两种高效的事件处理模式和并发模式
服务器编程基本框架:
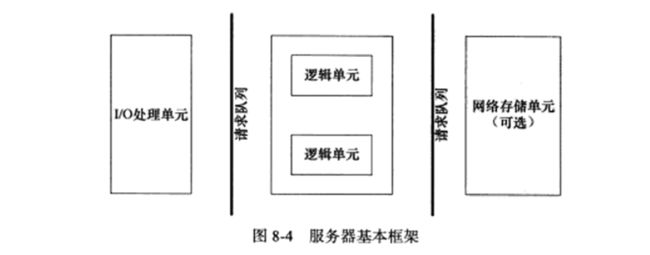
事件处理模式
一般来说,IO复用机制都需要一个事件分离器,它会将事件源分发给对应的处理者,即将那些读写事件源分发给各读写事件处理者。Reactor和Proactor就是两种最常用的事件处理模式。
Reactor
Reactor模式是指主线程只负责监听文件描述符上是不是有事件发生,有的话就将该事件通知工作线程,除此之外,主线程不需要做其他任何工作,其他的数据读写、逻辑处理等都是在工作线程中完成的。比如说在Reactor模式下的读操作过程:
- 在主线程上注册读就绪事件和相应的事件处理器
- 事件分离器等待事件
- 事件到来,激活分离器,分离器调用事件对应的工作线程。
- 工作线程完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。

Proactor
Proactor模式与Reactor一样,都是对某个IO事件进行通知,不同的是,Proactor模式中主线程不止监听文件描述符上的事件是否发生,还要完成所有的读写操作,而工作线程要做的只是处理逻辑问题。也就是说,Proactor模式将所有的I/O操作都交给主线程和内核来处理。下面看一下Proactor模式下的读操作过程:
- 在主线程上注册读完成事件和相应的事件处理器,并告诉内核用户读缓冲区的位置
- 事件分离器等待操作完成事件
- 在分离器等待过程中,操作系统利用并行的内核线程执行实际的读操作,并将结果数据存入用户自定义缓冲区,最后通知事件分离器读操作完成。
- 事件分离器呼唤工作线程。
- 工作线程处理用户自定义缓冲区中的数据,然后启动一个新的异步操作,并将控制权返回事件分离器。
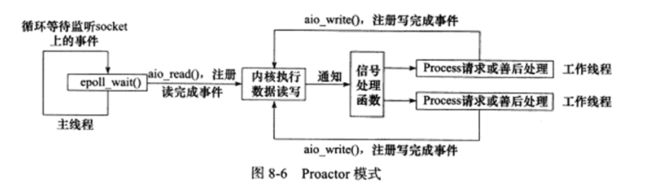
从上面可以看出,Reactor和Proactor模式的主要区别就是真正的读取和写入操作是由谁来完成的,Reactor中需要应用程序自己读取或者写入数据,而Proactor模式中,应用程序不需要进行实际的读写过程,它只需要从缓存区读取或者写入即可,操作系统会读取缓存区或者写入缓存区到真正的IO设备.所以说,同步I/O模型通常用于实现Reactor模式,异步I/O模型则用于实现Proactor模式。异步情况下(Proactor),当调用事件处理器时,表示IO操作已经完成;同步情况下(Reactor),调用事件处理器时,表示IO设备可以进行可读或可写操作(can read or can write)。
模拟Proactor:
我们还可以使用同步I/O来模拟异步I/O,实际上也就是用主线程来执行Procactor中内核做的数据读写操作,主线程读写完成后,再向工作线程通知,这样在主线程看来,就是直接获得了数据读写的结果。
以读操作为例子,改进过程如下:
- 注册读就绪事件及其处理器,并为分离器提供数据缓冲区地址,需要读取数据量等信息。
- 分离器等待事件(如在select()上等待)
- 事件到来,激活分离器。分离器执行一个非阻塞读操作(它有完成这个操作所需的全部信息),最后调用对应处理器。
- 事件处理器处理用户自定义缓冲区的数据,注册新的事件(当然同样要给出数据缓冲区地址,需要读取的数据量等信息),最后将控制权返还分离器。
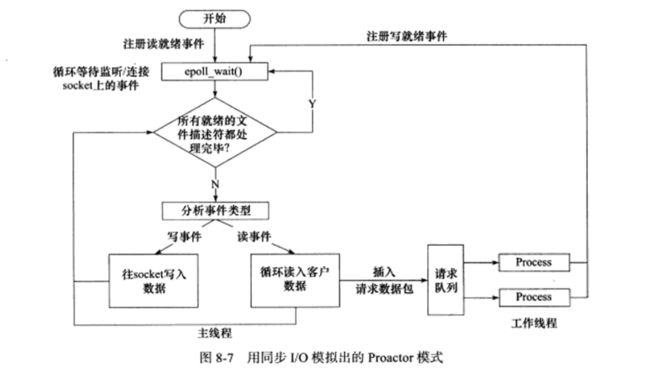
我们将Reactor转化为Proactor模式后,可以发现其实模型实际完成的工作量没有增加,只不过参与者间对工作职责稍加调换,通过给分发器(即上述的主线程)添加一些功能,来让Reactor模式转换为Proactor模式。没有工作量的改变,自然不会造成性能的削弱。对于不提供异步IO API的操作系统来说,这种办法可以隐藏socket API的交互细节,从而对外暴露一个完整的异步接口。
并发模式
半同步/半异步模式:
先解释一下同步和异步的区别,与刚才I/O的同步、异步不一样,在并发模式中,这里的“同步"指的是程序完全按照代码的顺序执行,“异步”指的是程序的执行需要由系统事件来驱动,比如说信号、中断等。下图就清楚的解释了同步和异步操作的过程:
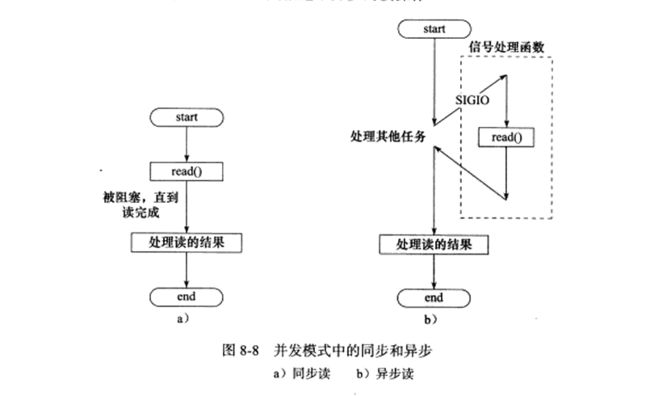
这样看来,显然异步线程的执行效率高,但是它的编写相对复杂,难于调试,然而同步线程刚好相反,逻辑简单,但效率较差。半同步/半异步模式就结合了同步线程与异步线程的优点,它在处理I/O事件时使用异步线程,处理客户逻辑则使用同步线程。这样既满足了客户连接的实时性,又能同时处理多个连接。那么它是如何同将同步与异步结合起来的?实现半同步/半异步模式需要三个模块:异步处理模块、同步处理模块和队列模块。
举个例子:
"一家律师事务所有一个前台接待员,每一位想寻找律师的客户,都会先由接待员接待,接待员会给每位顾客都安排一个律师来处理客户的案件,(假设一个律师在同一时间只能处理一个客户的案子)接待员只有一个人,但他可以接待所有客户,不过它也只负责接待,哪怕你的案件再复杂,都是律师的事儿,跟接待员没关系,而分配的依据可以是预约情况或者案件类型。"
在上面这个例子中,那个前台接待员就是异步处理模块,他一个人要处理多个I/O请求(客户),律师则是同步处理模块,每一个律师分别对应一个客户,根据客户的不同需求作出处理,而要让异步模块与同步模块连接起来,就需要插入一个队列模块,它将接待完毕的客户排一个队,等那个律师有时间的时候就来这个队列里领走一个客户处理,当然,队列怎么排,分为几个队列,就看客户到达的时间或者需求来决定了。
在实际使用中,我们一般使用多路复用IO在主线程上监听客户端的连接,监听到新的客户请求后,就将其封装成请求对象,然后插入请求队列中,同时,有许多工作线程可以来读取并处理该请求对象,具体选择哪个工作线程来为新的客户进行处理,取决于请求队列的设计。在这个模式中,最可能被阻塞的操作放在同步模块中,这样不会影响到异步模块的处理,不同模块可以使用不同的同步策略,互不干扰,模块间通信则使用ipc实现,但这样也造成了在同步模块和异步模块之间使用队列模块传送数据的时候,由于数据拷贝和上下文切换导致的性能消耗。
半同步/半反应堆模式:
半同步/半反应堆模式其实是半同步/半异步模式的一种变体,其中异步线程只有一个,由主线程充当,如果有连接到来或事件发生,主线程就将该socket插入请求队列中,直到这里与半同步/半异步模式都是一样的,但是在半同步/半反应堆模式中,当有任务到来时,选择哪个工作线程不是由算法或时间设置好的,而是由所有的工作线程竞争来的,它们通过竞争(比如申请互斥锁)来获得任务的接管权,这样的竞争机制使得当前只有空闲的工作线程才能来竞争,自然的形成了资源平衡。

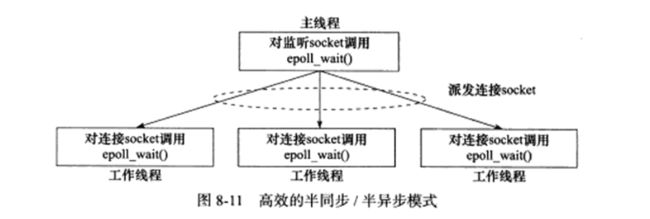
上图中主线程插入的请求队列是就绪的连接socket,这说明图示的半同步/半反应堆模式采用的事件处理模式是Reactor模式。半同步/半反应堆模式也可以采用模拟Proactor的事件处理模式,也就是由主线程完成数据的读写。主线程一般会将应用程序数据与其他信息一起封装为一个任务对象,然后将其插入请求队列。工作线程可以直接处理,不用读写。 半同步/半反应堆模式因为也是主线程和工作线程共享任务队列,所以也会存在与半同步/半异步模式一样的问题,就是每次堆队列进行操作,都需要进行加锁,从而消耗cpu的时间。而且一个线程同一时间只能处理一个客户请求,如果队列中积累了很多任务,增加工作线程的话,工作线程的切换也会耗费大量cpu时间,这种问题有一种相对高效的解决方式:即在每个工作线程上也使用epoll_wait,这样每个工作线程都能处理多个客户连接了。
领导者/追随者模式:
说了这么多,旨在于介绍每一种模型的处理方法与优缺点,我们并没有说哪一种模型就一定优于其他模型,因为在具体的应用中,不同的逻辑业务会决定到底使用哪一种模型才是最优的,就像web服务器,它主要的时间其实都花在了I/O处理上,实际的业务逻辑操作相对比较简单,如果使用半同步/半异步模型的话,反而会因为进程或线程间的切换而损失效率。所以对于模型的选择,还是具体问题具体分析吧~