主流OLAP系统对比总结
联机分析处理OLAP是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。
OLTP和OLAP的区别
参考:
从大数据谈起1:OLTP和OLAP的设计区别
从大数据谈起2:分片和分层-GavinGuo-51CTO博客
联机事务处理OLTP(On-line Transaction Processing)
联机分析处理OLAP(On-Line Analytical Processing)
多维分析中的常用操作:
下面介绍数据立方体中最常见的五大操作:切片,切块,旋转,上卷,下钻。
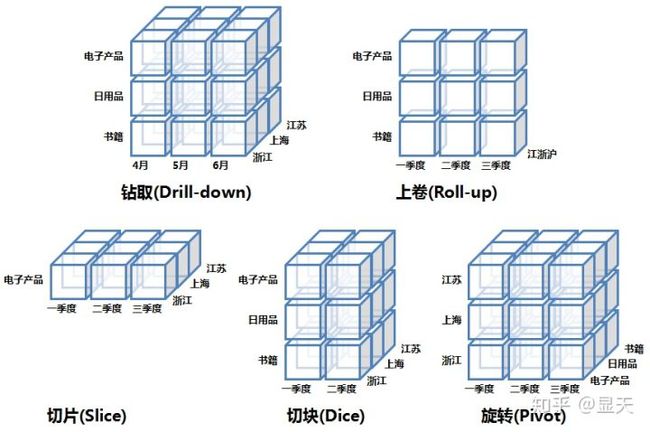
下钻(Drill-down):在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对2010年第二季度的总销售数据进行钻取来查看2010年第二季度4、5、6每个月的消费数据,如上图;当然也可以钻取浙江省来查看杭州市、宁波市、温州市……这些城市的销售数据。
上卷(Roll-up):钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据,如上图。
切片(Slice):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者2010年第二季度的数据。
切块(Dice):选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据,或者是电子产品和日用品的销售数据。
旋转(Pivot):即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
在调研了市面上主流的开源OLAP引擎后发现,目前还没有一个系统能够满足各种场景的查询需求。其本质原因是,没有一个系统能同时在数据量、性能、和灵活性三个方面做到完美,每个系统在设计时都需要在这三者间做出取舍。
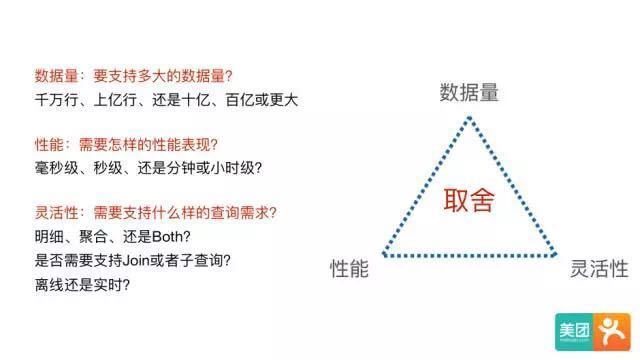
例如:
MPP架构的系统(Presto/Impala/SparkSQL/Drill等)有很好的数据量和灵活性支持,但是对响应时间是没有保证的。当数据量和计算复杂度增加后,响应时间会变慢,从秒级到分钟级,甚至小时级都有可能。
MPP即大规模并行处理(Massively Parallel Processor )。 在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据 库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。
缺点:性能不稳定
搜索引擎架构的系统(Elasticsearch等)相对比MPP系统,在入库时将数据转换为倒排索引,采用Scatter-Gather计算模型,牺牲了灵活性换取很好的性能,在搜索类查询上能做到亚秒级响应。但是对于扫描聚合为主的查询,随着处理数据量的增加,响应时间也会退化到分钟级。
缺点:性能不稳定
预计算系统(Druid/Kylin等)则在入库时对数据进行预聚合,进一步牺牲灵活性换取性能,以实现对超大数据集的秒级响应。
缺点:不太灵活
MPP和搜索引擎系统无法满足超大数据集下的性能要求,因此很自然地会考虑预计算系统。而Druid主要面向的是实时Timeseries数据,我们虽然也有类似的场景,但主流的分析还是面向数仓中按天生产的结构化表,因此Kylin的MOLAP Cube方案是最适合作为大数据量时候的引擎。
下面列举了三个olap系统
ImPala

Druid
![]()
Druid是广告分析公司Metamarkets开发的一个用于大数据实时查询和分析的分布式实时处理系统,主要用于广告分析,互联网广告系统监控、度量和网络监控。
特点:
1. 快速的交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到。
2. 高可用性——Druid的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失;
3. 可扩展——Druid已实现每天能够处理数十亿事件和TB级数据。
4. 为分析而设计——Druid是为OLAP工作流的探索性分析而构建,它支持各种过滤、聚合和查询。
应用场景:
1. 需要实时查询分析时;
2. 具有大量数据时,如每天数亿事件的新增、每天数10T数据的增加;
3. 需要一个高可用、高容错、高性能数据库时。
4. 需要交互式聚合和快速探究大量数据时
架构图:
Druid官网 Druid | About Druid
Druid:一个用于大数据实时处理的开源分布式系统
Presto

Presto是Facebook开发的分布式大数据SQL查询引擎,专门进行快速数据分析。
特点:
1. 可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
2. 直接从HDFS读取数据,在使用前不需要大量的ETL操作。
查询原理:
1. 完全基于内存的并行计算
2. 流水线
3. 本地化计算
4. 动态编译执行计划
5. 小心使用内存和数据结构
6. 类BlinkDB的近似查询
7. GC控制
Kylin

Apache Kylin最初由eBay开发并贡献至开源社区的分布式分析引擎,提供
Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据。
特点:
1. 用户为百亿以上数据集定义数据模型并构建立方体
2. 亚秒级的查询速度,同时支持高并发
3. 为Hadoop提供标准SQL支持大部分查询功能
4. 提供与BI工具,如Tableau的整合能力
5. 友好的web界面以管理,监控和使用立方体
6. 项目及立方体级别的访问控制安全