《netty实战》读书笔记一---selector、reactor模型、NIO与零拷贝
首先先自己熟悉一下selector、epoll、NIO编程、reactor模型
I/O 模型基本说明 I/O 模型简单的理解:就是用什么样的通道进行数据的发送和接收,很大程度上决定了程序通信的性能
Java共支持3种网络编程模型/IO模式:BIO、NIO、AIO
- Java BIO : 同步并阻塞(传统阻塞型),服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序简单易理解。 - Java NIO : 同步非阻塞,服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求就进行处理
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,弹幕系统,服务器间通讯等。编程比较复杂,JDK1.4开始支持。 - Java AIO(NIO.2) : 异步非阻塞,AIO 引入异步通道的概念,采用了 Proactor 模式,简化了程序编写,有效的请求才启动线程,它的特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用
AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。 -
HTTP2.0使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级。
Selector

Channel注册到Selector,Selector能够检测到Channel是否有事件发生。
如果有事件发生,则进行相应的处理。这样可以实现一个线程管理多个Channel(即多个连接和请求)只有通道真正有读写事件发生时,才会进行读写。
减少了创建的线程数,降低了系统开销,减少了上下文的切换,用户态和系统态的切换
以ServerSocketChannel为例说明:
- 当有客户端连接时,ServerSocketChannel会返回一个SocketChannel
- SocketChannel注册到Selector。(register方法)
- register方法会返回一个SelectionKey,SelectionKey与Channel关联
- Selector监听select方法,返回有事件的个数
- 进一步得到SelectionKey
- 通过SelectionKey获取SocketChannel(SelectionKey中的channel方法)
- 通过获取的channel,执行业务处理
reactor模型
IO复用解释:I/O复用就是单个线程通过记录跟踪每一个Sock(I/O流)的状态来同时管理多个I/O流.
这个作者我感觉讲的很好,最起码是他自己的理解:IO复用
线程模型基本介绍:
传统阻塞 I/O 服务模型
- 采用阻塞IO模式获取输入的数据
- 每个连接都需要独立的线程完成数据的输入,业务处理, 数据返回
- 当并发数很大,就会创建大量的线程,占用很大系统资源
- 连接创建后,如果当前线程暂时没有数据可读,该线程 会阻塞在read 操作,造成线程资源浪费
Reactor 模式中 核心组成:
- Reactor:Reactor 在一个单独的线程中运行,负责监听和分发事件,分发给适当的处理程序来对 IO 事件做出反应。 它就像公司的电话接线员,它接听来自客户的电话并将线路转移到适当的联系人;
- Handlers:处理程序执行 I/O 事件要完成的实际事件,类似于客户想要与之交谈的公司中的实际官员。Reactor 通过调度适当的处理程序来响应 I/O 事件,处理程序执行非阻塞操作。
Reactor 模式
- 单 Reactor 单线程
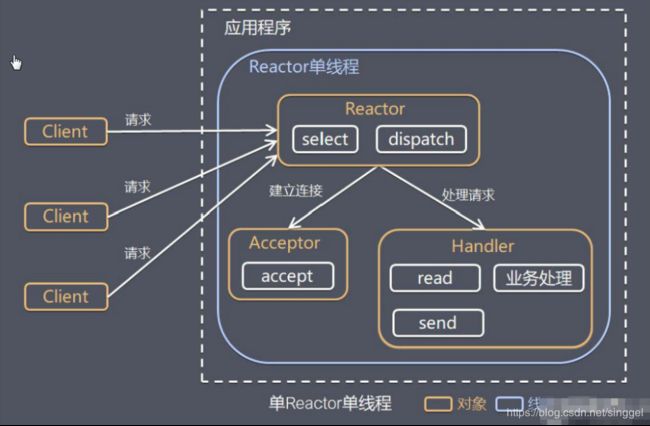
Select 是前面 I/O 复用模型介绍的标准网络编程 API,可以实现应用程序通过一个阻塞对象监听多路连接请求
Reactor 对象通过 Select 监控客户端请求事件,收到事件后通过 Dispatch 进行分发
果是建立连接请求事件,则由 Acceptor 通过 Accept 处理连接请求,然后创建一个 Handler 对象处理连接完成后的后续业务处理
如果不是建立连接事件,则 Reactor 会分发调用连接对应的 Handler 来响应
Handler 会完成 Read→业务处理→Send 的完整业务流程
优点:模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成
缺点:性能问题,只有一个线程,无法完全发挥多核 CPU 的性能。Handler 在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈
缺点:可靠性问题,线程意外终止,或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障
使用场景:客户端的数量有限,业务处理非常快速,比如 Redis在业务处理的时间复杂度 O(1) 的情况
- 单 Reactor 多线程
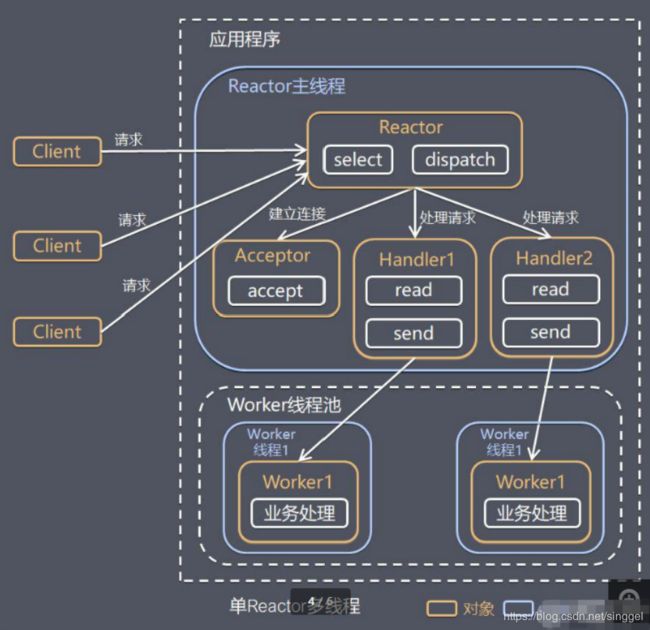
Reactor 对象通过select 监控客户端请求 事件, 收到事件后,通过dispatch进行分发
如果建立连接请求, 则右Acceptor 通过 accept 处理连接请求, 然后创建一个Handler对象处理完成连接后的各种事件
如果不是连接请求,则由reactor分发调用连接对应的handler 来处理
handler 只负责响应事件,不做具体的业务处理, 通过read 读取数据后,会分发给后面的worker线程池的某个线程处理业务
worker 线程池会分配独立线程完成真正的业务,并将结果返回给handler
handler收到响应后,通过send 将结果返回给client
优点:可以充分的利用多核cpu 的处理能力
缺点:多线程数据共享和访问比较复杂, reactor 处理所有的事件的监听和响应,在单线程运行, 在高并发场景容易出现性能瓶颈.
- 主从 Reactor 多线程
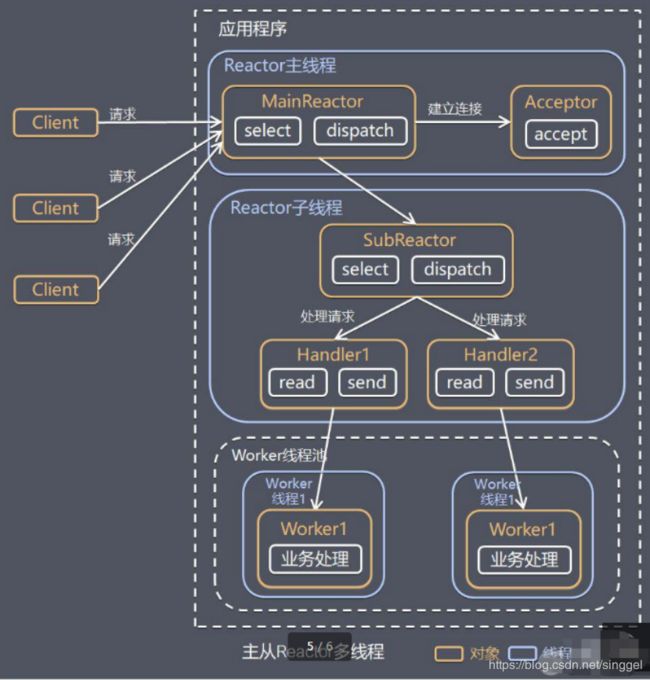
Reactor主线程 MainReactor 对象通过select 监听连接事件, 收到事件后,通过Acceptor 处理连接事件
当 Acceptor 处理连接事件后,MainReactor 将连接分配给SubReactor
subreactor 将连接加入到连接队列进行监听,并创建handler进行各种事件处理
当有新事件发生时, subreactor 就会调用对应的handler处理
handler 通过read 读取数据,分发给后面的worker 线程处理
worker 线程池分配独立的worker 线程进行业务处理,并返回结果
handler 收到响应的结果后,再通过send 将结果返回给client
Reactor 主线程可以对应多个Reactor 子线程, 即MainRecator 可以关联多个SubReactor

优点:父线程与子线程的数据交互简单职责明确,父线程只需要接收新连接,子线程完成后续的业务处理。
优点:父线程与子线程的数据交互简单,Reactor 主线程只需要把新连接传给子线程,子线程无需返回数据。
缺点:编程复杂度较高
这种模型在许多项目中广泛使用,包括 Nginx 主从 Reactor 多进程模型,Memcached 主从多线程,Netty 主从多线程模型的支持
Netty 线程模式(Netty 主要基于主从 Reactor 多线程模型做了一定的改进,其中主从 Reactor 多线程模型有多个 Reactor)

- 基于 I/O 复用模型:多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象等待,无需阻塞等待所有连接。当某个连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理
- 基于线程池复用线程资源:不必再为每个连接创建线程,将连接完成后的业务处理任务分配给线程进行处理,一个线程可以处理多个连接的业务。
- I/O 复用结合线程池,就是 Reactor 模式基本设计思想
- Reactor 模式,通过一个或多个输入同时传递给服务处理器的模式(基于事件驱动)
- 服务器端程序处理传入的多个请求,并将它们同步分派到相应的处理线程, 因此Reactor模式也叫 Dispatcher模式
- Reactor 模式使用IO复用监听事件, 收到事件后,分发给某个线程(进程), 这点就是网络服务器高并发处理关键
响应快,不必为单个同步时间所阻塞,虽然 Reactor 本身依然是同步的
可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程/进程的切换开销
扩展性好,可以方便的通过增加 Reactor 实例个数来充分利用 CPU 资源
复用性好,Reactor 模型本身与具体事件处理逻辑无关,具有很高的复用性
NIO与零拷贝:
传统IO:

mmap优化:
mmap 通过内存映射,将文件映射到内核缓冲区,同时,用户空间可以共享内核空间的数据。这样,在进行网络传输时,就可以减少内核空间到用户控件的拷贝次数。如下图
sendFile优化:
Linux 2.1 版本 提供了 sendFile 函数,其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 Socket Buffer,同时,由于和用户态完全无关,就减少了一次上下文切换

提示:零拷贝从操作系统角度,是没有cpu 拷贝
Linux 在 2.4 版本中,做了一些修改,避免了从内核缓冲区拷贝到 Socket buffer 的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝。具体如下图和小结: 这里其实有 一次cpu 拷贝 kernel buffer -> socket buffer 但是,拷贝的信息很少,比如 lenght , offset , 消耗低,可以忽略
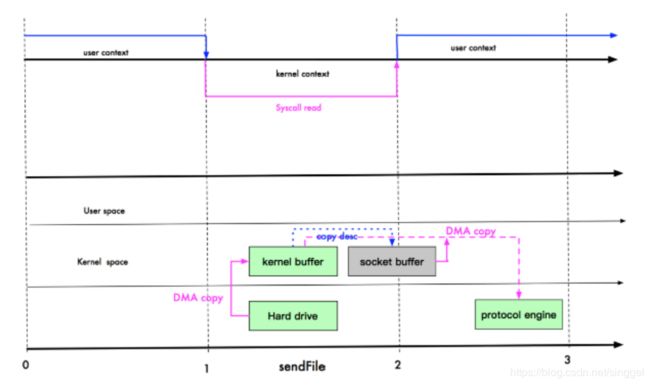
我们说零拷贝,是从操作系统的角度来说的。因为内核缓冲区之间,没有数据是重复的(只有 kernel buffer 有一份数据)。 零拷贝不仅仅带来更少的数据复制,还能带来其他的性能优势,例如更少的上下文切换,更少的 CPU 缓存伪共享以及无 CPU 校验和计算。
mmap 和 sendFile 的区别
1.mmap 适合小数据量读写,sendFile 适合大文件传输。
2.mmap 需要 4 次上下文切换,3 次数据拷贝;sendFile 需要 3 次上下文切换,最少 2 次数据拷贝。
3.sendFile 可以利用 DMA 方式,减少 CPU 拷贝,mmap 则不能(必须从内核拷贝到 Socket 缓冲区)。