Java设计模式——合成/聚合复用原则
一、什么是合成/聚合复用原则?
合成/聚合复用原则是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分;新的对象通过向这些对象的委派达到复用已有功能的目的。
简述为:要尽量使用合成/聚合,尽量不要使用继承。
二、合成和聚合的区别;依赖和关联
合成(Composition)和聚合(Aggregation)都是关联(Association)的特殊种类。用C语言来讲,合成是值的聚合(Aggregation by Value),聚合是则是引用的聚合(Aggregation by Reference)。
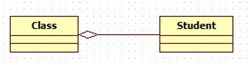
(1)聚合用来表示“拥有”关系或者整体与部分的关系。代表部分的对象有可能会被多个代表整体的对象所共享,而且不一定会随着某个代表整体的对象被销毁或破坏而被销毁或破坏,部分的生命周期可以超越整体。例如,班级和学生,当班级删除后,学生还能存在,学生可以被培训机构引用。
聚合关系UML类图
class Student {
}
class Classes{
privateStudent student;
publicClasses(Student student){
this.student=student;
}
}
(2)合成用来表示一种强得多的“拥有”关系。在一个合成关系里,部分和整体的生命周期是一样的。一个合成的新对象完全拥有对其组成部分的支配权,包括它们的创建和湮灭等。使用程序语言的术语来说,合成而成的新对象对组成部分的内存分配、内存释放有绝对的责任。
一个合成关系中的成分对象是不能与另一个合成关系共享的。一个成分对象在同一个时间内只能属于一个合成关系。如果一个合成关系湮灭了,那么所有的成分对象要么自己湮灭所有的成分对象(这种情况较为普遍)要么就得将这一责任交给别人(较为罕见)。
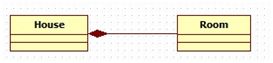
例如,一个人由头、四肢和各种器官组成,人与这些具有相同的生命周期,人死了,这些器官也就挂了。房子和房间的关系,当房子没了,房间也不可能独立存在。
合成关系UML类图
class Room{
public Room createRoom(){
System.out.println(“创建房间”);
returnnew Room();
}
}
class House{
private Room room;
public House(){
room=new Room();
}
public void createHouse(){
room.createRoom();
}
}
(3)依赖和关联
依赖(Dependency)
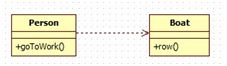
依赖是类与类之间的连接,表示一个类依赖于另外一个类的定义。依赖关系仅仅描述了类与类之间的一种使用与被使用的关系,在Java中体现为局部变量、方法的参数或者是对静态方法的调用。
依赖关系UML类图
static class Boat{
public static void row(){
System.out.println("开动");
}
}
class Person{
public void crossRiver(Boatboat){
boat.row();
}
public void fishing(){
Boat boat =new Boat() ;
boat.row();
}
public void patrol(){
Boat.row() ;
}
}
关联(Association)
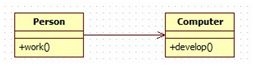
关联是类与类之间的连结。关联关系使一个类知道另外一个类的属性和方法。关联可以是双向的,也可以是单向的。体现在Java中,关联关系是通过成员变量来实现的。
一般关联关系UML类图
class Computer{
public void develop(){
System.out.println("Develop ");
}
}
class Person{
private Computer computer ;
public Person(Computer computer){
this.computer = computer ;
}
public void work(){
computer.develop() ;
System.out.println("work");
}
}
三、为什么使用合成/聚合复用,而不使用继承复用?
在面向对象的设计里,有两种基本的方法可以在不同的环境中复用已有的设计和实现,即通过合成/聚合复用和通过继承复用。两者的特点和区别,优点和缺点如下。
1、合成/聚合复用
由于合成或聚合可以将已有对象纳入到新对象中,使之成为新对象的一部分,因此新对象可以调用已有对象的功能。这样做的好处有
(1) 新对象存取成分对象的唯一方法是通过成分对象的接口。
(2) 这种复用是黑箱复用,因为成分对象的内部细节是新对象看不见的。
(3) 这种复用支持包装。
(4) 这种复用所需的依赖较少。
(5) 每一个新的类可以将焦点集中到一个任务上。
(6) 这种复用可以再运行时间内动态进行,新对象可以动态地引用与成分对象类型相同的对象。
一般而言,如果一个角色得到了更多的责任,那么可以使用合成/聚合关系将新的责任委派到合适的对象。当然,这种复用也有缺点。最主要的缺点就是通过这种复用建造的系统会有较多的对象需要管理。
2、继承复用
继承复用通过扩展一个已有对象的实现来得到新的功能,基类明显的捕获共同的属性和方法,而子类通过增加新的属性和方法来扩展超类的实现。继承是类型的复用。
继承复用的优点。
(1) 新的实现较为容易,因为超类的大部分功能可以通过继承关系自动进入子类。
(2) 修改或扩展继承而来的实现较为容易。
继承复用的缺点。
(1) 继承复用破坏包装,因为继承将超类的实现细节暴露给了子类。因为超类的内部细节常常对子类是透明的,因此这种复用是透明的复用,又叫“白箱”复用。
(2) 如果超类的实现改变了,那么子类的实现也不得不发生改变。因此,当一个基类发生了改变时,这种改变会传导到一级又一级的子类,使得设计师不得不相应的改变这些子类,以适应超类的变化。
(3) 从超类继承而来的实现是静态的,不可能在运行时间内发生变化,因此没有足够的灵活性。
由于继承复用有以上的缺点,所有尽量使用合成/聚合而不是继承来达到对实现的复用,是非常重要的设计原则。
四、从代码重构的角度理解
一般来说,对于违反里氏代换原则的设计进行重构时,可以采取两种方法:一是加入一个抽象超类;二是将继承关系改写为合成/聚合关系。
要正确的使用继承关系,必须透彻的理解里氏代换原则和Coad条件。
区分“Has-A”和“Is -A”
“Is-A”是严格的分类学意义上的定义,意思是一个类是另以个类的“一种”。而“Has-A”表示某一个角色具有某一项责任。
导致错误的使用继承而不是合成/聚合的一个常见原因是错误的把“Has-A”当做“Is-A”。“Is-A”代表一个类是另一个类的一种;“Has-A”代表一个类是另一个类的一个角色,而不是另一个类的一个特殊种类。这是Coad条件的第一条。
下面类图中描述的例子。“人”被继承到“学生”、“经理”和“雇员”等子类。而实际上,学生”、“经理”和“雇员”分别描述一种角色,而“人”可以同时有几种不同的角色。比如,一个人既然是“经理”,就必然是“雇员”;而“人”可能同时还参加MBA课程,从而也是一个“学生”。使用继承来实现角色,则只能使每一个“人”具有Is-A角色,而且继承是静态的,这会使得一个“人”在成为“雇员”身份后,就永远为“雇员”,不能成为“学生”和“经理”,而这显然是不合理的。
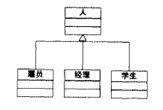
这一错误的设计源自于把“角色”的等级结构和“人”的等级结构混淆起来,把“Has-A”角色误解为“Is -A”角色。因此要纠正这种错误,关键是区分“人”与“角色”的区别。下图所示的的设计就正确的做到了这一点。
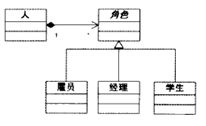
从上图可以看出,每一个“人”都可以有一个以上的“角色”,所有一个“人”可以同时是“雇员”,又是“经理”,甚至同时又是“学生”。而且由于“人”与“角色”的耦合是通过合成的,因此,角色可以有动态的变化。一个“人”可以开始是“雇员”,然后晋升为“经理”,然后又由于他参加了MBA课程,又称为了“学生“。
当一个类是另一个类的角色时,不应当使用继承描述这种关系。
与里氏代换原则联合使用
里氏代换原则是继承复用的基石。如果在任何可以使用B类型的地方都可以使用S类型,那么S类型才可以称为B类型的子类型(SubType),而B类型才能称为S类型的基类型(BaseType)。
换言之,只有当每一个S在任何情况下都是一种B的时候,才可以将S设计成B的子类。如果两个类的关系是“Has-A”关系而不是“Is -A”,这两个类一定违反里氏代换原则。
只有两个类满足里氏代换原则,才有可能是“Is -A”关系。