Yann Lecun最新演讲:机器怎样进行有效学习?

作者:岑大师
来源:AI科技评论
本文长度为3200字,建议阅读7分钟
本文为你分享Yann Lecun关于利用对抗网络进行无监督学习的研究。
本文为Yann Lecun在CoRL 2017大会上做的演讲的概述,所有资料来自于官方公开资源整理。
回顾Yann Lecun清华演讲精华内容:
深扒Yann LeCun清华演讲中提到的深度学习与人工智能技术(PPT+视频)
Lecun为Facebook AI研究院院长,他同时也是纽约大学的终身教授。他因著名的卷积神经网络(CNN)相关的工作而被人称为CNN之父。在演讲中,Lecun回顾了其早期利用神经网络用于机器人的研究做了一个基本的介绍,重点讲解了他的成名作——卷积神经网络(CNN),并分析了阻碍人工智能继续前进的因素。
在他看来,现在的人工智能系统距离真正的人工智能相去甚远,要想让机器像人或动物一样有效学习,需要更好地就无监督学习上继续研究,并讨论了利用对抗网络进行无监督学习的重要性。

Lecun的演讲标题是:《机器该如何像动物和人类一样有效学习》?

Lecun先从今年9月的CCN(Cognitive Computational Neuroscience,认知计算神经科学)大会上,MIT的认知计算专家Josh Tennenbaum的一句话说起:我们现在看到的所有AI系统都不是真正的AI。这是因为,大脑的学习效率比我们目前所有的机器学习方法效率都要高:监督学习需要大量的范例,增强学习需要上百万次试错,这也是我们的机器人无法像猫或老鼠一样灵活、以及无法造出拥有常识的对话系统的原因。

我们可以通过强化学习训练机器识别如桌子、凳子、够、汽车、飞机等实例,只要我们有足够的计算能力和训练样本,机器业能识别出之前未见过的东西。
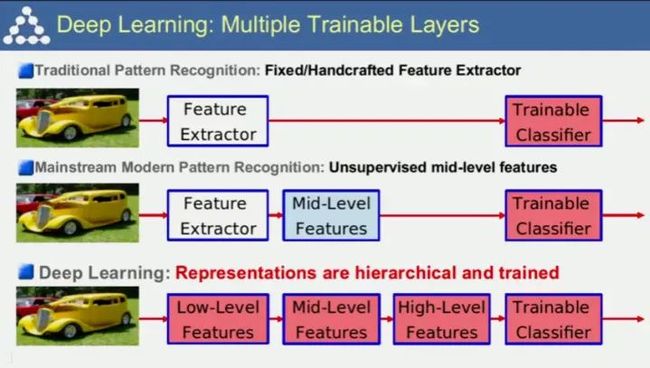
Lecun还比较了传统的模式识别方法、改进的模式识别方法、深度学习的不同。
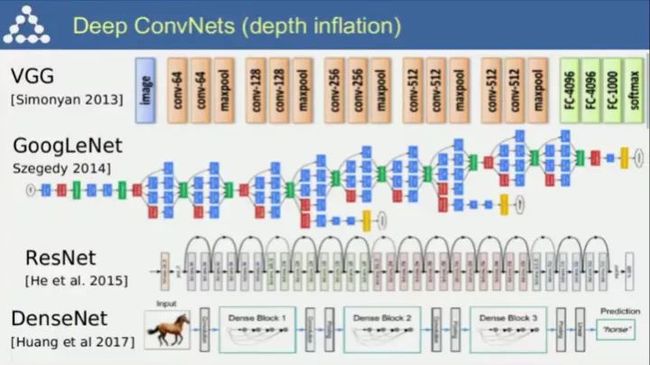
从2013年到2017年,从VGG到DenseNet(这也是Facebook用于图像识别的网络结构),深度卷积神经网络变得越来越深,识别效果也变得越来越好。
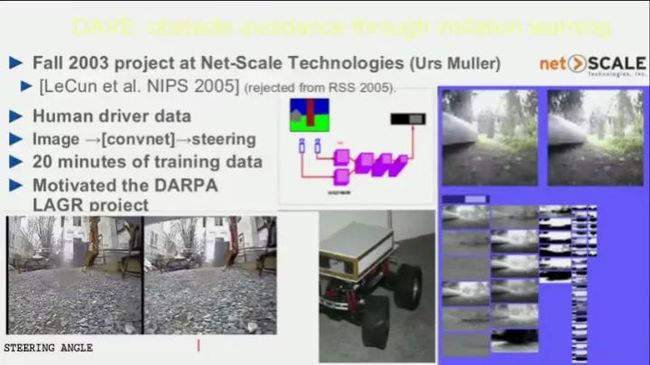
而在Lecun将机器学习应用于机器人的研究在2003年,当时DARPA找到Lecun,通过模仿学习进行避障的研究。2005年,Lecun将论文投给了第一届RSS(机器人领域的顶级学术会议之一),但很不幸的被拒了,随后Lecun将论文转投当年的NIPS,论文被收录发表。而这一研究的阶段性成果也打动了DARPA,并催生了之后的DARPA LAGR项目(这么说来,Lecun在机器人方面的研究天赋是不是被RSS耽误了呢)。

DARPA LAGR:一个将机器学习应用于地面机器人、基于感知的自主导航项目。

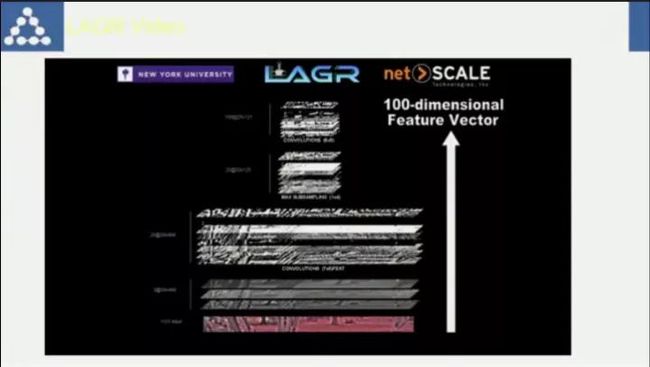
Lecun在机器人上使用了一个叫ComNet的网络,在当时算是非常前卫的做法。

当时的识别效果,在地图上设定终点后可自主进行路线规划。
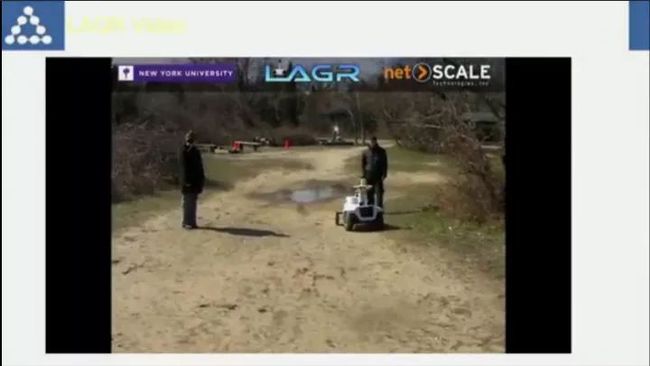
然而,每秒只能进行一帧图像的识别,无法有效躲避突然出现的行人。

若干年后的另一个研究,将视频中的场景识别为不同种类,如道路、汽车、建筑等。当时还缺乏对应的数据集,需要进行大量的标注。由于缺乏数据,这并不是卷积神经网络的强项,只是相比其他方法来说算是一个不错的选择而已(直到2012年ImageNet上的突破)。

2012年在FPGA上跑到20帧,这也推动了之后如Mobileye和NVIDIA在无人驾驶上的研究。
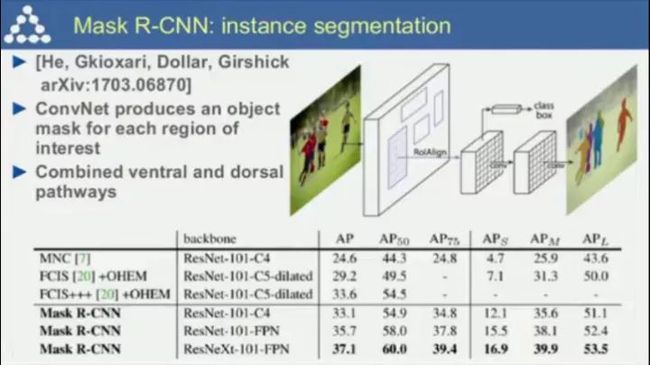
其他的应用,如将Mask R-CNN用于实例分割;
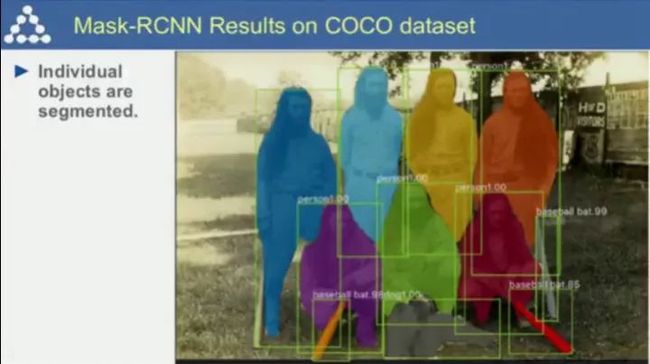
Mask R-CNN在COCO数据集上的图像分割结果。

以及姿态预估的结果;

3D语义识别;

用于翻译;
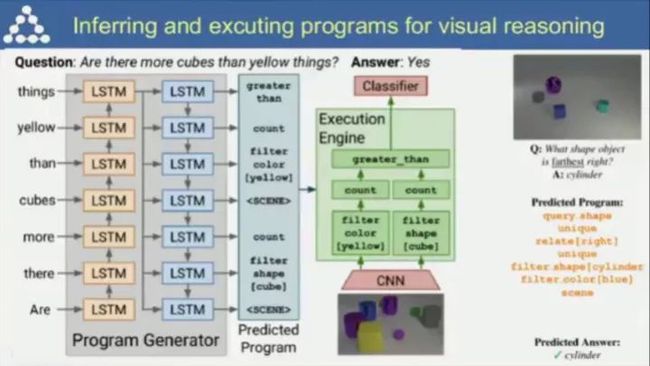
视觉推理中的推断和执行(虽然Lecun怼过Jurgen,但不得不说LSTM还是很有用的嘛);

诸多的用促成了FAIR的诸多开源项目(Lecun说,这里大多数项目自己没有参与,他只是在说别人的研究工作);

展望未来,Lecun认为阻碍人工智能继续前进的因素在于目前我们打开AI的方式不正确,像人或动物都无需大量的标识数据或者大量试错;

这当中的差别在于“常识”,就是通过想象来填补空白的能力,这也是某种形式的非监督学习。

大多数人或动物的学习方式都是非监督学习。

人类具有通过观察形成常识的能力,例如“Josh拿起包离开了房间”,我们人类很容易理解相应的行为,但很难教机器去理解这一系列动作;

从认知科学的角度,人类在婴儿时期学习到各种概念的时间表;

为什么下需要进一步发展非监督学习?这是由于用于训练一个大的学习机器的必要样本量取决于我们要求它能预测多少信息,你对机器要求越多,所需要的数据也越多。在人类大脑中有10^14个神经元触突,而人的一生大概有10^9秒,这意味着在人类大脑这个系统中参数远远大于数据量,而机器想要赶上人类,必须模仿人类的非监督学习方式。

三种不同学习方式的比较。

然后Lecun展示了他著名的“蛋糕”理论。“真正的”强化学习好比蛋糕上的樱桃,监督学习好比蛋糕上的糖衣,而蛋糕本身是非监督学习(预测学习)。这里Lecun也表示,这一比喻对做强化学习的兄弟可能不太友好——“Because the cherry is not optional”。


在Lecun看来,真正的强化学习是很难在现实世界中应用的,一不小心出错就会酿成大祸,还是玩玩游戏就好了。

比如说,打星际。
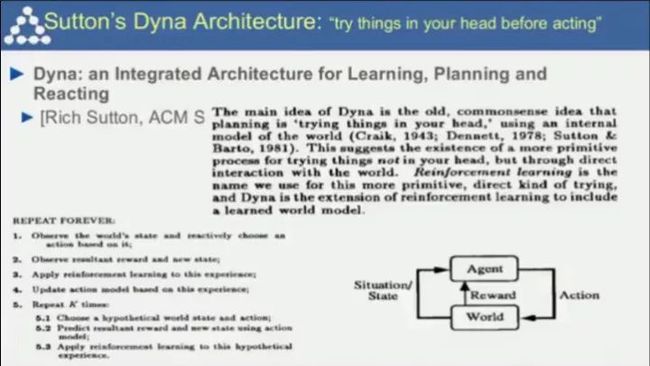
经典的强化学习框架Dyna:“现在大脑中推演然后再行动”;
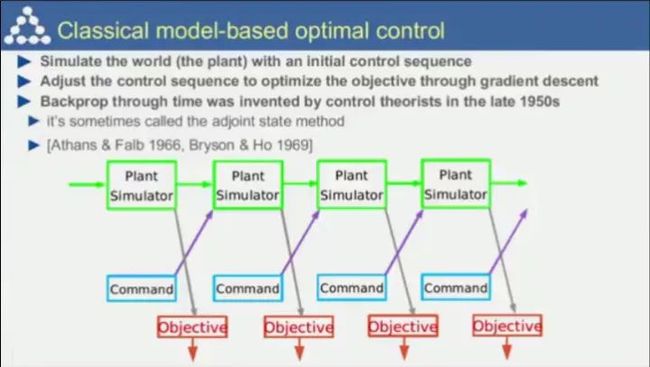
以及经典的基于模型的最优控制理论。

Lecun进行了概况:未来的AI革命必然是非监督学习。
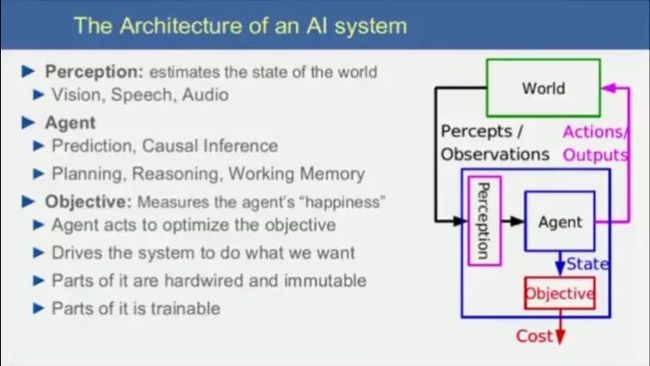
人工智能系统的两个重要组成部分:一个会学习的Agent和一个不变的目标函数。Agent从世界中感知,做实际决策,再感知,再做决策………通过这样一个不断循环迭代的过程,达到长期的期望损失最小化的目标。
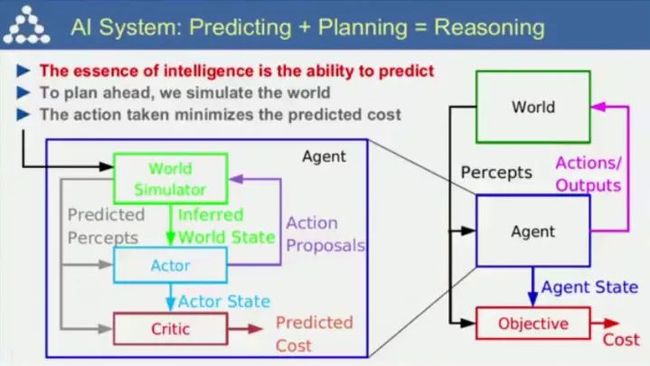
预测+规划=推理,而通过最小化预测损耗,可以使Agent进一步优化决策过程。
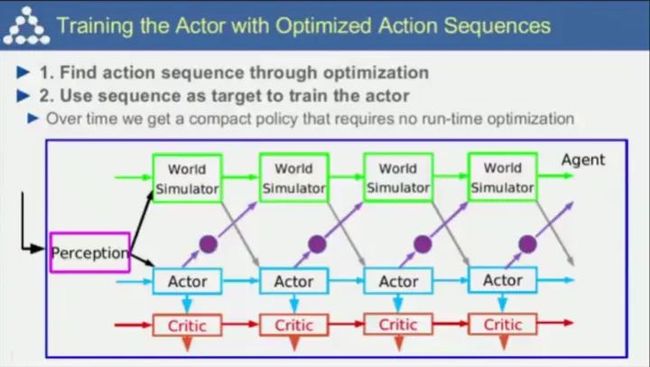
对应的迭代式的学习方式和优化如上图所示。这种非监督学习方式也是人类诸如学开车等技能获得的重要方式,因为人们会推演行为带来的后果,并不断调整达到最优。
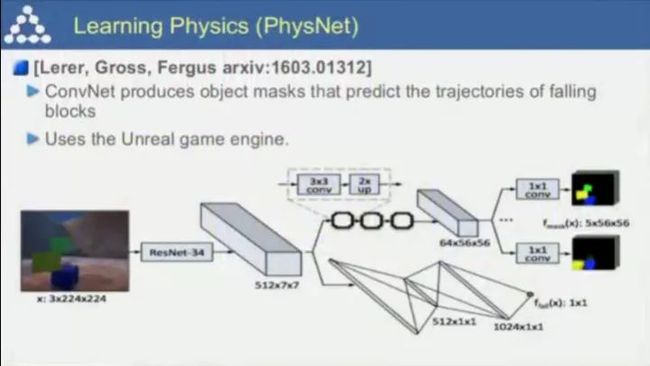
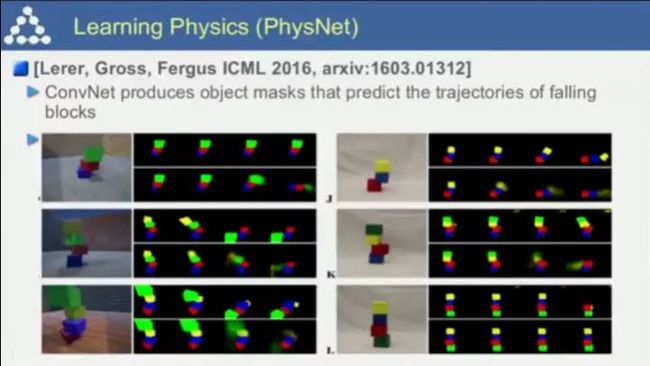
基于卷积网络的PhysNet,可预测物体的掉落轨迹;

Lecun的学生不久前做的另一个前向模型,可模拟飞船在星际旅行中的运动规划。

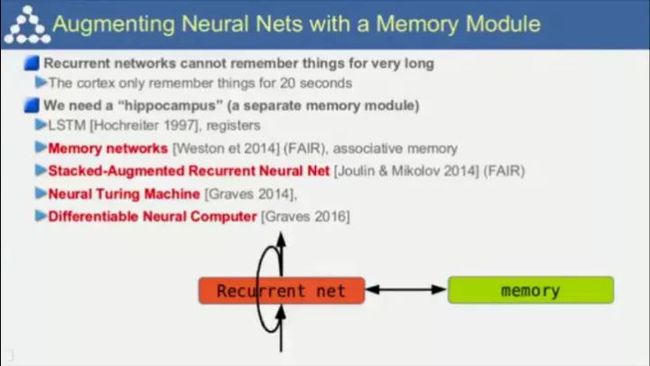
关于问答与对话系统中的预测模型。Lecun称要预测未来,你首先要记住过去,因而需要将记忆引入神经网络中,即所谓的记忆网络(Memory Network)。
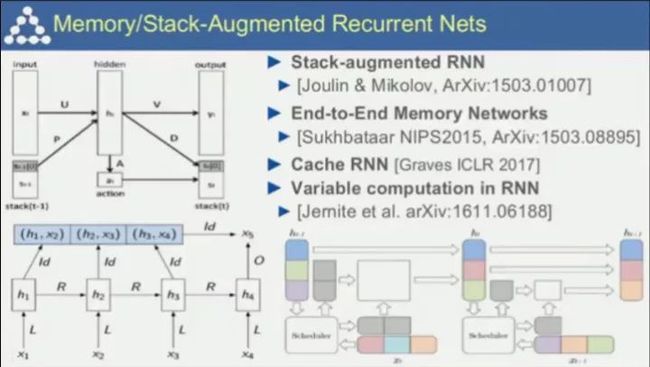
以及关于记忆网络的若干模型。
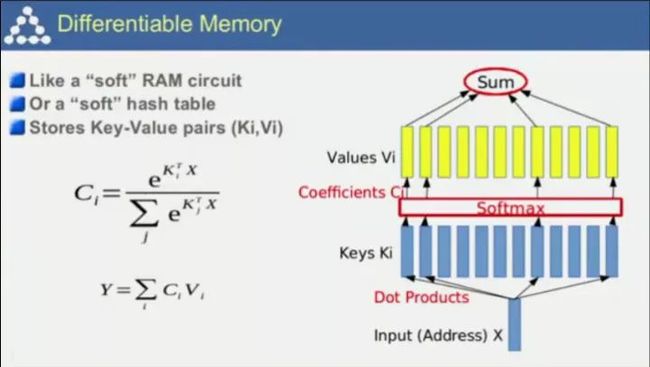
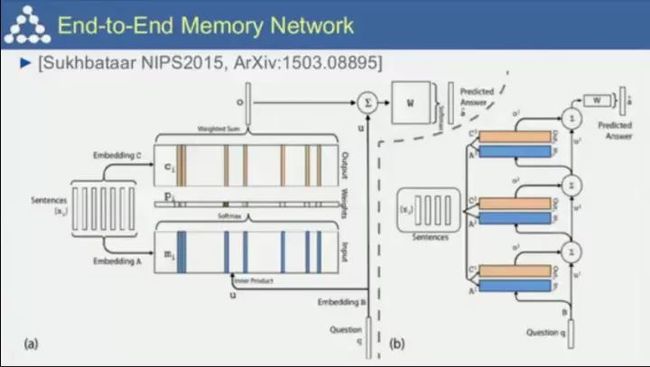
端到端的记忆网络。你之前告诉机器的东西会被储存起来,并在之后询问提及时被激活,这一方式可以用于构建对话系统,而且对话系统和机器人与世界进行交互的过程有着诸多相似之处;
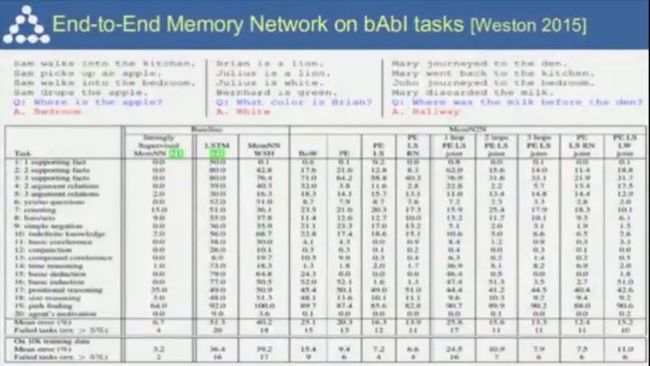

如果要设计一个好的对话系统,需要对对话有良好的预测能力。

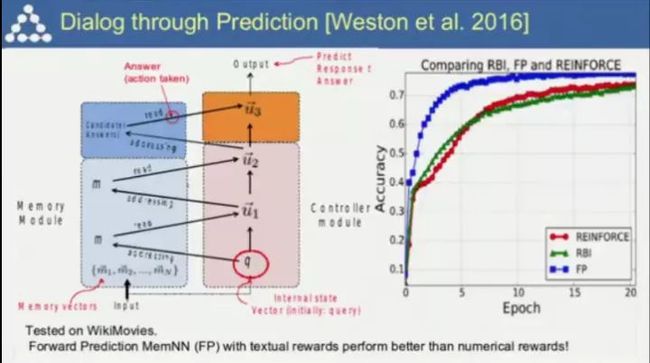
在这方面的一些研究。

然后Lecun提到了在非确定条件下的预测方式(非监督学习)。

简单来说就是学习一个能量函数,使得其在数据流形状上具有较低的值,而在其他地方具有较高的值。
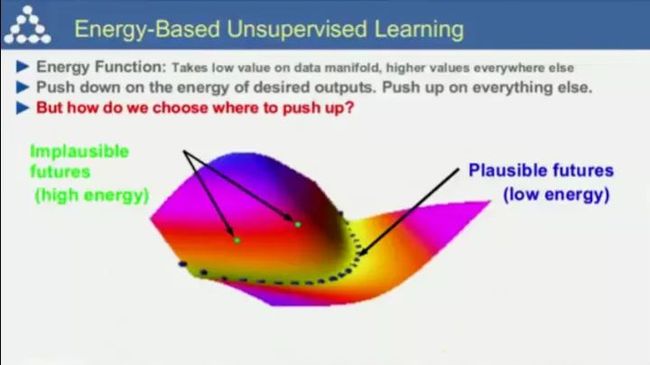
即在希望的输出上压低能量值,在其他地方提高能量值。但是我们如何确定什么地方应该提高呢?这当有八、九种方法,比如蒙特卡洛方法等。

而对抗网络也是新的处理这一问题的有效手段。

到具体的问题,最困难之处在于基于不确定性的预测。例如放开一支笔,让系统回答笔半秒钟后会导向何方,系统感知到的输入X只是世界里真实分布的一个采样,假设其由某个隐变量Z而决定,如果Z不同,预测的结果Y也会不一样,即便是我们人类也很难预测Y在空间中的带状分布。
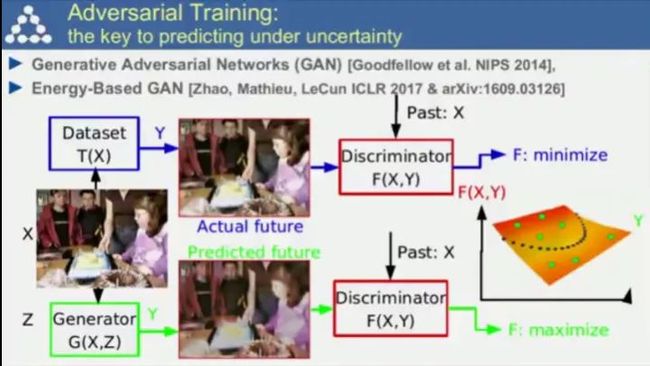
对抗学习:由生成器来决定让哪些点的能量值变高或者变低;


基于能量的生成对抗网络在ImageNet上训练的例子。

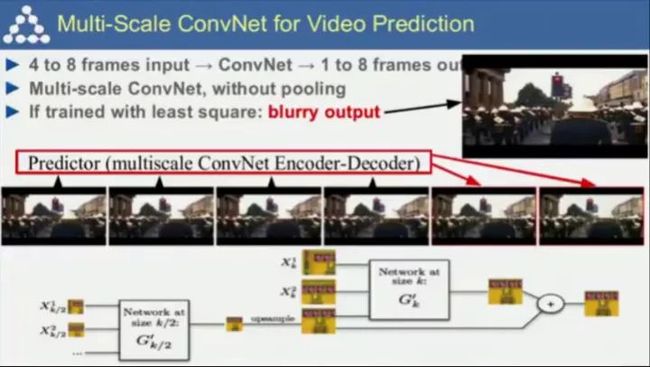
我们同样还可以将生成对抗网络应用在视频预测上。

我们是否可以训练机器像我们大脑一样,对未来进行预测呢?通过生成对抗网络,我们已经取得了一些进展,但这个问题仍然远远未能解决。


用生成对抗网络预测未来5帧的例子总体来说不错,但如果我们预测未来50帧的状态就要大打折扣了。

Lecun最近的研究:视频预测的语义分割

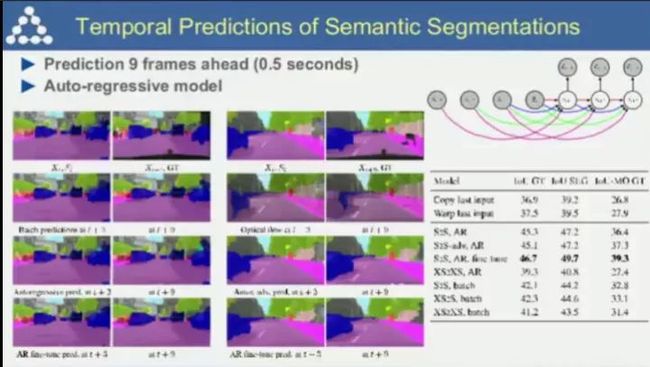
该研究在如自动驾驶等领域将会有不错的应用,例如预测0.5秒后行人或其他车辆的状态;

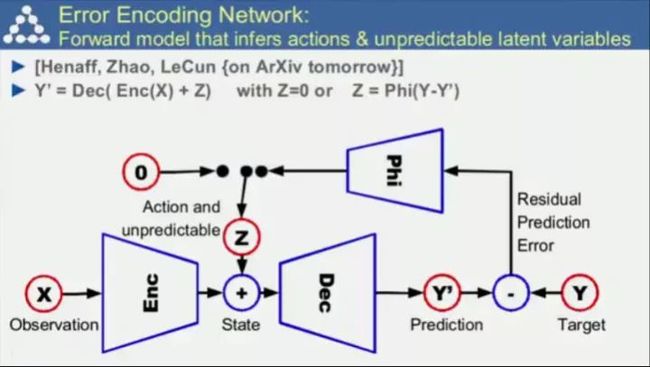
Lecun最新的研究:错误编码网络(即将发布到Arxiv上)

在一个测试集上的例子:用机器手臂戳物体并预测其位置。
Lecun称,对未来的预测是AI系统的一个重要环节,而这一问题尚未得到解决。生成对抗网络为解决这一问题提供了一个思路,同时他也期待有其他更好的方法来解决这一问题。
