哈夫曼树
1、问题描述
哈夫曼编码是广泛地用于数据文件压缩的十分有效的编码方法。其压缩率通常在20%~90%之间。哈夫曼编码算法用字符在文件中出现的频率表来建立一个用0,1串表示各字符的最优表示方式。一个包含100,000个字符的文件,各字符出现频率不同,如下表所示。
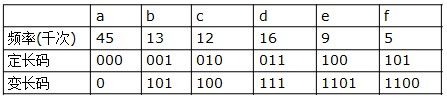
有多种方式表示文件中的信息,若用0,1码表示字符的方法,即每个字符用唯一的一个0,1串表示。若采用定长编码表示,则需要3位表示一个字符,整个文件编码需要300,000位;若采用变长编码表示,给频率高的字符较短的编码;频率低的字符较长的编码,达到整体编码减少的目的,则整个文件编码需要(45×1+13×3+12×3+16×3+9×4+5×4)×1000=224,000位,由此可见,变长码比定长码方案好,总码长减小约25%。
前缀码:对每一个字符规定一个0,1串作为其代码,并要求任一字符的代码都不是其他字符代码的前缀。这种编码称为前缀码。编码的前缀性质可以使译码方法非常简单;例如001011101可以唯一的分解为0,0,101,1101,因而其译码为aabe。
译码过程需要方便的取出编码的前缀,因此需要表示前缀码的合适的数据结构。为此,可以用二叉树作为前缀码的数据结构:树叶表示给定字符;从树根到树叶的路径当作该字符的前缀码;代码中每一位的0或1分别作为指示某节点到左儿子或右儿子的“路标”。
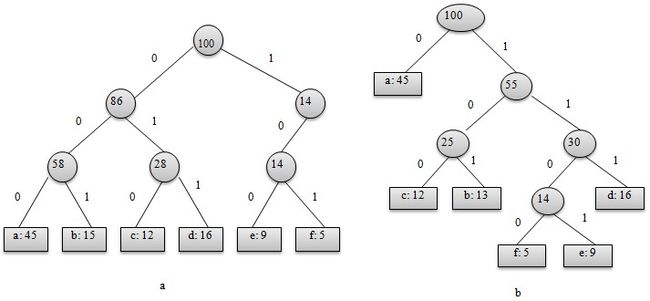
从上图可以看出,表示最优前缀码的二叉树总是一棵完全二叉树,即树中任意节点都有2个儿子。图a表示定长编码方案不是最优的,其编码的二叉树不是一棵完全二叉树。在一般情况下,若C是编码字符集,表示其最优前缀码的二叉树中恰有|C|个叶子。每个叶子对应于字符集中的一个字符,该二叉树有|C|-1个内部节点。
给定编码字符集C及频率分布f,即C中任一字符c以频率f(c)在数据文件中出现。C的一个前缀码编码方案对应于一棵二叉树T。字符c在树T中的深度记为dT(c)。dT(c)也是字符c的前缀码长。则平均码长定义为: 使平均码长达到最小的前缀码编码方案称为C的最优前缀码。
使平均码长达到最小的前缀码编码方案称为C的最优前缀码。
2、构造哈弗曼编码
哈夫曼提出构造最优前缀码的贪心算法,由此产生的编码方案称为哈夫曼编码。其构造步骤如下:
(1)哈夫曼算法以自底向上的方式构造表示最优前缀码的二叉树T。
(2)算法以|C|个叶结点开始,执行|C|-1次的“合并”运算后产生最终所要求的树T。
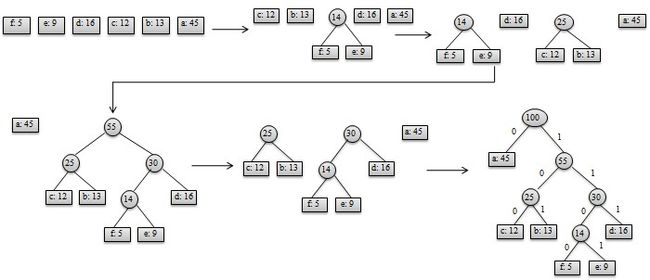
(3)假设编码字符集中每一字符c的频率是f(c)。以f为键值的优先队列Q用在贪心选择时有效地确定算法当前要合并的2棵具有最小频率的树。一旦2棵具有最小频率的树合并后,产生一棵新的树,其频率为合并的2棵树的频率之和,并将新树插入优先队列Q。经过n-1次的合并后,优先队列中只剩下一棵树,即所要求的树T。
构造过程如图所示:
代码
//原作者 https://blog.csdn.net/jinixin/article/details/52142352
#include
#include
#include
#include
using namespace std;
typedef struct node{
char ch; //存储该节点表示的字符,只有叶子节点用的到
int val; //记录该节点的权值
struct node *self,*left,*right; //三个指针,分别用于记录自己的地址,左孩子的地址和右孩子的地址
friend bool operator <(const node &a,const node &b) //运算符重载,定义优先队列的比较结构
{
return a.val>b.val; //这里是权值小的优先出队列
}
}node;
priority_queue p; //定义优先队列
char res[30]; //用于记录哈夫曼编码
void dfs(node *root,int level) //打印字符和对应的哈夫曼编码
{
if(root->left==root->right) //叶子节点的左孩子地址一定等于右孩子地址,且一定都为NULL;叶子节点记录有字符
{
if(level==0) //“AAAAA”这种只有一字符的情况
{
res[0]='0';
level++;
}
res[level]='\0'; //字符数组以'\0'结束
printf("%c=>%s\n",root->ch,res);
}
else
{
res[level]='0'; //左分支为0
dfs(root->left,level+1);
res[level]='1'; //右分支为1
dfs(root->right,level+1);
}
}
void huffman(int *hash) //构建哈夫曼树
{
node *root,fir,sec;
for(int i=0;i<26;i++) //程序只能处理全为大写英文字符的信息串,故哈希也只有26个
{
if(!hash[i]) //对应字母在text中未出现
continue;
root=(node *)malloc(sizeof(node)); //开辟节点
root->self=root; //记录自己的地址,方便父节点连接自己
root->left=root->right=NULL; //该节点是叶子节点,左右孩子地址均为NULL
root->ch='A'+i; //记录该节点表示的字符
root->val=hash[i]; //记录该字符的权值
p.push(*root); //将该节点压入优先队列
}
//下面循环模拟建树过程,每次取出两个最小的节点合并后重新压入队列
//当队列中剩余节点数量为1时,哈夫曼树构建完成
while(p.size()>1)
{
fir=p.top();p.pop(); //取出最小的节点
sec=p.top();p.pop(); //取出次小的节点
root=(node *)malloc(sizeof(node)); //构建新节点,将其作为fir,sec的父节点
root->self=root; //记录自己的地址,方便该节点的父节点连接
root->left=fir.self; //记录左孩子节点地址
root->right=sec.self; //记录右孩子节点地址
root->val=fir.val+sec.val;//该节点权值为两孩子权值之和
p.push(*root); //将新节点压入队列
}
fir=p.top();p.pop(); //弹出哈夫曼树的根节点
dfs(fir.self,0); //输出叶子节点记录的字符和对应的哈夫曼编码
}
int main()
{
char text[100];
int hash[30];
memset(hash,0,sizeof(hash)); //哈希数组初始化全为0
scanf("%s",text); //读入信息串text
for(int i=0;text[i]!='\0';i++)//通过哈希求每个字符的出现次数
{
hash[text[i]-'A']++; //程序假设运行的全为英文大写字母
}
huffman(hash);
return 0;
}
例题
荷马史诗
题目描述
追逐影子的人,自己就是影子 ——荷马
Allison 最近迷上了文学。她喜欢在一个慵懒的午后,细细地品上一杯卡布奇诺,静静地阅读她爱不释手的《荷马史诗》。但是由《奥德赛》和《伊利亚特》 组成的鸿篇巨制《荷马史诗》实在是太长了,Allison 想通过一种编码方式使得它变得短一些。
一部《荷马史诗》中有n种不同的单词,从1到n进行编号。其中第i种单 词出现的总次数为wi。Allison 想要用k进制串si来替换第i种单词,使得其满足如下要求:
对于任意的 1 ≤ i, j ≤ n , i ≠ j ,都有:si不是sj的前缀。
现在 Allison 想要知道,如何选择si,才能使替换以后得到的新的《荷马史诗》长度最小。在确保总长度最小的情况下,Allison 还想知道最长的si的最短长度是多少?
一个字符串被称为k进制字符串,当且仅当它的每个字符是 0 到 k − 1 之间(包括 0 和 k − 1 )的整数。
字符串 str1 被称为字符串 str2 的前缀,当且仅当:存在 1 ≤ t ≤ m ,使得str1 = str2[1..t]。其中,m是字符串str2的长度,str2[1..t] 表示str2的前t个字符组成的字符串。
输入输出格式
输入格式:
输入的第 1 行包含 2 个正整数 n, k ,中间用单个空格隔开,表示共有 n种单词,需要使用k进制字符串进行替换。
接下来n行,第 i + 1 行包含 1 个非负整数wi ,表示第 i 种单词的出现次数。
输出格式:
输出包括 2 行。
第 1 行输出 1 个整数,为《荷马史诗》经过重新编码以后的最短长度。
第 2 行输出 1 个整数,为保证最短总长度的情况下,最长字符串 si 的最短长度。
输入输出样例
输入样例#1:
4 2 1 1 2 2
输出样例#1:
12 2
输入样例#2:
6 3 1 1 3 3 9 9
输出样例#2:
36 3
说明
【样例说明 1】
用 X(k) 表示 X 是以 k 进制表示的字符串。
一种最优方案:令 00(2) 替换第 1 种单词, 01(2) 替换第 2 种单词, 10(2) 替换第 3 种单词,11(2) 替换第 4 种单词。在这种方案下,编码以后的最短长度为:
1 × 2 + 1 × 2 + 2 × 2 + 2 × 2 = 12
最长字符串si的长度为 2 。
一种非最优方案:令 000(2) 替换第 1 种单词,001(2) 替换第 2 种单词,01(2)替换第 3 种单词,1(2) 替换第 4 种单词。在这种方案下,编码以后的最短长度为:
1 × 3 + 1 × 3 + 2 × 2 + 2 × 1 = 12
最长字符串 si 的长度为 3 。与最优方案相比,文章的长度相同,但是最长字符串的长度更长一些。
分析
作者博客:http://www.cnblogs.com/ljh2000-jump/
考虑我们常规的二叉Huffman树就是每次取出权值最小的两个结点合并,将两个结点的权值的和作为一个新的结点继续合并,堆维护即可,当然跟合并果子的做法是一样的。值得一提的是这道题就是需要一棵k叉Huffman树,来保证合法性,同时由于我们每次取出的是权值最小的k个所以可以保证总代价最小。
Huffman树之所以可以保证合法性,是因为加入了许多虚拟结点,保证了一定不会有一个是另一个前缀的情况,考虑一个结点到根结点的路径上的所有点一定都是虚拟结点,所以很容易确定构造方法的合法。
另外,由于需要保证最大的长度最小,那么我们就在权值相等的时候按深度从小到大排序,优先合并深度小的,可以发现先合并的深度一定大于等于后合并的。
//It is made by ljh2000
#include
#include
#include
#include
#include
#include
#include
using namespace std;
typedef long long LL;
int n,k,ans2;
LL ans;
struct node{
LL val;
int deep;
inline bool operator < (const node &a) const {
if(a.val==val) return a.deepQ;
inline LL getint(){
LL w=0,q=0; char c=getchar(); while((c<'0'||c>'9') && c!='-') c=getchar();
if(c=='-') q=1,c=getchar(); while (c>='0'&&c<='9') w=w*10+c-'0',c=getchar(); return q?-w:w;
}
inline void work(){
scanf("%d%d",&n,&k); LL x;
for(int i=1;i<=n;i++) { x=getint(); Q.push((node){x,1}); }
int remain=(n-1)%(k-1);
if(remain!=0) { remain=k-1-remain; n+=remain; }
for(int i=1;i<=remain;i++) Q.push((node){0,1});
while(n>1) {
int maxd=0; LL tot=0;
for(int i=1;i<=k;i++) {
tmp=Q.top(); Q.pop();
tot+=tmp.val;//只需加一次即可,因为以后每层都要加一次
maxd=max(maxd,tmp.deep);//最大深度,作为排序的依据
}
Q.push((node){tot,maxd+1});
ans+=tot;
ans2=max(ans2,maxd);
n-=k-1;
}
printf("%lld\n",ans);
printf("%d",ans2);
}
int main()
{
work();
return 0;
}