Spark源码编译及使用
这一篇我们来把Spark环境搭建起来。我们使用编译源码的方式来生成Spark的安装包,为什么不直接用官方的安装包呢?因为我们在使用spark的时候会结合Hadoop来使用,有自己的需求,所以我们使用源码来编译。
首先去官网上来下载源码。

我们选择2.1.0版本。然后解压。spark源码使用maven构建的,所以在编译之前我们最好下载一个maven,maven版本至少在3.3.9至少,另外Java 版本要在7+之上。spark由Scala编写,所以还要下载Scala环境。
解压后我们发现Spark根目录有一个pom.xml文件,我们就在这个目录之前编译的命令即可,因为我们要结合Hadoop使用,所以在pom.xml中加入Hadoop使用到的jar包。我们在repositories标签下加入Hadoop的仓库位置,便于下载jar包。
<repositories>
<repository>
<id>centralid>
<name>Maven Repositoryname>
<url>https://repo1.maven.org/maven2url>
<releases>
<enabled>trueenabled>
releases>
<snapshots>
<enabled>falseenabled>
snapshots>
repository>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
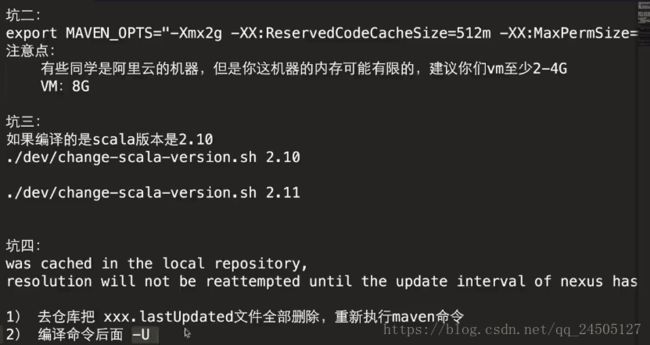
repositories>注意2:maven环境内存要符合条件。如果用maven进行编译需要先设置maven内存(如果用make-distribution.sh ,则在这个脚本中进行修改):
export MAVEN_OPTS=”-Xmx2g -XX:ReservedCodeCacheSize=512m”
注意3:如果scala 版本为2.10 ,需要进行 ./dev/change-scala-version.sh 2.10
我的版本为2.11.8,我执行了这个命令 ./dev/change-scala-version.sh 2.11
注意4:
推荐使用一下命令编译:
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0 -X
我们用的是spark的make-distribution.sh脚本进行编译,这个脚本其实也是用maven编译的,–tgz 指定以tgz结尾 –name 后面跟的是我们Hadoop的版本,在后面生成的tar包我们会发现名字后面的版本号也是这个(这个可以看make-distribution.sh源码了解),-Pyarn 是基于yarn,-Dhadoop.version=2.6.0-cdh5.7.0 指定Hadoop的版本。
编译过程比较长,因为会下载各种包,我们看下编译成功后的目录:
中间编译过程中遇到各种问题,只要注意以上的点,基本就可以了,我编译过程中因为用的腾讯云的服务器,内存只有一个G,导致每次编译都会报内存不足,Java申请内存失败的错误,然后又在虚拟机上新建了个3个G的系统,编译成功了。
TMD,为啥CSDN为啥保存不了,写了一早上没了,再写又没了!!!
8月22日更新。。。
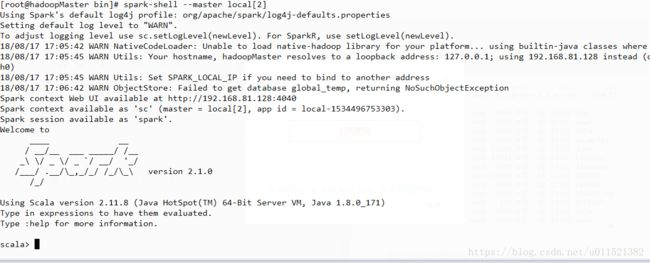
我们下面来以local的方式启动spark
进入bin目录下执行下面命令:
spark-shell master local[2]local[2]的意思是两个线程运行。启动后的结果如下图:
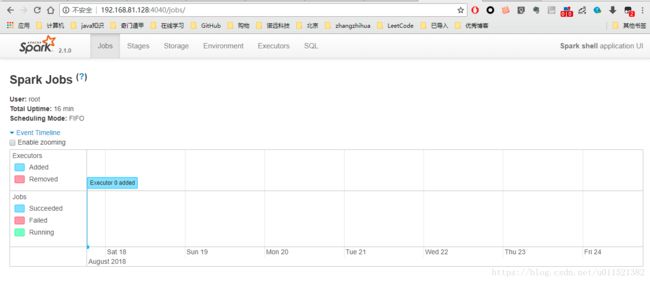
我们可以看见打印的日志中可以通过访问web的方式查看UI界面(如果ip无法访问注意要把服务器的防火墙打开)。如下图:
下面介绍standalone模式启动spark。启动之前,讲一下spark的架构。
Spark Standalone模式的架构和Hadoop HDFS/YARN很类似:
1 master + n worker
都是1个主节点,n个从节点。我们在配置文件如何配置呢:
比如我们配的是hadoop1 是主节点,其他都是从节点。
hadoop1 : master
hadoop2 : worker
hadoop3 : worker
hadoop4 : worker
…
hadoop10 : worker
进入conf目录,打开slaves文件,直接配置从节点即可,
hadoop2
hadoop3
hadoop4
....
hadoop10我们这里只有一台机器,所以主从节点在一台机器上,slaves文件就是一个localhost。

接下来配置spark-env.sh
SPARK_MASTER_HOST=hadoopMaster
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_INSTANCES=1这个配置是
spark master的host是hadoopMaster
worker的核心是两个
worker内存是2G
worker实例是1个
下面我从sbin目录启动spark:
start-all.sh //会在 hadoop1机器上启动master进程,在slaves文件配置的所有hostname的机器上启动worker进程
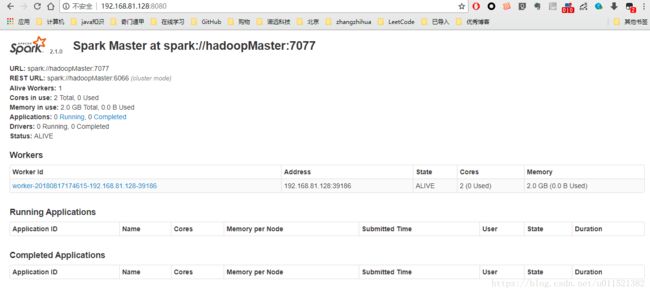
我们从上图可以看到有一个worker实例正在运行。内存使用为2个G,这个是从上面spark-env.sh配置出来的。
这样我们就把sparkmaster启动起来了,我们看到master的地址是spark://hadoopMaster:7077
那么现在我们通过shell来连接这个master,
spark-shell master spark://hadoopMaster:7077

接下来我们看下UI界面有什么变化:
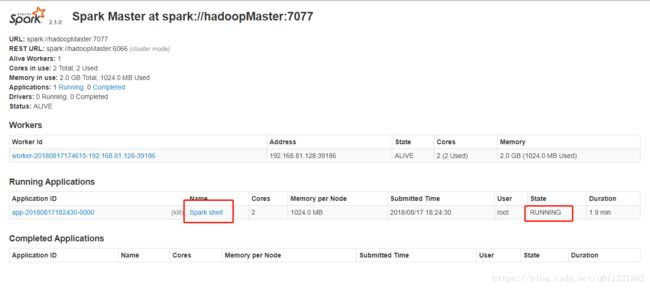
可以看出,新增了一个shell的应用,两个核心,1G内存。
下面我们介绍下spark的简单使用。例子是wordcount的词频统计。
文本在 /data/wc.txt。内容如下:
hello,world,hello
hello,world
welcome执行如下命令:
val file = spark.sparkContext.textFile("file:///data/wc.txt")
val wordCounts = file.flatMap(line => line.split(",")).map((word => (word, 1))).reduceByKey(_ + _)
wordCounts.collect如下图:

可以看出单词词频被正确统计出来了。
我们看下webUI的变化:

可以看出已经完成了一个job作业,点击进去看一下:
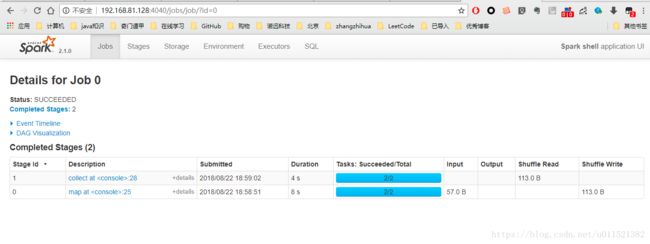
这个显示的 是作业的两个步骤,先做了map操作,然后是collect.
spark的简单使用就写到这里。(再次吐槽csdn的markdown,只要切到另外一个网页,内容就没了,,,,不会自动保存。)