带你彻底掌握 Lambda 表达式(上)
更多技术文章,欢迎关注我的微信公众号:码不停蹄的小鼠松(微信号:busy_squirrel),也可扫下方二维码关注获取最新文章哦~

说明:
由于 Lambda 表达式涉及的周边知识点实在太多,因此拆分为上、下两篇文章讲解,本篇为上篇,下篇随后放出,大家可在我公众号中查找。
目录介绍:

上篇,主要讲 1~4 章节,下篇,主要介绍 5~8 章节。
序言
JDK8 日渐成为项目开发中的主流。
但平时在和很多小伙伴的交流和面试中,发现很多人仍停留在 JDK7 及以前的认知层面,Lambda 表达式、方法引用、Stream 流、default 关键字,很少使用,甚至还有不少小伙伴不知道怎么用!!
不客气的说,不掌握 JDK8 的新特性,面试通过基本很难很难。换位思考,若不掌握,你面试不慌吗?
而 Lambda 表达式,更是 JDK8 新特性中的重中之重,它能够简化我们的传统操作模式。
本文会帮你详细梳理 Lambda 表达式的前世今生,有原理讲解,有示例实战,助力你面试起飞。
文章略长,但一定是干货满满的,对于技术文章而言,短小精悍的特点并不是好事,因此我写的文章都偏长,注重干货,注重前因后果,做到知其然更要知其所以然。如果你有耐心读下去,一定会有较大收货。如果没时间看,可收藏留以备用~
在具体描述 Lambda 表达式之前,我们需要补充一些基础知识:什么是函数式接口。
1. 函数式接口的定义
提到函数式接口( functional interface ),就牵扯到一个注解:@FunctionInterface。
所谓函数式接口,是指的一类添加了 @FunctionInterface 注解的接口。换言之,只要一个接口有@FunctionInterface 注解,那这个接口就是函数式接口。
举个例子就明白了。
当你在对任务 taskA 处理时,如果想异步处理,不影响主干流程的继续进行,你会怎么做?
a) 初级版:新增一个类,实现 Runnable 接口
你会说很简单呐,另起一个线程去执行任务 taskA 就可以了呀,喏,如下:
/**
* @author: sss
*/
public class TaskAThread implements Runnable {
@Override
public void run() {
// process taskA
...
}
}
public class Main {
public static void main(String[] args) {
// new 一个新线程,执行任务A
Runnable taskA = new TaskAThread();
new Thread(taskA).start();
// 主线程继续做其他事情
System.out.println("do other things...");
}
}
这种方式是可以实现,但有没有其他方式呢?
b) 进阶版:使用匿名内部类
有些小伙伴明显的发现了上面代码中的问题:繁琐!!只是为了创建一个线程并使用它的 run() 方法,还要新增一个类,没有必要,直接使用匿名类就解决啦:
public class Main {
public static void main(String[] args) {
// 通过匿名类来创建一个新线程,执行任务A
Runnable taskA = new Runnable() {
@Override
public void run() {
// process taskA
...
}
};
new Thread(taskA).start();
// 主线程继续做其他事情
System.out.println("do other things...");
}
}
通过匿名类的方式,省去了新增一个类的操作,大大简化。但若使用 Lambda 的方式,会更加简洁。
c) 高级版:使用 Lambda 表达式
public static void main(String[] args) {
// 通过匿名类来创建一个新线程,执行任务A
new Thread(() -> {
System.out.println("正在异步处理 taskA 中...");
// do things
...
}).start();
// 主线程继续做其他事情
System.out.println("do other things...");
}
有没有发现很神奇,类似() -> {...}的这种箭头式写法竟然能通过编译!而且还能运行(不信的小伙伴可以试试)!这种就是 Lambda 表达式的其中一种写法,不理解的小伙伴也没关系,我们后面会详细解释。
也许这种 Lambda 写法很多小伙伴见过,并习以为常,但为什么可以运行,你知道根本原因吗?
这里就体现出函数式接口的作用了。我们去看一下 JDK7 和 JDK8 中关于 Runnable 接口的定义,如下。大家有发现什么不同点了吗?
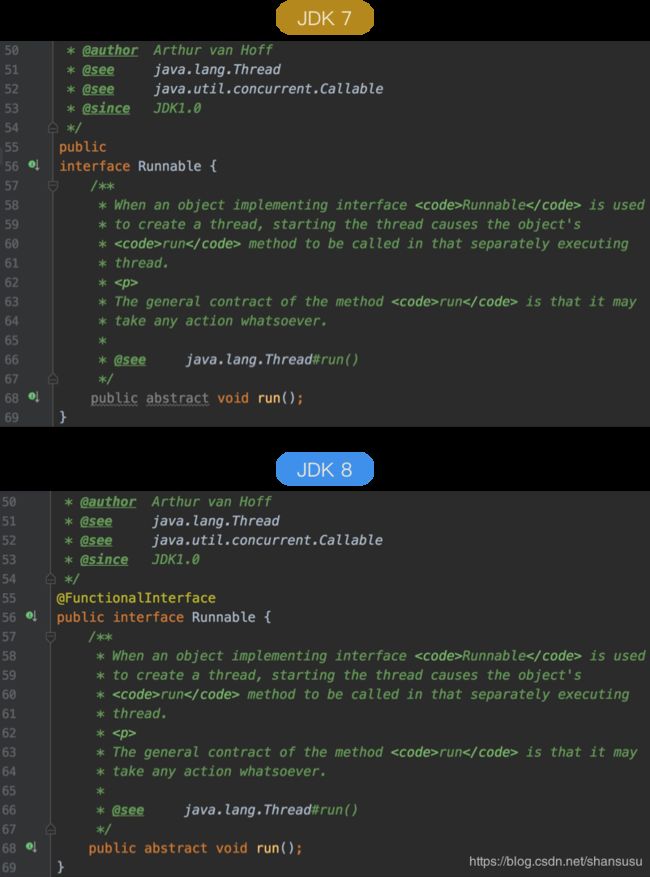
眼尖的小伙伴一定发现了,JDK8 中多了个注解 @FunctionalInterface。这就是为何能在 JDK8 中可以使用这种箭头式的 Lambda 写法。
本小节最开始时我们也提到了此注解。从上图也能看出,@FunctionalInterface 是 JDK8 中新引入的一个注解,它定义了一类新的接口(即函数式接口),该类接口有且只能有一个抽象方法。
它主要用于编译期的错误检查,如果一个接口不包含抽象方法(eg: Serializable、Cloneable 等标记接口),或者包含多个抽象方法,都不符合 @FunctionalInterface 注解的定义,加了就会出错,如下这种:
// 错误示例 1
@FunctionalInterface
interface InvalidInterfaceA {
}
// 错误示例 2
@FunctionalInterface
interface InvalidInterfaceB {
void testA();
void testB();
}
正确示范:
@FunctionalInterface
interface InvalidInterfaceC {
void testC();
}
@FunctionalInterface
interface InvalidInterfaceD {
void testD();
default void testE() {
System.out.println("this is a default method.");
}
}
@FunctionalInterface修饰的接口,只能有一个抽象方法,但并代表只能有一个方法声明,像上面的 InvalidInterfaceD 接口,还有 default 关键字修饰的 testE() 方法,但这是一个有默认实现的方法,并不是抽象方法,因此接口 InvalidInterfaceD 依然符合函数式接口的定义。
另外,我们仔细看下注解的描述片段:
上面截图中的信息量较大,分为两块内容。
第一块内容是使用 @FunctionalInterface 注解需满足的 2 个条件:
- 必须是接口,不能是注解、枚举或类,限定了使用的类型范围
- 被注解的接口,必须满足函数式接口的定义,即只能有一个抽象函数
第二块内容是 @FunctionalInterface 注解的功能已内置于编译器的处理逻辑中:不管一个接口是否添加了 @FunctionalInterface 注解,只要该接口满足函数式接口的定义,编译器都会把它当做函数式接口。
看下面的例子:
interface MathOperation {
int operation(int a, int b);
}
public static void main(String args[]) {
MathOperation addition = (int a, int b) -> a + b;
}
上面的 MathOperation 接口,并没有添加 @FunctionalInterface 注解,但依然可以使用 Lambda 表达式,就是因为它符合函数式接口的定义,JDK8 的编译器默认将其当做函数式接口(上面代码中的箭头表达式不懂没关系,我们下面会详细讲解)。
在 JDK8 中,推出了一个新的包:java.util.function,它里面内置了一些我们常用的函数式接口,如 Predicate、Supplier、Consumer 等接口。
2. 什么是 Lambda 表达式
总结了很久,发现还是很难用语言来定义什么是 Lambda 表达式,它更适合结合示例来说明。
2.1 示例 1
还是以上面的异步线程执行任务 A 为例。在 Lambda 表达式之前,我们最精简的写法就是使用匿名类,但若用 Labmda 表达式,则可直接简化成一行代码。看下面代码示例的对比:
public static void main(String[] args) {
// 使用匿名内部类
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("正在异步处理 taskA 中...");
}
}).start();
// 使用 Lambda 表达式
new Thread(() -> System.out.println("正在异步处理 taskA 中...")).start();
}
上面的示例中,使用 Lambda 表达式,进一步简化了匿名类,这也是 Lambda 表达式最常用的功能。
2.2 示例 2
为进一步强化大家对 Lambda 表达式的理解,再举一个最常用的示例,集合类的遍历操作。在 JDK8 以前,List 的遍历操作,要么用 for 循环,要么用迭代器(Iterator):
public static void main(String[] args) {
List<String> strList = Arrays.asList("a", "b", "c", "d");
// 方式1
for (int i = 0; i < strList.size(); i++) {
System.out.println(strList.get(i));
}
// 方式2,语法糖,本质还是下面的方式3
for (String str : strList) {
System.out.println(str);
}
// 方法3
Iterator<String> iterator = strList.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
上面的代码中,方式 2 是一种语法糖,本质上还是方法 3,大家可通过编译之后的 .class 文件来查看。
但在 JDK8 中,我们可使用 forEach() 方式来实现 Lambda 表达式下的遍历操作。
strList.forEach(str -> System.out.println(str));
进一步探究,forEach() 是怎么做到的,看下其源码:
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
/**
* Represents an operation that accepts a single input argument and returns no
* result. Unlike most other functional interfaces, {@code Consumer} is expected
* to operate via side-effects.
*
* This is a functional interface
* whose functional method is {@link #accept(Object)}.
*
* @param the type of the input to the operation
*
* @since 1.8
*/
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
forEach() 的形参是一个 Consumer 对象,而 Comsumer 接口又是一个有 @FunctionalInterface 注解的函数式接口,其抽象方法是 accept(T t)。
此时,如果我们撇开 Lambda 表达式,使用匿名类,依然可以做到,如下:
strList.forEach(new Consumer<String>() {
@Override
public void accept(String str) {
System.out.println(str);
}
});
既然 Consumer 是一个函数式接口,就可以使用更简洁的 Lambda 表达式:
strList.forEach(str -> System.out.println(str));
2.3 小结
有了前面两个示例,你应该对 Lambda 表达式有个大体的印象了。
若一个方法的形参是一个接口类型,且该接口是一个函数式接口(即只有一个抽象方法),那么就可以使用 Lambda 表达式来替代其对应的匿名类,达到易读、简化的目的。
通常,Lambda 表达式的格式如下:
() -> {...}
或
(xxx) -> {...}
从前面的示例也可以看到,Lambda 表达式其实就代表了一个接口的实例对象,并且这个接口还得是一个函数式接口,即只能有一个抽象方法,这个抽象方法的具体实现,就是 Lambda 表达式中箭头的右侧 body 部分。
3 Lambda 表达式特性及示例
前面我们初识了 Lambda 表达式,那么,它又有哪些特性呢?
- 特性 1:由箭头将表达式分为左、右两个部分
必须是形如 () -> {...} 的形式。
- 特性 2:入参可为零个、一个、多个
当为零个时,箭头左侧的括号不可省略:
() -> {System.out.println("test expression!");};
() -> 123;
当入参为 1 个时,箭头左侧的圆括号可省略:
(x) -> {System.out.println(x);};
x => x + 2;
当入参为多个时,左侧括号不能省略:
(x, y, z) -> {
System.out.println(x);
System.out.println(y);
System.out.println(z);
};
以上都是合法表达式。但是,这并不意味着他们可以独立存在。若不给这些表达式赋左值,则编译器会报错:Not s statement。
前面我们也有提到,Lambda 表达式其实是一个实例对象,因此,赋左值,自然是赋值给某个特定类型的实例。它是如何赋值的呢?可手动指定,也可根据 IDE 自动生成(此时编译器会自动推断左值类型)。在正常使用过程中,我们往往都会有目的的手动赋左值。
- 特性 3:入参类型声明可省略,编译器会做自动类型推断
List<String> strList = Arrays.asList("a", "b", "c", "d");
strList.forEach(str -> {
System.out.println(str);
});
上方代码中,Lambda 表达式中的 str 局部变量,不需要再次声明类型,因为编译器会从 strList 变量中推断出 str 变量的类型为 String。
- 特性 4:表达式右侧的 body 中,只有一条语句,则可省略大括号,否则不可省略
上面的 strList 变量的 forEach() 方式的遍历,可简化为如下形式:
strList.forEach(str -> System.out.println(str));
- 特性 5:表达式的返回值是可选的
上面的 forEach() 方式,就是没有返回值的,也可认为是 void。
4. 为何引入 Lambda 表达式
我们先来简述下几种常见的编程范式。
4.1 几种常见的编程范式
编程范式代表了计算机编程语言的典型风格和编程方式,通俗来说,编程范式就是对各种编程语言的分类,分类的依据,就是对各类编程语言的行为和处理方式进行抽象拔高,再看是否都是一类。
这么说比较抽象,举几种常见的编程范式:命令式编程、声明式编程和函数式编程。
我们看一个具体示例:
你眼前有一个水果篮,里面放了一堆的苹果和桔子。这时候,你老板跟你说:“小张,交给你一个事儿,你从水果篮中一个个拿出水果,如果是桔子,则放回,继续从水果篮中拿下一个水果,如果是苹果,再看是否有 M 标签,如果没有,则放回,如果有 M 标签,再看这个苹果是否已坏掉,如果坏掉,则返回,如果没坏掉,则把该苹果挑出来”,然后你很快就按老板的指示圆满完成了任务。
这时,如果你老板是程序员,你是计算机,那么你老板就在使用命令式编程。他会把每一步该怎么做都告诉你,然后你只需要严格按照他要求的去做就可以完成任务。
但是,我们考虑另外一种情况:
你老板跟你说:“小张,交给你一件事,把水果篮里的贴了 M 标签的没有坏掉的苹果都捡出来”。然后你按照老板的要求,一个个把符合条件的苹果捡出来。
此时,老板并没有告诉你该怎么一步步的把符合条件的苹果捡出来,它只是告诉了你他想要的是什么(what),但并没有告诉你该怎么做(how),这种就是声明式编程。
一般来说,绝大多数的程序员都是使用的命令式编程的风格,像 Java、C、C++ 等,都属于命令式编程语言,它们都需要由程序员来严格指定每一步该怎么做,语言本身是不会做任何特殊逻辑处理。这和冯诺依曼体系的计算机一致,指令存储在内存中,由 CPU 一条条执行指令做运算,并将数据再放回内存。
从编程范式的角度来看,像 Java、C++ 等这些高级编程语言,本质上和更接近机器语言的汇编语言没有区别,都是基于冯诺依曼体系计算机模式的思想,都是命令式编程。相比汇编语言,高级语言只是更符合我们人类认知的习惯和便于理解、编写,但编译后,还是变成了天书般的机器语言。
我们经常接触的 SQL 语句,其实就是声明式编程。如下面的语句:
## 找出所有学生的数学成绩
select name,
age,
course,
score
from student
where course= "math";
上面的 SQL 语句,只是声明了需要什么(找出所有学生的数学成绩),但至于怎么找,语言层面不需要关心,交给数据库系统来处理。
函数式编程,是近几年火起来的一种编程范式,但其早就存在于我们周围,想 JavaScript 就是一种函数式编程语言。函数式语言最鲜明的特点,是允许将函数作为入参传递给另一个函数,且也可以返回一个函数。像我们常用的 Java 语言,其函数是无法独立存在的,必须声明在某个类的内部,换句话说,Java 中的函数是依附于某个特定类的,且服务于该类的域变量。因此若要按等级来划分,对象或变量的级别是高于函数的。但在函数式编程语言中,函数可当做参数传递,也可作为返回值,我们称之为高阶函数。看下面的示例:
def sum(x):
def add(y):
return x + y;
return add;
sum2 = sum(2);
elementB = sum(7);
a = sum2(3); # 2 + 3 = 5
b = elementB(1); # 7 + 1 = 8
print a; # 输出5
print b; # 输出8
示例中,sum() 函数内部定义了add() 函数,两者各自有一个入参,且 sum() 函数的返回值是 add() 函数。那么这里的 sum() 就是一个高阶函数。它做了件什么事情呢?很简单,求两个数值的和。在 Java 中,它是怎么实现的呢?
public int sum(int x, int y) {
return x + y;
}
这是 Java 中的写法,但函数式编程的计算思想和我们常规理解的不同,它使用了两个函数来实现。比如前面的示例中,要计算 2+3,首先通过函数 sum(2) 得到一个变量 sum2,它同时也是一个函数,即 add() 函数,我们再次把数字 3 作为参数传进去:sum2(3),就得到了求和的值 6。
通过以上的示例对比,就能发现函数式编程的核心思想:通过函数来操作数据,复杂逻辑的实现是通过多个函数的组合来实现的。相比声明式编程和命令式编程,它是一种更高级别的抽象:汇编语言要求我们如何用机器能理解的语言来写代码(指令);高级语言如 Java、C++ 则是使用易于人理解的方式,但如何做,还需要我们来一步步设定,仍未逃脱指令式的思维模式;函数式编程,通过函数来操作数据,至于函数内部做了什么,交给其他函数来组合实现。
4.2 为何引入 Lambda
因为 Lambda 表达式是属于函数式编程的范围(将函数视作变量或对象),且后面要讲到的 Stream 流,都属于函数式编程的范围,所以,这个问题的问法是可以再扩大化,即:
为何会引入函数式编程的用法?
a) 原因 1:使得代码更简洁,可读性强
如果你有仔细阅读前面的介绍,你会发现,Lambda 表达式本质上就是一个函数,就是其对应的函数式接口的那个唯一抽象方法的具体实现!再来回顾一下代码:
new Thread(() -> System.out.println("this is a Lambda expression!")).start();
Thread 类的有参构造函数 Thread(Runnable runnable),本来参数是一个 Runnable 对象,
但 Java 作为一枚面向对象的编程语言,除了像 int、double、char 等 8 种基本数据类型,其他的一切都是对象,包括类(class)、接口(interface)、枚举(Enum)、数组(Array)。但函数并不是对象,它只能依附于对象而存在,按层级划分的话,函数是低于对象的,它是无法作为一个方法的入参或者返回值的。
在这种限制下,Java 的部分功能代码就难免出现臃肿的现象。比如:难看又无法避免的匿名内部类、集合类的过滤、求和、转换等操作。而 Lambda 表达式的出现,就避免了这种臃肿。
而函数式编程的优点就是使用简洁、可读性高(只看函数名就知道要做什么操作),如下的 Stream 流操作:
List<String> nameList = Arrays.asList("tom", "kate", "jim", "david");
List<String> newNameList = nameList
.stream()
.filter(name -> name.length() > 3)
.map(name -> name.toUpperCase())
.sorted()
.collect(Collectors.toList());
上面代码要实现的功能一目了然,没有大量的匿名内部类,没有多余的中间变量,没有复杂的逻辑计算。若摒弃 JDK8 的写法,则需要使用又臭又长的代码,耗费两倍不止的时间才能实现。
所以,从可读性、易用性角度讲,函数式编程的写法完胜 JDK7 以前的 Java 式写法。
b) 原因 2:传递行为,而不止是传递值,更便于功能复用
因为函数是代表了一连串行为的集合,代表的是一组动作,而不止是一个数据,举个例子就明白了,看下面的示例:
// 给定一个整数集合
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
// 求所有元素的和
private Integer sumAll(List<Integer> list) {
int sum = 0;
for (Integer ele : list) {
sum += ele;
}
return sum;
}
// 求所有偶数元素的和
private Integer sumEven(List<Integer> list) {
int sum = 0;
for (Integer ele : list) {
if (ele % 2 == 0) {
sum += ele;
}
}
return sum;
}
// 求所有奇数元素的和
private Integer sumOdd(List<Integer> list) {
int sum = 0;
for (Integer ele : list) {
if (ele % 2 == 1) {
sum += ele;
}
}
return sum;
}
// 求所有大于3的元素的和
private Integer sumLargerThan3(List<Integer> list) {
int sum = 0;
for (Integer ele : list) {
if (ele > 3) {
sum += ele;
}
}
return sum;
}
作为一个有追求的程序员,对上面的这种代码是不能忍的,重复度太高了有木有!除了元素的判断条件不同,其他处理方式都相同。
那,对于上面的代码,我们能怎么优化呢?大家也许会想到策略模式,每一种处理,都对应一个不同的计算策略,设计模式用起来:
public interface sumStrategy {
Integer sum(List<Integer> list);
}
public class SumAllStrategy implements sumStrategy {
@Override
public Integer sum(List<Integer> list) {
int sum;
for (Integer ele : list) {
sum += ele;
}
return sum;
}
}
public class SumEvenStrategy implements sumStrategy {
@Override
public Integer sum(List<Integer> list) {
...
}
}
// 实际调用
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
// 示例1:当想求所有元素的和时,使用 SumAllStrategy 类
Strategy strategy1 = new SumAllStrategy();
strategy1.sum(list);
// 示例2:当想求所有偶数元素的和时,使用 SumEvenStrategy 类
Strategy strategy2 = new SumEvenStrategy();
strategy2.sum(list);
虽然设计模式用起来了,逼格也高起来了,然并卵,代码量依然没有减少,代码并没有做到复用的目的。
有了 Lambda 表达式,以上的一切都变得简单起来,我们可以依赖一个函数式接口:Predicate 接口。
// @since 1.8
@FunctionalInterface
public interface Predicate<T> {
/**
* Evaluates this predicate on the given argument.
*
* @param t the input argument
* @return {@code true} if the input argument matches the predicate,
* otherwise {@code false}
*/
boolean test(T t);
...
}
里面唯一的抽象方法 test(T t),一个入参,然后返回一个布尔值,很符合这里的元素判断。
Lambda 的使用如下:
private Integer sum(List<Integer> list, Predicate condition) {
int sum = 0;
for (Integer ele : list) {
if (condition.test(ele)) {
sum += ele;
}
}
return sum;
}
// 实际使用
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
// 示例1:求所有元素的和
int sum = sum(list, x -> true);
// 示例2:求所有偶数元素的和
sum = tester.sum(list, x -> (int)x % 2 == 0);
// 示例3:求所有大于5的元素的和
sum = tester.sum(list, x -> (int)x > 5);
通过 Lambda 表达式,使用一个函数就搞定一切。
在上面的示例中,多个重复代码片段的唯一异同点,就是对元素的判断行为不同。而 Lambda 表达式,就可以把不同的判断行为当做参数传入 sum() 方法中,达到复用的目的。
c) 原因 3:流的并行化操作
新引入的 Stream 流操作,可以串行,也可以并行:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
// 串行
Integer reduce = list.stream().reduce((a, b) -> a + b).get();
// 并行,相比串行多了 parallel() 函数
Integer reduce = list.stream().parallel().reduce((a, b) -> a + b).get();
小结
关于 Lambda 表达式的基本使用,本篇就先介绍到这里。但仅仅掌握这些是不足以应付面试的!
在下篇中,我们将会围绕以下几点内容展示:
- Lambda 表达式和匿名内部类的区别?
- 变量作用域
- Java 中的闭包是什么?
- 常用的 Consumer、Supplier 等函数式接口怎么用?
我的公众号文章推荐:
- HashMap 面试题,看这一篇就够了!
- Linux 常用命令用法汇总
- 你了解 Referer 吗?
- ShadowSocks 的原理和使用
- 想定制化你的电脑开机吗?
更多技术文章,欢迎关注我的微信公众号:码不停蹄的小鼠松(微信号:busy_squirrel),也可扫下方二维码关注获取最新文章哦~