参考: https://www.tensorflow.org/tutorials/word2vec
官网的这个教程主要讲word2vec的skip-gram模型,没有讲CBOW,并且训练用的负采样,没有用层次softmax。
动机
动机其实就是分布式假说:
在相同上下文中的词有相似语义(words that appear in the same contexts share semantic meaning)
根据分布式假说表示词的方法分为两类:
- count-based methods (e.g. Latent Semantic Analysis)
- predictive methods (e.g. neural probabilistic language models)
预测方法的代表就是Word2Vec模型,有两种:
- Continuous Bag-of-Words model (CBOW)
- Skip-Gram model
CBOW 从上下文预测目标词,skip-gram正好相反,从目标词预测上下文中的词。
CBOW在许多分布式信息上进行平滑(将整个上下文作为一种情况),大多数情况下这个模型在小一点的数据集上更有效。可是,skip-gram将每一对context-target词作为一种新的情况,在大一点的数据集上的会有更好效果。
噪声对比训练
神经概率语言模型通常用最大似然估计来训练,即最大化给定输入h(历史信息,前n-1个词),输出下一个词wt的概率,使用softmax函数,取log后就是我们想要的准则函数,叫作log-likelihood。这个值的计算代价非常高,因为softmax的分母要计算整个词表的得分。
训练数据的构造方法则为:对于每一个ngram片段,前n-1个词为构成输入数据(词向量拼接),第n个词构成输出类标。由于输出是一个softmax层,则对应词表大小个输出,如果模型训练ok的话,那么这里的第n个词对应的位置输出概率应该最大。
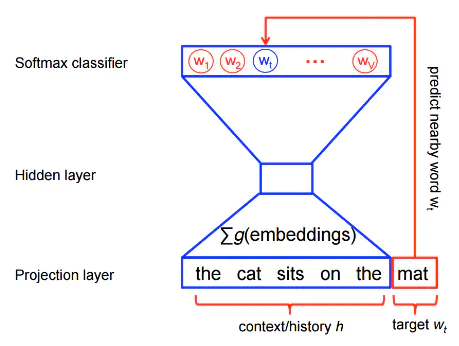
在word2vec中,不再需要计算整个词表每个词的得分。CBOW和skip-gram模型的核心是训练一个二元分类器,将目标词从k个构造的noise words区分出来。CBOW的模型图如下,skip-gram类似只是反过来。

此时目标函数就变为在当前上下文h下,目标词为1的概率log值,加上k个噪声词为0的概率log值的期望。在实践中,我们从噪声分布中采样k个词来近似计算期望。
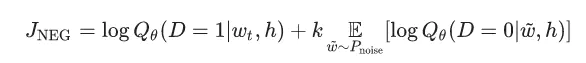
这个目标可以看做是计算一个最优模型,这个模型赋予真实词高概率,赋予噪声词低概率。学术上,这个叫做负采样。这个方法使得训练变得非常有效,因为现在计算损失函数只需要考虑k个噪声词,而不是整个词表。在TensorFlow中,有一个非常相似的损失函数tf.nn.nce_loss()。
Skip-gram模型
举个例子说明训练的过程。
例子为:
the quick brown fox jumped over the lazy dog
上下文可以是语法词法等,这里定义为左边的词和右边的词,窗口大小设置为1,则可以得到context-target训练对如下:
([the, brown], quick), ([quick, fox], brown), ([brown, jumped], fox), ...
即通过quick预测the和brown, 从brown预测quick和fox,这样数据集变为:
(quick, the), (quick, brown), (brown, quick), (brown, fox), ...
目标函数是定义在整个数据集上的,但是实际训练以minibatch为单位计算,batch_size一般为16 <= batch_size <= 512。
想象一下训练过程,假设当前观察到上面第一个pair,即(quick, the),通过quick预测the,假定num_noise=1,并且通过噪声分布(一般就是词的先验分布)采样选出了噪声词sheep,当前目标变为:

优化的模型参数是词向量(embedding vector),求损失函数的梯度,沿梯度方向更新这个参数。当这个过程在整个数据集上不断重复的时候,每个词的词向量就会不断的“变来变去”,直到模型能够成功的从噪声词中区分真实词。
我们可以通过投影到二维空间来可视化学习到的词向量,用到了t-SNE降维技术。
实战
有了前面的理论基础,实现代码就比较容易了。
基础实现:tensorflow/examples/tutorials/word2vec/word2vec_basic.py
训练数据中,输入是batch_size个target word id构成的行向量,类标是batch_size个context word id构成的列向量:
# Input data.
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
词向量通过均匀分布初始化,shape为词表大小*词向量维数,通过tf.nn.embedding_lookup()查表将输入转为词向量形式。
# Look up embeddings for inputs.
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
噪声对比估计的损失按照逻辑回归模型定义,所以对于每一个词,都要有对应的权向量和偏置,通过截尾正态分布初始化(只保留两个标准差以内的值)。
# Construct the variables for the NCE loss
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
计算每个batch上的平均NCE损失
# Compute the average NCE loss for the batch.
# tf.nce_loss automatically draws a new sample of the negative labels each
# time we evaluate the loss.
loss = tf.reduce_mean(
tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))
使用随机梯度下降训练
# Construct the SGD optimizer using a learning rate of 1.0.
optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
最后就是创建session进行训练,详细可看完整源代码。
优化
基础代码只是实现了skip-gram的负采样模型,训练目标为tf.nn.nce_loss(),还可以试试tf.nn.sampled_softmax_loss(),也可以自己定义。
另外,读取数据也不是那么有效(单线程),可以试试New Data Formats中的方法自己定义数据reader,参考代码:
word2vec.py.
如果还想进一步提升效率,可以增加新的算子,参考代码:word2vec_optimized.py