基于openvino的推理性能优化的学习与分析 (二) 官方参考源码benchmark_app的设计逻辑
通过学习sample代码里main函数的流程和注释,Benchmark_app的实现流程整理如下

benchmark支持CPU/GPU/NCS计算棒等多种硬件的单独使用推理和混合使用推理。具体的命令参数是
CPU推理
./benchmark_app -m -i -d CPU
GPU推理
./benchmark_app -m -i -d GPU
CPU/GPU同时推理
./benchmark_app -m -i -d MULTI:CPU,GPU
针对使用不同硬件,需要在第6步的时候进行传不同的配置参数给Inference Engine,这里整理如下
// ----------------- 6. Setting device configuration -----------------------------------------------------------
auto devices = parseDevices(device_name);
if (FLAGS_d == "CPU")
{
//for CPU inference
// limit threading for CPU portion of inference
//设置IE用几个CPU thread跑推理,即用几个CPU的物理核来跑,默认是全用,可能会导致inference时影响到用户自己线程的运行速度
if (FLAGS_nthreads != 0)
ie.SetConfig({{ CONFIG_KEY(CPU_THREADS_NUM), std::to_string(FLAGS_nthreads) }}, device);
// pin threads for CPU portion of inference
//是否将inference的线程绑定在CPU物理核上,默认是不绑定。绑定的好处是可以减少线程在不同CPU核心间迁移的损耗,缺点并不知道默认绑到了哪个CPU核上,如果用户也绑定了自己的线程,有可能会因为绑定了相同的CPU核而影响推理速度
ie.SetConfig({ { CONFIG_KEY(CPU_BIND_THREAD), "YES" } }, "CPU");
//ie.SetConfig({ { CONFIG_KEY(CPU_BIND_THREAD), "NO" } }, "CPU");
std::cout << " CPU_BIND_THREAD :" << ie.GetConfig("CPU", CONFIG_KEY(CPU_BIND_THREAD)).as() << std::endl;
// for CPU execution, more throughput-oriented execution via streams 默认使用throughtput auto模式,由openvino自己确定当前平台上推理的stream数量
ie.SetConfig({ { CONFIG_KEY(CPU_THROUGHPUT_STREAMS),"CPU_THROUGHPUT_AUTO" } }, "CPU");
//也可以自己手工指定nstream的数量
//ie.SetConfig({ { CONFIG_KEY(CPU_THROUGHPUT_STREAMS),std::to_string(1) } }, "CPU");
cpu_nstreams = std::stoi(ie.GetConfig("CPU", CONFIG_KEY(CPU_THROUGHPUT_STREAMS)).as());
std::cout << "CPU_THROUGHPUT_AUTO: Number of CPU streams = " << cpu_nstreams << std::endl;
}
else if (FLAGS_d == "GPU")
{
//for GPU inference 默认使用throughtput auto模式,由openvino自己确定当前平台上推理的stream数量
ie.SetConfig({ { CONFIG_KEY(GPU_THROUGHPUT_STREAMS),"GPU_THROUGHPUT_AUTO" } }, "GPU");
//ie.SetConfig({ { CONFIG_KEY(GPU_THROUGHPUT_STREAMS),"1" } }, "GPU");
gpu_nstreams = std::stoi(ie.GetConfig("GPU", CONFIG_KEY(GPU_THROUGHPUT_STREAMS)).as());
std::cout << "GPU_THROUGHPUT_AUTO: Number of GPU streams = " << gpu_nstreams << std::endl;
}
else if (FLAGS_d == "MULTI:CPU,GPU")
{
//同时使用CPU/GPU推理时,不绑定线程到具体CPU核上
ie.SetConfig({ { CONFIG_KEY(CPU_BIND_THREAD), "NO" } }, "CPU");
std::cout << " CPU_BIND_THREAD :" << ie.GetConfig("CPU", CONFIG_KEY(CPU_BIND_THREAD)).as() << std::endl;
// for CPU execution, more throughput-oriented execution via streams
ie.SetConfig({ { CONFIG_KEY(CPU_THROUGHPUT_STREAMS),"CPU_THROUGHPUT_AUTO" } }, "CPU");
//ie.SetConfig({ { CONFIG_KEY(CPU_THROUGHPUT_STREAMS),std::to_string(1) } }, "CPU");
cpu_nstreams = std::stoi(ie.GetConfig("CPU", CONFIG_KEY(CPU_THROUGHPUT_STREAMS)).as());
std::cout << "CPU_THROUGHPUT_AUTO: Number of CPU streams = " << cpu_nstreams << std::endl;
//for GPU inference
ie.SetConfig({ { CONFIG_KEY(GPU_THROUGHPUT_STREAMS),"GPU_THROUGHPUT_AUTO" } }, "GPU");
//ie.SetConfig({ { CONFIG_KEY(GPU_THROUGHPUT_STREAMS),"2" } }, "GPU");
gpu_nstreams = std::stoi(ie.GetConfig("GPU", CONFIG_KEY(GPU_THROUGHPUT_STREAMS)).as());
std::cout << "GPU_THROUGHPUT_AUTO: Number of GPU streams = " << gpu_nstreams << std::endl;
//不太清楚,结合上面的bind thread为no的设置,应该是要保留一些CPU资源给GPU推理用,因为GPU推理时的控制以及数据传递都需要CPU参与
ie.SetConfig({ { CLDNN_CONFIG_KEY(PLUGIN_THROTTLE), "1" } }, "GPU");
std::cout << "CLDNN_CONFIG_KEY(PLUGIN_THROTTLE), 1" << std::endl;
} 第9步推理的过程看代码非常痛苦,使用了大量的智能指针之类的C11语法,其实整个流程还是非常简单的,整理如下,
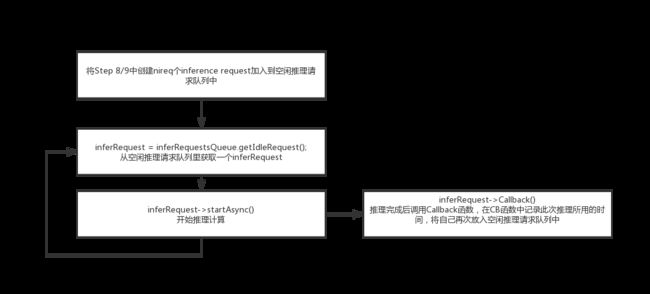
可以看出来,在每次推理过程中并没有在推理前写入更新输入数据,也没有在推理结束后读出推理结果,整个过程只是在统计纯推理所花费的时间。
简单总结一下,要获得OpenVINO的最大throughput吞吐量,需要
- 同时创建多个Inference request, 并且使用Async推理模式是他们并行工作来获取最大性能
- Async结合Callback函数效率最高
- 纯CPU推理时,可以适当结合推理线程绑定CPU核心的方法提高效率,但是也可能会有负面影响 (无法指定绑定哪个物理核心,以至和其他程序绑到了同一个物理核上,以后也许openvino会改进)
- 可以通过指定使用多少CPU thread的方式来防止Inference Engine使用过多CPU资源
- GPU/CPU混合使用时需要为GPU保留一些CPU资源,以免出现GPU吃不饱的问题影响效率
- 不知道当前硬件需要设置多少个并发推理stream数量时,可以使用"XXX_THROUGHPUT_AUTO" 来让OpenVINO自动为你分配stream数量,然后可以用ie.GetConfig()接口来获得自动分配的stream数量
- 对CPU而言,每个stream对应一个inference request. 对GPU而言,每个stream对应2个inference request. (这个可以通过在step 8的nireq = exeNetwork.GetMetric(key).as
();来验证)