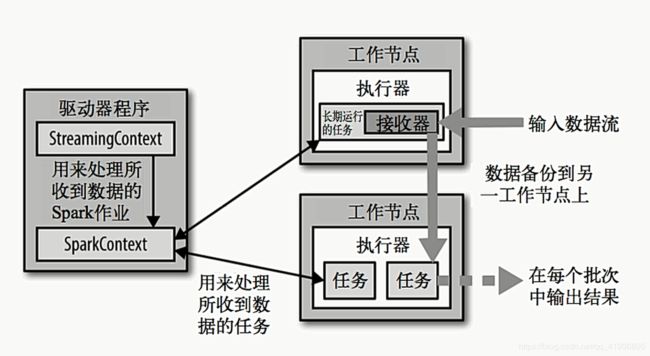
从接收数据开始,只要不手动停止程序,就会一直进行流计算操作
SparkStreaming的背压机制
当接收到的数据速度大于数据处理的速度时,形成rdd的积压就会触发这个机制
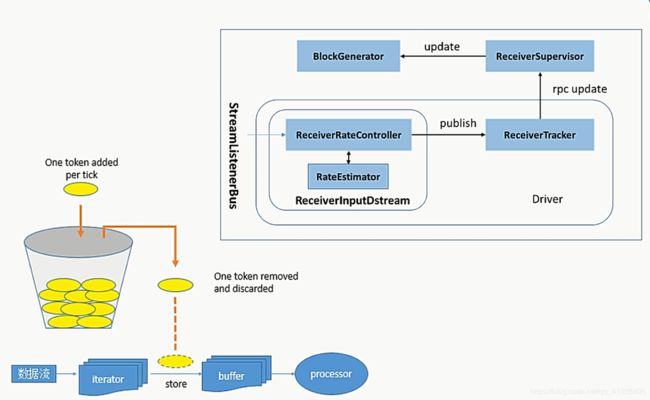
如果前面的数据产生的过快了,就会有一个桶,桶里面会产生令牌,只有拥有令牌的数据源才可以被封装成为rdd,只要我们控制了令牌的生成速度,就能缓解掉这个问题,因为他做到了控制rdd@time的产生速度,当获取不到令牌的时候就会形成阻塞状态,等待令牌的生成。
SparkStreaming的入口
StreamingContext
val conf = new SparkConf().setMaster(master).setAppName(appName);
val ssc = new StreamingContext(conf,Second(1));
//可以通过ssc.sparkContext来访问SparkContext
//或者直接通过sparkContext来创建StreamingContext
var ssc = new StreamingContext(new SparkContext(),Second(1));
初始化Context之后 :
1.定义消息输入源来创建DStreams.
2.定义DStreams的转化操作和输出操作.
3.通过streamingContext.start()来启动消息采集和处理
4.等待程序终止,可以通过streamingContext.awaitTermination()来设置
5.通过StreamingContext.stop()来手动停止程序
牛刀小试
写一个sparkstreaming的workcount,然后运行之后持续向监听端口进行数据的注入,
<1>首先要在linux上安装netcat
切换到root用户然后
yum install -y nc
等待安装即可,netcat可以对指定端口进行字面量的注入,方法是nc -lk port
运行,即可开始输入数据
<2>书写wordcount
package sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object streamingWordCount extends App {
//创建配置
val sc = new SparkConf().setAppName("sparkStreaming").setMaster("local[*]")
//创建streamingContext
val ssc = new StreamingContext(sc,Seconds(5))
//从socket接收数据
val lineDStream = ssc.socketTextStream("linux01",5456)
val wordDStream = lineDStream.flatMap(_.split(" "))
val word2CountDStream = wordDStream.map((_,1))
val resultDStream = word2CountDStream.reduceByKey(_ + _)
resultDStream.print()
//启动ssc
ssc.start()
ssc.awaitTermination()
}
运行,查看输出结果,并且在端口进行数据注入

-------------------------------------------
Time: 1549451450000 ms
-------------------------------------------
(woshi,1)
-----------------------------------------
Time: 1549451465000 ms
-------------------------------------------
(shi,1)
(zhang,2)
(la,3)
(zhnag,1)
(sb,1)
-------------------------------------------
Time: 1549451475000 ms
-------------------------------------------
(shi,1)
(zhang,2)
(sb,1)
-------------------------------------------
Time: 1549451495000 ms
-------------------------------------------
(hel,1)
-------------------------------------------
Time: 1549451500000 ms
-------------------------------------------
(hello,1)
-------------------------------------------
Time: 1549451505000 ms
-------------------------------------------
(father,1)
(my,1)
(is,1)
(hello,1)
(name,1)
(your,1)
-------------------------------------------
Time: 1549451520000 ms
-------------------------------------------
(zhang,2)
(is,1)
(sb,1)
-------------------------------------------
Time: 1549451525000 ms
-------------------------------------------
最后成功实现实时对数据进行处理,至于netcat,采用的还是tcp协议。
二、入门
1.DStream的输入
<1>基本数据源
- 文件
监控一个文件目录,如果监控的文件目录,把数据放入了目录中,他就会把文件当成一个rdd,针对文件进行转换
下面就用sparkShell来做一个基于hdfs的基本数据源输入的实时计算
scala> import org.apache.spark.streaming._
import org.apache.spark.streaming._
scala> val ssc = new StreamingContext(sc,Seconds(5))
ssc: org.apache.spark.streaming.StreamingContext = org.apache.spark.streaming.StreamingContext@703947bd
scala> val lineDStream = ssc.textFileStream("hdfs://linux01:8020/data")
lineDStream: org.apache.spark.streaming.dstream.DStream[String] = org.apache.spark.streaming.dstream.MappedDStream@3749c6ac
^
scala> var words = lineDStream.flatMap(_.split(" "))
words: org.apache.spark.streaming.dstream.DStream[String] = org.apache.spark.streaming.dstream.FlatMappedDStream@75381b61
scala> val word2count = words.map((_,1))
word2count: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.MappedDStream@27a57c66
scala> val result = word2count.reduceByKey(_+_)
result: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.ShuffledDStream@4f6938cb
scala> result.print
scala> ssc.start
-------------------------------------------
Time: 1549455365000 ms
-------------------------------------------
(Unless,3)
(Massachusetts,1)
(Contributions),1)
(NON-INFRINGEMENT,,1)
(BUSINESS,2)
(agree,1)
(offer,1)
(its,4)
(event,1)
(under,10)
...
-------------------------------------------
Time: 1549455370000 ms
-------------------------------------------
并且附上输入的操作
[centos01@linux01 hadoop-2.7.2]$ bin/hdfs dfs -put ./LICENSE.txt /data
- RDD队列
package sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object streamingRDDWordCount extends App {
val conf = new SparkConf().setMaster("local[*]").setAppName("App")
val ssc = new StreamingContext(conf,Seconds(1))
//创建一个RDD队列
val rddQueue = new mutable.SynchronizedQueue[RDD[Int]]
//创建QueueInputDStream
val inputStream = ssc.queueStream(rddQueue)
//处理队列中的RDD数据
val mappedStream = inputStream.map(x => (x%10,1))
val reducedStream = mappedStream.reduceByKey(_ + _)
//打印结果
reducedStream.print()
ssc.start()
for(i <- 1 to 300) {
rddQueue+=ssc.sparkContext.makeRDD(1 to 300,20)
Thread.sleep(1000)
}
ssc.awaitTermination()
}
<2>高级数据源
- 自定义一个Receiver采集器,测试方法同理
package sparkstreaming
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import java.nio.charset.StandardCharsets
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.receiver.Receiver
import scala.collection.mutable
class customReceiver(host:String,port:Int) extends Receiver[String](StorageLevel.MEMORY_ONLY){
//程序启动的时候调用
override def onStart(): Unit = {
val socket = new Socket(host,port)
var inputText= ""
var reader = new BufferedReader(new InputStreamReader(socket.getInputStream(),StandardCharsets.UTF_8))
inputText = reader.readLine()
while(!isStopped() && inputText!=null) {
//如果接受到了数据,就保存
store(inputText)
inputText = reader.readLine()
}
restart("")
}
//程序停止的时候调用
override def onStop(): Unit = {
}
}
object customReceiver{
def main(args: Array[String]): Unit = {
//创建配置
val sc = new SparkConf().setAppName("sparkStreaming").setMaster("local[*]")
//创建streamingContext
val ssc = new StreamingContext(sc,Seconds(5))
//从socket接收数据
val lineDStream = ssc.receiverStream(new customReceiver("linux01",5456))
val wordDStream = lineDStream.flatMap(_.split(" "))
val word2CountDStream = wordDStream.map((_,1))
val resultDStream = word2CountDStream.reduceByKey(_ + _)
resultDStream.print()
//启动ssc
ssc.start()
ssc.awaitTermination()
}
}
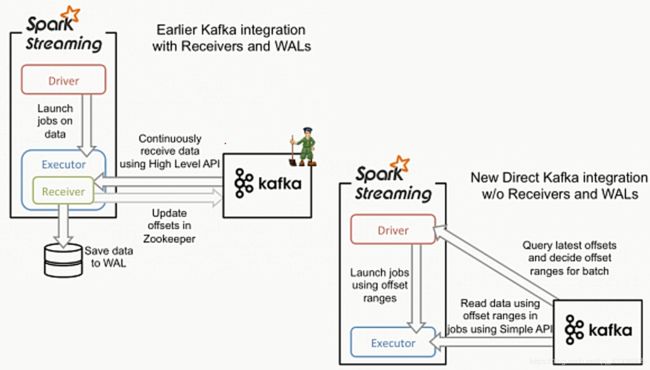
- ※KafKa
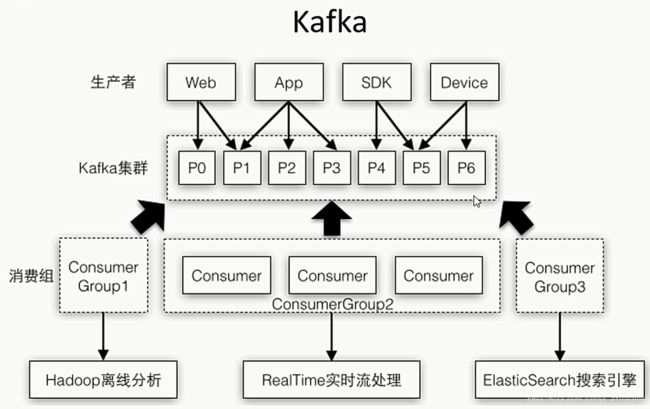
意思就是,从Web、App,或者某些设备上通过一种日志框架,像SLF4j那种的将日志实时注入到KafKa中,然后根据业务的不同会产生很多的主题,每个主题有不同的Partition,而它的作用就是提升存储量,但是KafKa缺点在于无法保证全体的日志采集顺序,只能保证分区内的存储顺序,而每天所采集到的日志是大量的,我们本地到一定情况下是打不开的,而在消息队列中又存在发布订阅模式(将信息发送到主题所有订阅它的都可以收到,所以我们就需要多个ConsumerGroupe来监听实现发布功能)和消息队列模式(在ConsumerGroup里面的所有的Consumer拿到的信息都是不同的,而最好情况下就是每一个Consumer监听多余一个Partition最节省资源,但要是少于一个就代表会有Consumer停止工作)
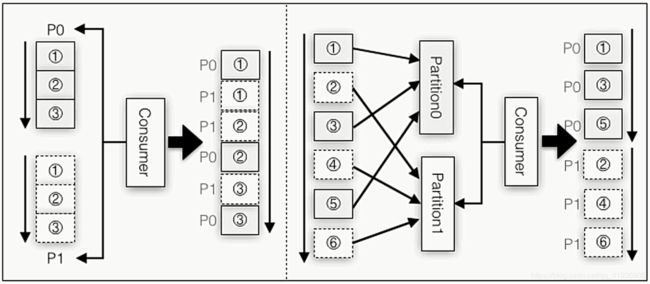
当SparkStreaming和KafKa连接是会有数据丢失的风险的,如果SparkStreaming用了高级API去连接KafKa,等于是自动维护了OffSet,如果此时SparkStreaming挂了,数据本身没有任何处理,重启之后因为经过了Offset的维护,所以就不会消费上次没处理的数据了,在这种情况下有两种解决方法:
(左图)1.使用High Level API,拿到数据之后就写去WAL预写日志中,相当于数据保存,如果SparkStreaming挂了,就可以从预写日志中拿过来,其实这个WAL在关系型数据库很常见,比如oracle崩了,但是数据还是在,因为日志在进行之前就进行预写保存了,但是这种方式是老方式了,现在用第二种方式比较多
(右图)2.新的方式就是SparkStreaming直接使用KafKa的低级API所有OffSet由Spark自动进行维护,所以这时,比如说我通过api获取到了某些数据,在这之后因为我使用了低级api所以不会更新zookeeper里面的数据,把业务处理完在后台更新OffSet,比如在中间宕机了,重新启动的时候会从上次的程序继续读,不过这个情况的业务代码要单独写,