rdb存储引擎
背景
在千万级并发的分布式KV存储系统设计实现和运营实践一文中,我们介绍了我们的vde分布式kv存储系统,vde系统是我们借鉴tair系统的框架和部分代码自主研发的,但是我们的vde系统还存在着一些不足:
- kv数据结构对更新操作不够友好,业务更新时需要先get数据,修改其中部分数据后,再将全量数据set到系统中,这种方式首先是对业务操作不友好,其次是额外增加了不必要的网络开销。
- 暂时只支持kv数据结构,不支持其他的数据结构,对业务场景的支持不够丰富。
在上面的背景下,我们有必要基于我们vde系统的优秀的分布式的架构,嵌入功能更强大的存储引擎,以支持更丰富的数据结构和实现更为全面的功能,为相关业务场景提供更友好的业务体验。正是在这种背景下,我们研发了我们自己的分布式vrdb系统,系统整体的框架和架构设计与我们的vde系统类似,同时,我们基于redis存储内核研发了我们自己的rdb存储引擎,rdb存储引擎应用在我们的分布式vrdb系统中,支持string、list、set、zset、hash这5种数据结构,同时,支持类似rdis中大部分的操作。
我们没有选择redis cluster的原因有如下几点:
1. redis cluster暂时还未在大规模、高并发的生产环境验证过,且系统内有存在bug的风险,redis cluster3.x版本中数据迁移时会存在丢数据的风险,因为3.x的版本中迁移时会将不存在过期时间的记录设置过期时间的bug(后续版本已修复)。
2. redis cluster采用gossip协议来保证集群的一致性,集群达成一致的速度取决于消息发送的频率,频率过高,则网络通信的开销会很大。同时,redis节点内部是单线程处理的,在集群模式下,单线程的节点容易因为各种各样的原因产生节点“假死”问题,进而导致集群不稳定,特别的,在高并发的环境下,这类问题的影响会更明显,要么造成大的请求波动,要么造成集群不稳定。
3. redis cluster严重依赖外部脚本对进行管理,无法自动管理,无法自动发现节点、无法自动resharding,必须要通过外部脚本来操作,需要过多的人工介入和干预。
4. 我们的VDE的分布式的系统架构设计比较优秀,支持动态扩缩容、支持自动容错管理、支持动态扩展、高可用等,且在高并发的业务场景下表现稳定,已经过了近两年的生产环境检验,我们完全可以改造redis的存储内核得到我们的rdb存储引擎,然后在这套分布式架构下改造我们的框架流程,嵌入我们的rdb存储引擎。
分布式vrdb系统是我们设计实现的一套类分布式redis系统,目标在于为高并发场景下提供一套稳定的分布式redis集群解决方案。当前系统已上线并已小规模运营,接入了部分线上业务,稳定运营了近4个月,部署节点50+,存储记录数10亿+,峰值并发90w/min。
底层数据结构
我们的rdb存储引擎是基于redis 2.8的源码进行改造,内部的核心数据结构和内部存储原理与redis相同,我们的rdb存储引擎对内部的数据结构和操作进行了封装,适配在我们的分布式系统框架内部。
sdshdr和sds
sds数据结构是redis中字符串的存储方式,其中,sdshdr、sds需要配合使用,sdshdr存储了sds相关的元数据,redis中原有sdshdr只包含len、free、buf三个字段,我们的rdb存储引擎内部对原有的sds结构进行了改造,加入了一些其他字段以配合我们的分布式vrdb系统的设计和实现。

version: 作为保留字段,暂时未使用。
bucketid:用于系统中判断key是否存储在对应的位置,在数据迁移时会进行修改。
logiclock:赋值为某时刻某个db的时间戳,我们的一个area对应多个db,这个字段用于清空某个area的功能,当清空某个area时,我们会设置area对应所有的db的logiclock为当前时间戳,清空的时候判断某个key的logiclock是否小于db的时间戳,如果小于,则删除该key。
dict
存储结构
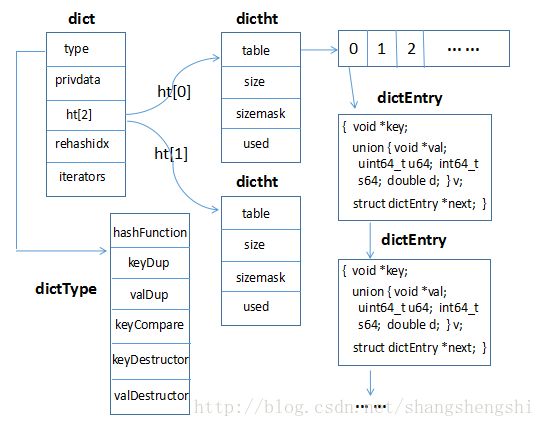
如上所示即为redis中dict数据结构的内部原理,dict数据结构是redis中基础和核心的数据结构,是redis中大部分数据存储的基础。
dictType
dictType中包含hashFunction、keyDup、valDup、keyCompare、keyDestructor、valDestructor这6个函数指针,在dict初始化的时候即会指定dictType这6个函数指针,hashFunction主要是用于计算key对应的hash值,将该hash值与dictht中sizemask做&运算可得到最终要存储的dictht中table中的bucket值。keyDup、valDup主要是将key、value复制到dictEntry中对应值的方法。keyCompare主要是dict中查找过程中的key比较方法。keyDestructor、valDestructor是在删除dict中dictEntry时释放key、value的析构方法。privdata
初始化dict时传入的私有数据对象。ht[2]
为dict中dictht数组,有两个元素为ht[0]和ht[1],ht[0]是dict稳定状态下用到的对象,ht[1]是dict在expand过程中用到的,用于dict的平滑rehash过程。rehashidx
标识dict是否处于rehash过程,如果为-1,则表示没有处于rehash过程,如果不为-1,则表示处于rehash过程,且对应的值为下一个要迁移到ht[1]的bucket位置。iterators
主要是在使用dict的迭代器遍历dict的时候,让dict不要做rehash的操作,因为如果dict通过迭代器获取了某个entry,如果后面做了rehash的操作,获取的entry对象的链表关系有可能会被修改,也会导致迭代器异常。
expand和rehash过程
dict写入过程中,发现dict中的hashtable需要调整的时候,会启动dict的rehash过程。dict的rehash过程会新创建一个ht[1]的hashtable,会把ht[0]上所有的entry在ht[1]的hashtable上做一次rehash重定位,然后将ht[0]上的所有entry迁移到ht[1]上的hashtable上,期间的所有更新都会落到ht[1]上,迁移完成后再把ht[1]赋值给ht[0],完成整个rehash过程。
dictht
dictht对应实际的数据存储结构,其中,table对应内部的hashtable,size对应hashtable的bucket数,sizemask用于hash值与bucket的映射,具体值为size-1,used为hashtable中的元素个数,dict中有相关的阈值机制判断hashtable是否需要扩容,在允许resize的情况下,used/size > dict_force_resize_ratio时会自动resize,dict_force_resize_ratio默认为5。
ziplist

如上图所示即为redis中ziplist数据存储结构。
- ziplist包含header、entrys、ZIP_END三部分,其中header部分包含bytes、offset、length三个字段,bytes表示ziplist的所有字节数,offset表示最后一个entry的偏移量,length对应ziplist中entry的个数。
- entry是实际存储数据的结构,由prev_entry_bytes_length(prevlen)、encoding&length、buffer三部分组成,prevlen表示前一个entry的长度, encoding&len存储本entry的encoding跟length、buffer存储实际的数据。
- ZIP_END标识ziplist的结束符,1个字节长度表示,值为255。
list
list数据结构为通用的list结构,如下图所示:

其中,head、tail分别指向list的首节点和尾节点,dup、free、match分别对应list中节点相关的操作,len为list中元素个数,即list的长度。
intset
intset为redis中专门用于存储整型数据集合的结构,具体结构如下:

1. encoding表示intset的编码类型:INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT64,length表示intset中元素个数。contents占用的空间buffer大小即为length * encoding。
2. intset中元素插入时会对元素进行排序,因此,intset中的元素是有序的。此外,每次插入时,会判断新插入元素编码值是否大于intset的已有编码值,如果大于,则需要为intset按更大的编码值重新分配内存,这里元素和intset的编码值对应的就是单个元素占用几个字节。
skiplist
跳跃表(Skiplist)是一种随机化数据结构,在查找、插入、删除等操作的时间复杂度均为O(logn),同时,实现上相对于红黑树更简单,redis中用于存储有序集合的底层数据结构除了intset外,另一个就是Skiplist的数据结构。
skiplist具体结构如下:

- 单纯比较性能,跳跃表和红黑树相差不大,但在并发的环境下跳跃表锁的代价较低,不同线程争锁的代价相对较小,而红黑树更新涉及较多的节点,争锁的代价相对较高了,性能因此不如跳跃表。
- 红黑树在频繁插入和删除的场景下,可能需要做一些rebalance操作,也会对性能有一定影响,特别是在并发的场景下影响会更为明显。
Redis中对原有的跳跃表实现进行了修改,包括span的设计、score值可以重复,score重复时比较对应元素值、添加tail与backward指针等,从而实现了排序功能,从尾至头反向遍历的功能等。
- 允许重复的score值,多个不同的元素(member)的score值可以相同。
- 进行元素对比的时候,当score值相等时,需要对元素值大小进行比较。
- 跳表中保存了一个tail指针,即跳跃表的表尾指针,便于进行逆序遍历。
数据存储
string存储
string数据存储基于底层的dict数据结构实现的,用于简单的kv操作,存储时先根据key进行hash,得到hash值后与dict中dictht.sizemask进行与运算,得到对应dictht.table的bucket值,然后将kv pair设置到对应bucket的entry list中。
list存储
list数据存储基于底层的ziplist或list数据结构实现。
ziplist的优点是空间占用小,在元素过长的情况下,ziplist的更新代价也会比较大,因此,存在长度过长的元素的情况下,适合于用底层的list数据结构实现。
在我们的rdb存储引擎中,默认采用ziplist存储,当有元素长度超过配置的list_max_ziplist_entries时,底层的数据结构会转换为list数据结构。
由于ziplist的更新代价较大,因此,适用于list中元素个数不多的情况,在元素个数较多的情况下,适用于用底层的list数据结构实现。
在我们的rdb存储引擎中,默认采用ziplist存储,当元素个数超过配置的list_max_ziplist_value时,底层的数据结构会转换为list数据结构。
set存储
set数据存储基于底层的intset或dict数据结构实现,当set中所有元素均为整型时,采用intset数据结构存储,且数据在intset中是有序存储的。intset数据存储整型数据相对于dict结构存储空间占用更大,但当元素个数过多时,数据操作的代价会变大,因此,这种情况下,底层会转化为dict中hashtable的方式存储。
zset存储
zset数据存储基于底层的skiplist数据结构实现,存储的是有序的数据集合,skiplist中按score值排序,score值相等的情况下按元素值排序。
hash
hash数据存储基于底层的ziplist或dict数据结构实现,默认情况下是用ziplist实现的,与list中数据存储类似,我们也做了如下的一些处理:
- 当有元素长度超过配置的hash_max_zipmap_value时,底层的数据结构会转换为dict数据结构。
- 当元素个数超过配置的hash_max_zipmap_entries时,底层的数据结构会转换为dict数据结构。