【分布式编程】一——基于VirtualBox的Hadoop完全分布式环境搭建
系统架构
虚拟机环境:VirtualBox
Linux系统:Ubuntu 16.04 LTS
工具包
- JDK1.8
- Hadoop 2.7.5
拓扑结构:如下
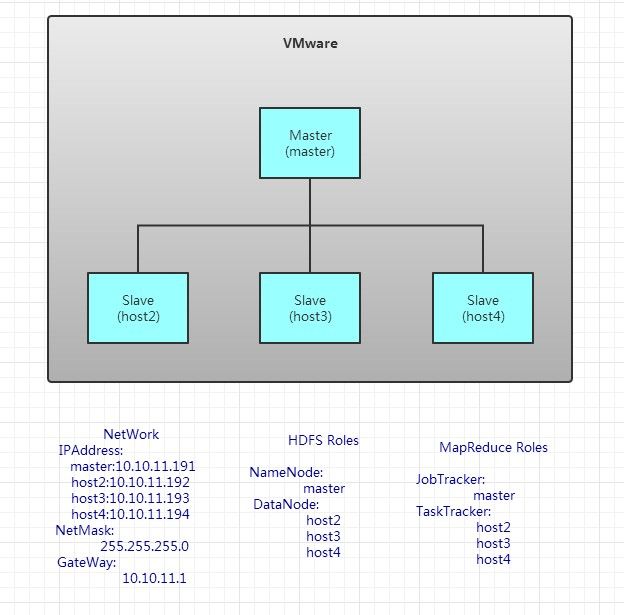
操作步骤
【注】本步骤以Master为例,其他虚拟机可以使用克隆功能复制,然后更改
安装常用软件
安装vim
sudo apt-get install vim安装工具包
设置共享文件夹
- 安装
VirtualBox增强功能包,Ubuntu系统直接点击设备->安装增强功能 - 剩余步骤看教程
安装JDK
- 下载JDK-8u151
- 剩余步骤看教程
创建用户组
创建用户组
每个主机都需要加入到同一用户组。此处创建名为hadoop用户组
sudo addgroup hadoop查看当前用户
who当前用户为t
添加当前用户到用户组
sudo adduser t hadoop #sudo adduser user group查看归属用户组
groups t #group user安装Hadoop
下载Hadoop
点击链接下载
解压Hadoop
将文件复制到/Downloads/文件夹下进行解压
cd Downloads/
tar -zxvf hadoop-2.7.5.tar.gz将解压后的文件夹移动到/usr/文件夹
sudo mv hadoop-2.7.5/ /usr/配置文件
需要配置的文件都在解压后的hadoop-2.7.5即usr/hadoop-2.7.5/文件夹中的/etc/hadoop/文件夹中
配置hadoop-env.sh
cd /usr/hadoop-2.7.5/etc/hadoop/
sudo vim hadoop-env.sh添加java安装路径
配置core-site.xml
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://master:9000value>
<final>truefinal>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/t/hadoop/tmpvalue>
<description>A base for other temporary directories.description>
property>
configuration> 【说明】
<name>fs.default.namename>此参数设置NameNode的URI,此处设master主机为NameNode
<name>hadoop.tmp.dirname>此参数设置Hadoop的一个临时目录,用来存放每次运行的作业jpb的信息。
此处设置/home/t/hadoop/tmp为临时目录,因没有此目录,因此需要先创建
sudo mkdir /home/t/hadoop/tmp【附】
其他部分参数,如需要更多参数,请自查
| 参数 | 默认值 | 说明 |
|---|---|---|
| fs.default.name | file:/// | NameNode的URI |
| hadoop.tmp.dir | 临时目录位置 | |
| hadoop.native.lib | true | 是否使用hadoop的本地库 |
| hadoop.http.filter.initializers | 空 | 设置Filter初始器 |
配置hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dirname>
<value>/home/t/hadoop/tmp/dfs/namevalue>
<final>truefinal>
property>
<property>
<name>dfs.data.dirname>
<value>/home/t/hadoop/tmp/dfs/datavalue>
<final>truefinal>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration> 【说明】
<name>dfs.name.dirname>dfs.name.dir存储永久性的元数据的目录列表。这个目录会创建在master主机上。
<name>dfs.data.dirname>dfs.data.dir存放数据块的目录列表,这个目录在node1和node2上创建
<name>dfs.replicationname>dfs.replication设置文件副本数,此处有两个从机,设置副本数为2
配置mapred-site.xml
先创建mapred-site.xml,进入到~/etc/hadoop/文件夹下
cp mapred-site.xml.template mapred-site.xml<configuration>
<property>
<name>mapred.job.trackername>
<value>master:9001value>
property>
configuration> 配置slaves
把其他从机的主机名添加,有几个就添加几个,多添加会无法运行
配置环境变量
sudo vim /etc/profile将环境变量添加即可
export HADOOP_HOME=/usr/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin更新生效
source /etc/profile运行是否配置环境变量成功
hadoop version【注】此步骤完成之后,可以克隆两个虚拟机分别命名为node1,node2
更改网络配置
虚拟机设置
【注】所有虚拟机都需要进行此步操作
点击控制->设置->网络,连接方式选择桥接网卡,然后重启虚拟机
修改Hostname
sudo vim /etc/hostname【注】其他虚拟机修改其Hostname为相应的名称
以master为例,直接改为
修改hosts文件
sudo vim /etc/hosts增加以下内容,所有虚拟机都要增加以下内容
10.10.11.191 master
10.10.11.192 node1
10.10.11.193 node2其中127.0.0.1 oldhostname删掉
更改IP地址、网关
【注】此处以master主机为例,其他主机根据上述拓扑图做相应更改
1.更改IP
利用ifconfig命令查看网卡名称,然后更改设置,本虚拟机网卡为enp0s3
sudo ifconfig enp0s3 10.10.11.191/24【注】此种更改IP的方法,系统重启后需要重新配置
2.更改网关
sudo route add default gw 10.10.11.1关闭防火墙
sudo ufw disable
sudo apt-get remove iptables【注】此步骤后即可利用VirtualBox克隆功能复制出其他从机
连接测试
使用ping命令测试是否能够连接
ping hostname配置SSH
安装ssh
sudo apt-get install ssh查看已安装的ssh
dpkg --list|grep ssh如果缺少openssh-server,需要安装
sudo apt-get install openssh-server配置ssh
下述步骤在不同的主机上进行,请注意区分
master机操作
生成
master机的一对公钥和私钥ssh-keygen -t rsa -P ''进入
.ssh目录查看公钥和私钥,id_rsa和id_rsa.pubcd .ssh ls将公钥加入到已认证的key中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys登录本机
ssh localhost
如果出现The authenticity of host 'localhost (127.0.0.1)' can't be established.,输入yes即可。
其他从机操作
- 将
master主机上的id_rsa.pub复制到node1从机上。同理node2进行类似操作
scp ~/.ssh/id_rsa.pub t@node1:~/然后再在从机执行
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys若遇到/home/t/.ssh/node1_rsa.pub: No such file or directory,则手动通过共享文件夹复制到其他从机相应位置。
若从机cd .ssh遇到No such file or directory,则手工创建.ssh文件夹。
- 在
/home/t图形化界面按Ctrl+H显示隐藏文件夹, - 若已经存在
.ssh文件夹,则删除suso rm -r /home/t/.ssh。这里的/home/t是用户目录,t是用户名,其他用户名则需要做相应更改。 - 若没有
.ssh文件夹,则创建sudo mkdir /home/t/.ssh - 更改权限
sudo chmod a+w /home/t/.ssh 通过共享文件夹把
master中的id_rsa.pub复制到/home/t/中- 将
master主机上的密钥加入到认证中
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys- 在
master主机上验证能否正常登陆
ssh node1- 将
出现以下则表示登陆成功
启动集群
格式化namenode
在主机master运行
hadoop namenode -format若出现has been successfully formatted和Exiting with status 0表示格式化成功
若出现hadoop:Cannot create directory /home/t/hadoop/name/current错误即文件夹权限不足
sudo chmod -R a+w /home/t/hadoop/name/current启动集群
start-all.sh启动完毕后,执行命令
jps若master主机看到四个开启的进程代表启动成功
若从机上看到启动进程
【问题解释】为什么没有jobtracker和tasktracker
停止集群
stop-all.sh查看运行状态
查看Namenode状况
通过Web界面查看NameNode运行状况,默认为http://localhost:50070
查看ResourceManager状况
http://localhost:8088
运行测试程序
向hadoop集群系统提交第一个mapreduce任务,统计词频
进入本地hadoop目录.此处是
/usr/hadoop-2.7.5cd /usr/hadoop-2.7.5在虚拟分布式文件系统上创建一个目录
/data/inputhdfs dfs -mkdir -p /data/input将当前目录下的
README.txt复制到虚拟分布式文件系统中hdfs dfs -put README.txt /data/input查看虚拟分布式文件系统中是否有复制上去的文件
hdfs dfs -ls /data/input向Hadoop提交单词统计任务
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /data/input /data/output/result查看结果
hdfs dfs -cat /data/output/result/part-r-00000