Python-新浪微博爬虫采集数据
想要采集新浪微博的数据,如何不做模拟登陆,情况如下:
Sina Visitor System
根本就无法采集到数据!
首先使用正常的账号,登陆新浪微博https://login.sina.com.cn/signup/signin.php?entry=sso如图所示:

然后下载软件Http Analyzer(下载链接见:http://download.csdn.net/detail/u010343650/9665839)进行抓包分析如图所示:
根据抓包或通过博客作者提供的链接我们可以看到:

![]()
获得上面的4个属性值(servertime、nonce、pubkey、rsakv)代码编程有:
def getLoginInfo():
preLoginURL = r'http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=&rsakt=mod&client=ssologin.js(v1.4.18)'
html = requests.get(preLoginURL).text
jsonStr = re.findall(r'\((\{.*?\})\)', html)[0]
data = json.loads(jsonStr)
servertime = data["servertime"]
nonce = data["nonce"]
pubkey = data["pubkey"]
rsakv = data["rsakv"]
return servertime, nonce, pubkey, rsakv接着我们马上需要做的预登陆了。
登陆的时候我们需要用到其中的servertime、nonce、pubkey、rsakv字段,使用抓包我们看到链接http://i.sso.sina.com.cn/js/ssologin.js查看,复制到txt文件中,并用NodePad++打开,搜索username的加密方式,如图我看到的是:用户名username经过base64编码后得到值 和 登陆密码的加密方式。


于是我们知道要获得加密后的密码,我们需要提供原始的password、servertime、nonce和pubkey 这4个参数。分别对应的方法为:
#加密用户名,su为POST中的用户名字段
def getSu(username):
su = base64.b64encode(username.encode('utf-8')).decode('utf-8')
return sudef getSp(password, servertime, nonce, pubkey):
pubkey = int(pubkey, 16)
key = rsa.PublicKey(pubkey, 65537)
# 以下拼接明文从js加密文件中得到
message = str(servertime) + '\t' + str(nonce) + '\n' + str(password)
message = message.encode('utf-8')
sp = rsa.encrypt(message, key)
# 把二进制数据的每个字节转换成相应的2位十六进制表示形式。
sp = binascii.b2a_hex(sp)
return sp我们再回到http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.18),这个地址就是进行post提交数据的地址,下面是我自己提交的数据:
postData = {
'entry': 'weibo',
'gateway': '1',
'from': '',
'savestate': '7',
'userticket': '1',
"pagerefer": "http://weibo.com/' + zhaoliying + '?is_search=0&visible=0&is_tag=0&profile_ftype=1&page=' + str(1)",
"vsnf": "1",
"su": su,
"service": "miniblog",
"servertime": servertime,
"nonce": nonce,
"pwencode": "rsa2",
"rsakv": rsakv,
"sp": sp,
"sr": "1440*900",
"encoding": "UTF-8",
"prelt": "126",
"url": "http://open.weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack",
"returntype": "META",
}提交出去后出现如图所示的问题:2次重复登录(登录一次还不够,还要进行第二次登录)

将location.replace 里面的链接解析出来,解析办法:
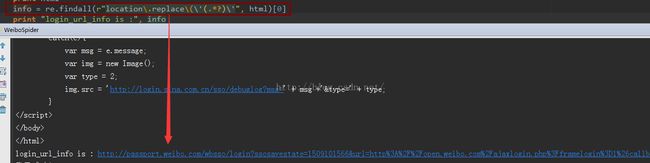
记得将第一次模拟登陆得到的session值保存起来,利用第一次得到的session开始我们第二次模拟登录 ,于是整个代码是这样的:
# -*- coding: UTF-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
__author__ = 'Mouse'
import requests
import json
import re
import base64
import rsa
import binascii
agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0'
headers = {
'User-Agent': agent
}
def get_logininfo():
preLogin_url = r'http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&' \
r'su=&rsakt=mod&client=ssologin.js(v1.4.18)'
html = requests.get(preLogin_url).text
jsonStr = re.findall(r'\((\{.*?\})\)', html)[0]
data = json.loads(jsonStr)
servertime = data["servertime"]
nonce = data["nonce"]
pubkey = data["pubkey"]
rsakv = data["rsakv"]
return servertime, nonce, pubkey, rsakv
def get_su(username):
"""加密用户名,su为POST中的用户名字段"""
su = base64.b64encode(username.encode('utf-8')).decode('utf-8')
return su
def get_sp(password, servertime, nonce, pubkey):
pubkey = int(pubkey, 16)
key = rsa.PublicKey(pubkey, 65537)
# 以下拼接明文从js加密文件中得到
message = str(servertime) + '\t' + str(nonce) + '\n' + str(password)
message = message.encode('utf-8')
sp = rsa.encrypt(message, key)
# 把二进制数据的每个字节转换成相应的2位十六进制表示形式。
sp = binascii.b2a_hex(sp)
return sp
def login(su, sp, servertime, nonce, rsakv):
post_data = {
'entry': 'weibo',
'gateway': '1',
'from': '',
'savestate': '7',
'userticket': '1',
"pagerefer": "http://weibo.com/' + zhaoliying + '?is_search=0&visible=0&is_tag=0&profile_ftype=1&page=' + str(1)",
"vsnf": "1",
"su": su,
"service": "miniblog",
"servertime": servertime,
"nonce": nonce,
"pwencode": "rsa2",
"rsakv": rsakv,
"sp": sp,
"sr": "1440*900",
"encoding": "UTF-8",
"prelt": "126",
"url": "http://open.weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack",
"returntype": "META",
}
login_url = r'http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.18)'
session = requests.Session()
res = session.post(login_url, data=post_data, headers=headers)
html = res.content.decode('gbk')
info = re.findall(r"location\.replace\(\'(.*?)\'", html)[0]
print(info)
login_index = session.get(info, headers=headers)
uuid = login_index.text
uuid_pa = r'"uniqueid":"(.*?)"'
uuid_res = re.findall(uuid_pa, uuid, re.S)[0]
web_weibo_url = "http://weibo.com/%s/profile?topnav=1&wvr=6&is_all=1" % uuid_res
weibo_page = session.get(web_weibo_url, headers=headers)
weibo_pa = r'(.*?) '
userName = re.findall(weibo_pa, weibo_page.content.decode("utf-8", 'ignore'), re.S)[0]
print('登陆成功,你的用户名为:'+userName)
return session
#调用模拟登录的程序,从网页中抓取指定URL的数据,获取原始的HTML信息存入raw_html.txt中
def get_rawhtml(session, url):
response = session.get(url)
content = response.text
print(content)
#print "成功爬取指定网页源文件并且存入raw_html.txt"
return content #返回值为原始的HTML文件内容
def crawler(session, number, url):
for n in range(number):
n = n + 1
url = 'http://weibo.com/' + url + '?is_search=0&visible=0&is_tag=0&profile_ftype=1&page=' + str(n)
print("crawler url", url)
content = get_rawhtml(session, url) # 调用获取网页源文件的函数执行
print("page %d get success and write into raw_html.txt"%n)
def main_carwler(session, url, page_num):
print("URL", url)
crawler(session, page_num, url) #调用函数开始爬取
if __name__ == '__main__':
servertime, nonce, pubkey, rsakv = get_logininfo()
print("servertime is :", servertime)
print("nonce is :", nonce)
print("pubkey is :", pubkey)
print("rsakv is :", rsakv)
#name = input('请输入用户名:')
su = get_su("")
#password = input('请输入密码:')
sp = get_sp("", servertime, nonce, pubkey)
session = login(su, sp, servertime, nonce, rsakv)
print("session is ", session)
weibo_url = "zhaoliying"
main_carwler(session, weibo_url, 2)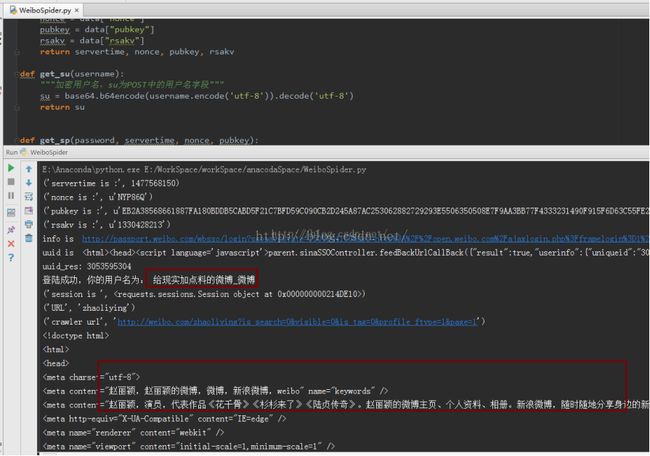
到此模拟登陆结束!