LeetCode: Two Sum 求解两数之和及哈希算法
=======题目描述=======
题目链接:https://leetcode.com/problems/two-sum/
题目内容:
Two Sum
Given an array of integers, return indices of the two numbers such that they add up to a specific target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1].=======算法实现=======
哈希法
C++实现
class Solution {
public:
vector twoSum(vector& nums, int target) {
unordered_map umapping;
vector result;
//将数组转换为哈希表
for(int i=0; ii代表非同一个数组元素
if(umapping.find(gap) !=umapping.end() &&umapping[gap]>i)
{
result.push_back(i);
result.push_back(umapping[gap]);
break;
}
}
return result;
}
}; c++ unordered_map 判断某个键是否存在:
unordered_map c++ reference 是c++ 哈希表的实现模板,在头文件
若有unordered_map
方法1: 若存在 mp.find(x)!=mp.end()
方法2: 若存在 mp.count(x)!=0
python实现
class Solution:
def twoSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
num_dict = dict()
# 创建字典.
for num_ndx in range(len(nums)):
num_dict[nums[num_ndx]] = num_ndx
for i in range(len(nums)):
diff = target - nums[i]
if (diff in num_dict and num_dict[diff] != i):
return [i, num_dict[diff]]
=======算法笔记->哈希算法=======
什么是哈希表和哈希算法

图片来自:https://github.com/Burgessz/leetcode_solution
什么是哈希表和哈希算法?中讲解的很生动:
①
哈希算法并不是一个特定的算法而是一类算法的统称。哈希算法也叫散列算法,一般来说满足这样的关系:f(data)=key,输入任意长度的data数据,经过哈希算法处理后输出一个定长的数据key。同时这个过程是不可逆的,无法由key逆推出data。
如果是一个data数据集,经过哈希算法处理后得到key的数据集,然后将keys与原始数据进行一一映射就得到了一个哈希表。一般来说哈希表M符合M[key]=data这种形式。
哈希表的优点:当原始数据较大时,可以用哈希算法处理得到定长的哈希值key,那么这个key相对原始数据要小得多。就可以用这个较小的数据集来做索引,达到快速查找的目的。
②
哈希(Hash)是一种数据编码方式,将大尺寸的数据(如一句话,一张图片,一段音乐、一个视频等)浓缩到一个数字中,从而方便地实现数据匹配·查找的功能。
比如有一万首歌,要求按照某种方式保存好。到时给你一首新歌(命名为X),要求你确认新的这首歌是否在那一万首歌之内。
无疑将一万首歌一个个比对非常慢。但如果存在一种方式能将一万首歌的每一首数据浓缩到一个数字(称为哈希码)中,于是得到一万个数字,那么用同样的算法计算新歌X的编码,看歌X的编码是否在之前一万个数字中,就能知道歌X是否在一万首歌中。
将一首歌的5M字节数据浓缩到一个数字中的算法就是哈希算法。
那一万首歌按照各自的编码数字从小到大排序后得到的一个表就是哈希表。
显然,由于信息量的丢失,有可能多首歌的哈希码是同一个。好的哈希算法会尽量减少这种冲突,让不同的歌有不同的哈希码。最差的哈希算法自然就是所有的歌用那个算法算出来的都是同一个哈希码。
作为例子,如果要你组织那一万首歌,一个简单的哈希算法就是让歌曲所占硬盘的字节数作为哈希码。这样的话,你可以让一万首歌“按照大小排序”,然后遇到一首新的歌,只要看看新的歌的字节数是否和已有的一万首歌中的某一首的字节数相同,就知道新的歌是否在那一万首歌之内了。
对于一万首歌的规模而言,这个算法已经相当好,因为两首歌有完全相同的字节数是不大可能的。就算真有极小概率出现不同的歌有相同的哈希码,那也只有寥寥几首歌,此时再逐首比对即可。
哈希表优缺点
哈希表是一种与数组、链表等不同的数据结构,与他们需要不断的遍历比较来查找的办法,哈希表设计了一个映射关系f(key)= address,根据key来计算存储地址address,这样可以1次查找,f既是存储数据过程中用来指引数据存储到什么位置的函数,也是将来查找这个位置的算法,叫做哈希算法。
数组的特点是:寻址容易,插入和删除困难;
而链表的特点是:寻址困难,插入和删除容易。
优点:
哈希表是种数据结构,它可以提供快速的插入操作和查找操作。不论哈希表中有多少数据,插入和删除(有时包括侧除)只需要接近常量的时间即0(1)的时间级。
缺点:
哈希表也有一些缺点它是基于数组的,数组创建后难于扩展某些哈希表被基本填满时,性能下降得非常严重,所以程序虽必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)。
而且,也没有一种简便的方法可以以任何一种顺序〔例如从小到大〕遍历表中数据项。如果需要这种能力,就只能选择其他数据结构。
然而如果不需要有序遍历数据,井且可以提前预测数据量的大小。那么哈希表在速度和易用性方面是无与伦比的。
解决冲突的办法:
1、开放定址法
Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
其中m为表长,di为增量序列
如果di值可能为1,2,3,...m-1,称线性探测再散列。
如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,...k*k,-k*k(k<=m/2)
称二次探测再散列。
如果di取值可能为伪随机数列。称伪随机探测再散列。
例:在长度为11的哈希表中已填有关键字分别为17,60,29的记录,现有第四个记录,其关键字为38,由哈希函数得到地址为5,若用线性探测再散列,如下:
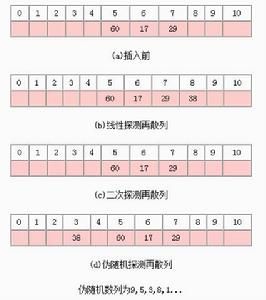
2、再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。
3、链地址法
将所有关键字为同义词的记录存储在同一线性链表中。
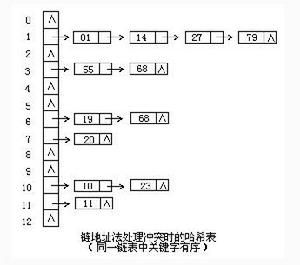 哈希表算法
哈希表算法
4、建立一个公共溢出区
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。
哈希表,首先是一种数据结构,是一种效率极高的查找方式,哈希表的核心在于哈希函数的设计,哈希冲突了不要紧,我们要增加随机性以及对冲突进行适当的有损化的处理。