AutoAugment: Learning Augmentation Strategies from Data
论文地址:https://arxiv.org/pdf/1805.09501v3.pdf
本文提出一种数据增强(data augument)策略。通过创建一个搜索空间(search space),利用搜索算法(search algorithm)来选择合适的数据增强方法。
该方法在不同的数据集上具有良好的可迁移性(transferable between datasets),在一种数据集上学习到的方法(policy)迁移到其他数据集上也有不错的表现。
【摘要】
数据增强是提高现代图像分类器准确性的有效技术。但是,当前的数据增强实现是手动设计的。在本文中,我们描述了一个名为AutoAugment的简单过程,以自动搜索改进的数据增强策略。
在我们的实现中,我们设计了一个搜索空间,其中的策略(policy)由许多子策略(sub-policies)组成,其中一个子策略是每个批次中的每个图像随机选择的。子策略由两个操作组成,每个操作是图像处理功能,例如平移,旋转或剪切,以及这些操作被采用的的概率和大小。我们使用搜索算法找到最佳策略,以便神经网络在目标数据集上产生最高的验证准确度。
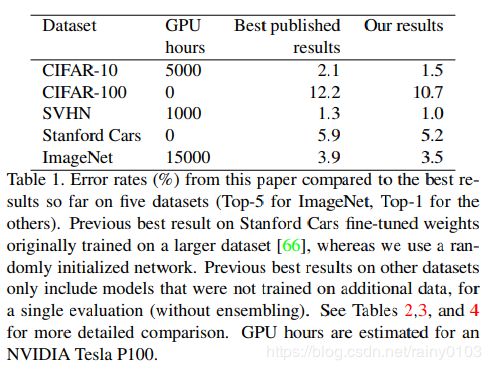
我们的方法在CIFAR-10,CIFAR-100,SVHN和ImageNet上实现了最先进的精确度(无需额外数据)。在ImageNet上,我们获得了83.5%的TOP-1准确度,比之前的83.1%的记录好0.4%。在CIFAR-10上,我们实现了1.5%的错误率,比之前的SOTA提高了0.6%。
我们发现的增强策略可以在不同的数据集之间转换。在ImageNet上学到的策略转移到其他数据集上实现了显著提高,例如Oxford Flowers,Caltech-101,Oxford-IIT Pets,FGVC Aircraft和Stanford Cars。
【介绍】
深度神经网络是强大的机器学习系统,在训练大量数据时往往运行良好。数据增加是一种有效的技术,通过随机“增加”来增加数据的数量和多样性;在图像域中,常见的增强包括将图像平移几个像素,或者水平地移动图像。
然而,机器学习和计算机视觉的一个重点是设计更好的网络架构,较少关注包含更多不变性的更好的数据增强方法。例如,在ImageNet上,2012年推出的数据增强方法仍然是标准,只有很小的变化。
即使已经为特定数据集找到了增强改进,它们通常也不会有效地转移到其他数据集。例如,由于这些数据集中存在不同的对称性,在训练期间水平移动图像是CIFAR-10上的有效数据增强方法,但不是MNIST上的有效数据增强方法。最近提出了对自动学习数据增加的需求,这是一个未解决的重要问题。
在本文中,我们的目标是自动化为目标数据集找到有效数据增强策略的过程。在我们的实现中,每个策略表达了可能的增强操作的若干选择和顺序,其中每个操作是图像处理功能(例如,平移,旋转或颜色标准化),应用该功能的概率,以及它们应用的大小。我们使用搜索算法来找到这些操作的最佳选择和顺序,以便训练神经网络产生最佳的验证准确性。
在我们的实验中,我们使用强化学习(Reinforcement Learning)作为搜索算法,但我们相信如果使用更好的算法,结果可以进一步改善。
我们的大量实验表明,AutoAugment在使用案例中实现了出色的改进:
- AutoAugment可以直接应用于感兴趣的数据集,以找到最佳的增强策略(AutoAugment-direct)
- 学习的策略可以转移到新的数据集(AutoAugment) -传递)。
【相关工作】
常见的用于图像识别的通用数据增强方法已经被设计好,并且最佳增强策略是数据集特定的。由于这些方法是手动设计的,因此需要专业知识和时间。我们从原则上学习数据增强策略的方法可以用于任何数据集,而不仅仅是一个。
生成对抗网络(GANs)也已用于生成附加数据。我们的方法和生成模型之间的关键区别在于我们的方法采用可见的数据转换操作,而生成模型(如GAN)直接生成扩充数据。
【AutoAugment:直接在感兴趣的数据集上搜索最佳扩充策略】
我们制定了将最佳扩充策略作为离散搜索问题的问题(见下图1)。
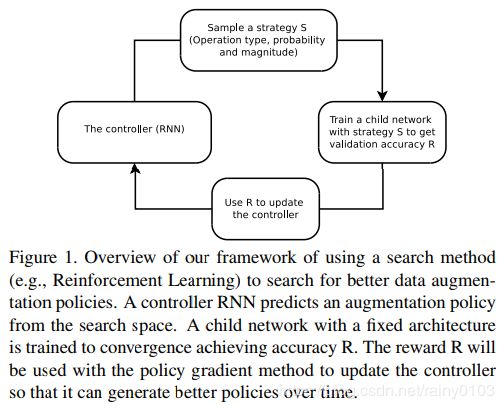
我们的方法包括如下两个部分:
- 搜索算法(search algorithm)
- 搜索空间(search space)
在高级别,搜索算法(实现为控制器RNN)对数据增强策略S进行采样,该数据增强策略S具有关于使用什么图像处理操作的信息,在每个批次中使用操作的概率以及操作的大小。我们的方法的关键是,策略S将用于训练具有固定架构的神经网络,其验证精度R将被发送回以更新控制器。由于R不可微分,控制器将通过策略梯度方法更新。
搜索空间详细信息:在我们的搜索空间中,策略由5个子策略组成,每个子策略由2个要按顺序应用的图像操作组成。另外,每个操作还与两个超参数相关联:1)应用操作的概率;2)操作的大小(magnitude)。
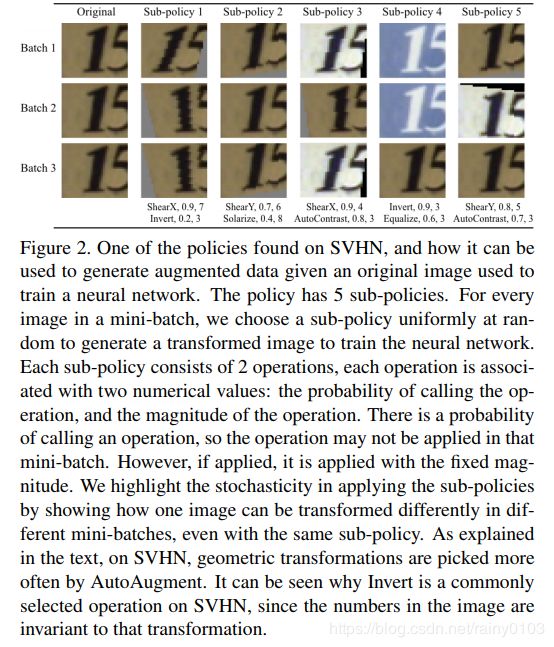
图2显示了我们的搜索空间中包含5个子策略的策略示例。第一个子策略指定了ShearX的顺序应用,然后是Invert。应用ShearX的概率为0.9,并且在应用时,其大小为7,然后应用Invert。概率为0.8。反转操作不使用幅度信息。我们强调这些操作是按照指定的顺序应用的。
我们在实验中使用的操作来自PIL,一种流行的Python图像库。为了一般性,我们考虑了PIL中接受图像作为输入并输出图像的所有函数。我们还使用了另外两种有前景的增强技术:Cutout(剪切)和SamplePairing(样本配对)。
我们搜索的操作是ShearX / Y,TranslateX / Y,旋转,AutoContrast,反转,均衡,曝光,色调分离,对比度,颜色,亮度,清晰度,剪切,样本配对。总的来说,我们在我们的搜索空间中有16个操作。每个操作还带有默认的幅度范围,我们将幅度范围离散化为10个值(均匀间距),以便我们可以使用离散搜索算法来找到它们。同样,我们也将将该操作应用的概率离散化为11个值(均匀间距)。查找每个子策略成为可能性空间中的搜索问题。
我们使用的16个操作及其默认值范围显示在附录的表1中。请注意,我们的搜索空间中没有明确的“身份”操作;此操作是隐式的,可以通过调用概率设置为0的操作来实现。
搜索策略的细节:我们在实验中使用的搜索算法使用了强化学习。搜索算法有两个组成部分:一个由递归神经网络构成的控制器,以及训练算法,采用了近端策略优化算法。在每一步,控制器预测由softmax产生的决定;然后将预测作为嵌入馈入下一步骤。总的来说,控制器具有30个softmax预测,以便预测5个子策略,每个子策略具有2个操作,并且每个操作需要3种参数(操作类型,幅度和概率)。
控制器RNN的训练:控制器用奖励信号训练,这是策略在改进“child model”(作为搜索过程的一部分训练的神经网络)的概括方面有多好。在我们的实验中,我们预留了一个验证集来衡量子模型的泛化。通过在训练集上应用5个子策略(不包含验证集)生成的增强数据来训练子模型。对于小批量中的每个示例,随机选择5个子策略中的一个以增强图像。然后在验证集上评估子模型以测量准确度,其被用作训练复现网络控制器的奖励信号。在每个数据集上,控制器对大约15,000个策略进行采样。
控制器RNN的结构和训练超参数:控制器RNN和训练超参数的体系结构:我们遵循[72]的训练程序和超参数来训练控制器。更复杂的是,控制器RNN是单层LSTM [21],每层有100个隐藏单元,并且两个卷积单元(其中B通常为5)的2x5B softmax预测与每个架构决策相关联。控制器RNN的10B预测中的每一个与概率相关联。子网络的联合概率是这些10B软最大值的所有概率的乘积。该联合概率用于计算控制器RNN的梯度。通过子网络的验证准确度来缩放梯度以更新控制器RNN,使得控制器为坏子网络分配低概率和为良好子网络分配高概率。与[72]类似,我们采用近端政策优化(PPO)[53],学习率为0.00035。为了鼓励探索,我们还使用权重为0.00001的熵惩罚。在我们的实现中,基线函数是先前奖励的指数移动平均值,权重为0.95。控制器的权重在-0.1和0.1之间均匀初始化。尽管先前的工作已经证明其他方法(例如增强随机搜索和进化策略)可以表现得更好甚至更好[30],但我们选择使用PPO来训练控制器。
在搜索结束时,我们将来自最佳5个策略的子策略连接到单个策略(具有25个子策略)。这个包含25个子策略的最终策略用于训练每个数据集的模型。
上述搜索算法是我们可以用来找到最佳策略的众多可能搜索算法之一。有可能使用不同的离散搜索算法,如遗传编程甚至随机搜索来改进本文的结果。
【实验和结果】
实验总结:在本节中,我们通过实验研究AutoAugment在两个用例中的性能:AutoAugment-direct和AutoAugmenttransfer。首先,我们将对AutoAugment进行基准测试,直接搜索竞争激烈的数据集上的最佳增强策略:CIFAR-10,CIFAR-100,SVHN和ImageNet数据集。我们的结果表明,AutoAugment的直接应用显着改善了baseline,并在这些具有挑战性的数据集上产生了最先进的精度。
接下来,我们将研究数据集之间的扩充策略的可转移性。更具体地说,我们将在ImageNet上发现的最佳增强策略转移到细粒度分类数据集,如Oxford 102 Flowers,Caltech-101,Oxford-IIIT Pets,FGVC Aircraft,Stanford Cars。我们的结果还表明,增强策略具有令人惊讶的可转移性,并且对这些数据集上的baseline产生了显着的改进。