PyTorch深度学习模型分布式训练原理(Distributed training of Deep Learning models with PyTorch)
本文的目的是在训练大规模深度学习(DL)模型的背景下演示分布式计算的思想。 特别是,本文首先介绍了分布式计算的基本概念以及它如何适合深度学习的思想。 然后,它继续列出用于建立能够处理分布式应用程序的环境的标准要求(硬件和软件)。 最后,为了提供实践经验,它从理论和实现的角度演示了一种用于训练DL模型的特定分布式算法(即,同步SGD)。
什么是分布式计算?
分布式计算是指编写程序的方式,该程序使用通过网络连接的几个不同的组件。 通常,通过能够并行处理高密度数值计算的计算机的这种布置来实现大规模计算。 在分布式计算术语中,这些计算机通常称为节点,这些节点的集合形成了网络上的群集。 这些节点通常通过以太网连接,但也使用其他高带宽网络来充分利用分布式体系结构。
深度学习如何从分布式计算中受益?
尽管神经网络是DL的主要力量,但它在文献中已有相当长的历史了,但是直到最近,没有人能够充分利用它的全部潜力。 迅速普及的主要原因之一是具有强大的计算能力,这正是我们在本文中尝试解决的想法。 深度学习需要在大量数据上使用大量参数训练深度神经网络(DNN)。 分布式计算是充分利用现代硬件的理想工具。 这是核心思想:
精心设计的分布式算法可以:
- “分布式”计算(DL模型的前向和后向传递)以及跨多个节点的数据以进行连贯处理。
- 然后,它可以在节点之间建立有效的“同步”以实现一致性。
MPI:分布式计算标准
您必须习惯的另一种术语-消息传递接口(MPI)。 MPI是几乎所有分布式计算的主力军。 MPI是一种开放标准,它定义了一组有关节点如何通过网络相互通信的规则以及编程模型/ API。 MPI不是软件或工具,而是规范。 1991年夏季,一群来自学术界和工业界的个人,组织挺身而出,最终促成了MPI论坛的创立。 达成共识的论坛精心设计了一个库的语法和语义规范,以作为不同硬件供应商提出可移植/灵活/优化实现的指南。 一些硬件供应商拥有自己的MPI实现-“ OpenMPI”,“ MPICH”,“ MVAPICH”,“ Intel MPI”等等。
在本教程中,我们将使用英特尔MPI,因为它性能极佳,并且已针对英特尔平台进行了优化。 原始的英特尔MPI是一个C库,本质上非常低级。
设置
正确设置分布式系统非常重要。 没有适当的硬件和网络安排,即使对编程模型有概念上的了解,它也几乎没有用。 以下是需要进行的关键安排:
- 通常需要在公共网络中连接的一组节点以形成群集。 建议使用高端服务器作为节点,并使用InfiniBand之类的高带宽网络。
- 在集群中的所有节点上都需要具有完全相同名称的用户帐户的Linux系统。
- 节点之间必须具有无密码的SSH连接。 这对于无缝连接至关重要。
- 必须安装MPI实现。 本教程仅关注英特尔MPI。
- 需要一个公共文件系统,该文件系统在所有节点上都可见,并且分布式应用程序必须驻留在该文件系统上。 网络文件系统(NFS)是实现此目的的一种方法。
并行化策略的类型
并行化深度学习模型有两种流行的方式:
- 模型并行
- 数据并行
模型并行
模型并行性是指模型在逻辑上分为几个部分(即,一个部分中的某些层,而另一部分中的某些层),然后将其放置在不同的硬件/设备上。尽管将零件放在不同的设备上确实在执行时间(数据的异步处理)方面有很多好处,但通常可以采用它来避免内存限制。具有大量参数的模型由于这种类型的策略而受益,这些模型由于内存占用量大而难以放入单个系统中。
数据并行
另一方面,数据并行性是指通过位于不同硬件/设备上的同一网络的多个副本来处理多段数据(技术上为批次)。与模型并行性不同,每个副本可能是整个网络,而不仅仅是一部分。您可能会采取这种策略
猜测,可以随着数据量的增加而很好地扩展。但是,由于整个网络必须驻留在单个设备上,因此无法帮助占用大量内存的模型。下图应清楚说明。
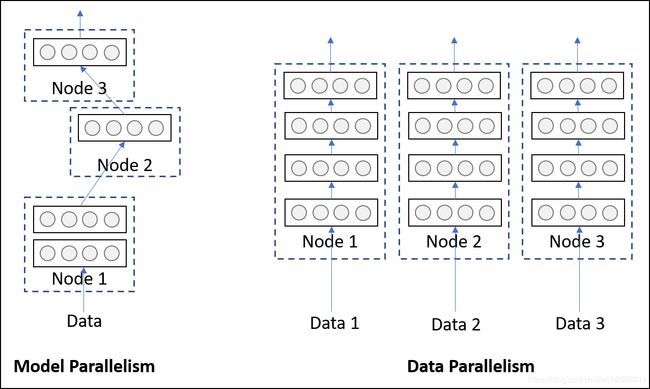
Model vs Data parallelism
实际上,数据并行性在大型组织中更为流行并且经常用于执行生产质量DL训练算法。 因此,在本教程中,我们将专注于数据并行性。
“ torch.distributed” API
PyTorch提供了一个非常优雅且易于使用的API,作为使用C语言编写的基础MPI库的接口。PyTorch需要从源代码进行编译,并且必须与系统上安装的Intel MPI链接。 现在,我们将看到torch.distributed的基本用法以及如何执行它。
# filename 'ptdist.py'
import torch
import torch.distributed as dist
def main(rank, world):
if rank == 0:
x = torch.tensor([1., -1.]) # Tensor of interest
dist.send(x, dst=1)
print('Rank-0 has sent the following tensor to Rank-1')
print(x)
else:
z = torch.tensor([0., 0.]) # A holder for recieving the tensor
dist.recv(z, src=0)
print('Rank-1 has recieved the following tensor from Rank-0')
print(z)
if __name__ == '__main__':
dist.init_process_group(backend='mpi')
main(dist.get_rank(), dist.get_world_size())
使用mpiexec执行上述代码,任何标准的MPI实现都附带有一个分布式进程调度程序,其结果是:
cluster@miriad2a:~/nfs$ mpiexec -n 2 -ppn 1 -hosts miriad2a,miriad2b python ptdist.py
Rank-0 has sent the following tensor to Rank-1
tensor([ 1., -1.])
Rank-1 has recieved the following tensor from Rank-0
tensor([ 1., -1.])
- 要执行的第一行是dist.init_process_group(backend),它基本上在参与节点之间建立内部通信通道。它需要一个参数来指定要使用的后端。由于我们在整个过程中都使用MPI,因此本例中其后端=“ mpi”。还有其他后端(例如“ TCP”,“ Gloo”和“ NCCL”)。
- 需要检索两个参数-world大小和rank。
- “world”是指在mpiexec调用的特定上下文中指定的所有节点的集合(请参见mpiexec中的-hosts标志)。
- “rank”是MPI运行时分配给每个进程的唯一整数。它从0开始。-hosts参数中指定它们的顺序用于分配数字。因此,在这种情况下,节点“ miriad2a”上的进程将被分配为rank0,而“ miriad2b”将被分配为rank1。
- x是rank0打算发送到rank1的张量。它通过dist.send(x,dst = 1)发送。
- z是rank1在接收张量之前创建的东西。我们需要一个已经创建的张量与保持器形状相同的张量,用于接收传入的张量。 z的值最终将由x的值替换。
- 就像dist.send(…)一样,接收方是dist.recv(z,src = 0),它将张量接收到z中。
Communication collectives
在上一节中,我们看到了“点对点”(peer-to-peer)通信的示例,其中rank(s)在给定的上下文中将数据发送到特定rank(s)。 尽管这很有用,因为它为用户提供了对通信的精细控制,但是还有其他一些标准的和经常使用的通信模式,称为集体(collective)。 以下是在同步SGD算法的上下文中我们感兴趣的一种特定集合(称为all-reduce)的描述。
The “All-reduce” collective
All-reduce是一种同步通信的方式,其中在所有rank上执行给定的归约运算,并使归结后的结果可用于所有rank。 下图说明了这个想法(使用求和作为归约运算)。
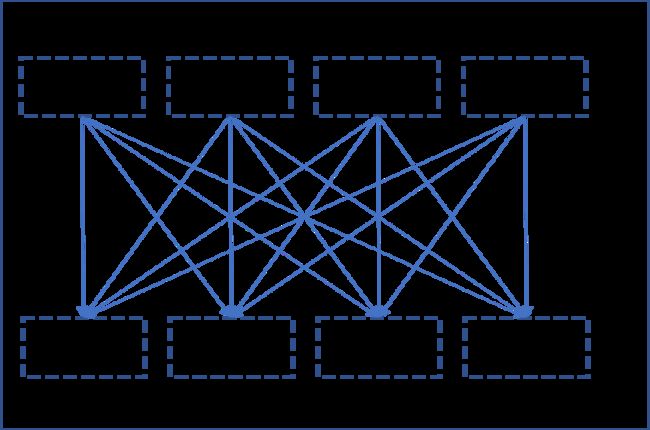
All reduce collective
def main(rank, world):
if rank == 0:
x = torch.tensor([1.])
elif rank == 1:
x = torch.tensor([2.])
elif rank == 2:
x = torch.tensor([-3.])
dist.all_reduce(x, op=dist.reduce_op.SUM)
print('Rank {} has {}'.format(rank, x))
if __name__ == '__main__':
dist.init_process_group(backend='mpi')
main(dist.get_rank(), dist.get_world_size())
When launched in a world of 3, results in
cluster@miriad2a:~/nfs$ mpiexec -n 3 -ppn 1 -hosts miriad2a,miriad2b,miriad2c python ptdist.py
Rank 1 has tensor([0.])
Rank 0 has tensor([0.])
Rank 2 has tensor([0.])
- if rank == …elif是我们在分布式计算中一次又一次遇到的模式。 在这种情况下,它用于在不同rank上创建不同的张量。
- 它们都以求和运算(dist.reduce_op.SUM)一起执行全部归约(如果…elif块,则dist.all_reduce(…)位于外部)。
- 将每个rank的x相加,然后将总和放入每个rank的x中。
继续进行深度学习:
假定读者熟悉标准的随机梯度下降(SGD)算法,该算法通常用于训练深度学习模型。 现在,我们将看到SGD的一种变体(称为“同步SGD”),该变体利用了All-reduce集合进行扩展。 为了打基础,让我们从标准SGD的数学公式开始。
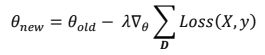
其中D是一组样本(小批量),θ是所有参数的集合,λ是学习率,Loss(X,y)是D中所有样本的平均损失函数。
同步SGD依赖的核心技巧是将更新规则中的总和分配给(迷你)批的较小子集。 D被分成R个子集D 1,D 2,…。 。 (最好每个样本中有相同数量的样本),这样
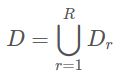
拆分标准SGD更新公式的总和会导致
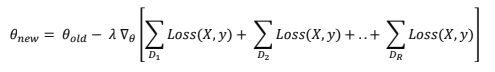
现在,由于梯度算子是分布在求和算子上的,我们得到
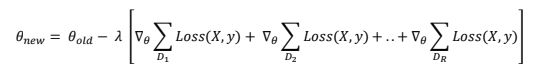
我们从中得到什么?
看一下上面方程中的那些单独的梯度项(在方括号内)。 现在可以独立计算它们并求和以得到原始梯度,而不会出现任何损失/近似值。 这就是数据并行性的体现。 这是整个故事:
- 将整个数据集分成R个相等的块。 字母R用于表示副本。
- 使用MPI启动R进程/rank,并将每个进程绑定到数据集的一个块。
- 让每个rank从其自己的数据部分中使用大小为B的小批量(dᵣ)计算梯度,即rankr计算
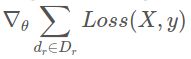
- 汇总所有rank的所有梯度,并使所得的梯度可用于所有rank以进一步进行。
最后一点就是全约算法。 因此,每次所有秩在数据集自己的部分上计算出一个梯度(大小为B的小批量)时,都必须执行all-reduce。 这里要注意的一个微妙点是,将所有Rrank引线的梯度(在B大小的微型批次上)求和
达到有效的批量大小
![]()
以下是实施的关键部分(未显示样板代码)
model = LeNet()
# first synchronization of initial weights
sync_initial_weights(model, rank, world_size)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.85)
model.train()
for epoch in range(1, epochs + 1):
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
# The all-reduce on gradients
sync_gradients(model, rank, world_size)
optimizer.step()
def sync_initial_weights(model, rank, world_size):
for param in model.parameters():
if rank == 0:
# Rank 0 is sending it's own weight
# to all it's siblings (1 to world_size)
for sibling in range(1, world_size):
dist.send(param.data, dst=sibling)
else:
# Siblings must recieve the parameters
dist.recv(param.data, src=0)
def sync_gradients(model, rank, world_size):
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM)
- 所有R rank均使用随机权重创建自己的模型副本/副本。
- 具有随机权重的单个副本可能会导致初始去同步。最好在所有副本之间同步初始权重。 sync_initial_weights(…)例程正是这样做的。让任何一个队伍将其权重传递给其兄弟姐妹,并且兄弟姐妹必须接受它们以对其进行初始化。
- 从rank的各个部分中提取一个小批量(大小为B),并计算前进和后退通过(梯度)。作为设置的一部分,这里要注意的重要一点是,所有进程/rank都应具有自己可见的数据部分(通常在其自己的硬盘上或在共享文件系统上)。
- 对每个副本的梯度执行全部归约集体,并将求和作为归约运算。 sync_gradients(…)例程执行梯度同步。
- 梯度同步后,每个副本都可以独立地按自己的权重执行标准的SGD更新。 Optimizer.step()照常进行工作。
现在可能会出现一个问题,“我们如何确保独立更新保持同步?”。
如果我们看一下第一次更新的更新方程式
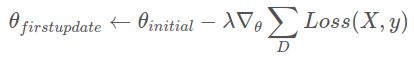
上面的第2点和第4点可确保初始权重和梯度分别同步。 出于明显的原因,它们的线性组合也将是同步的(λ为常数)。 所有连续的更新都具有类似的逻辑。
性能比较:
任何分布式算法的最大瓶颈是同步。 仅当同步时间明显少于计算时间时,分布式算法才有用。 让我们对标准SGD和同步SGD进行简单的比较,以了解哪种情况下才是有益的。
定义。 假设整个数据集的大小为N。网络处理的大小为B的小批处理需要花费时间Tcomp。 在分布式情况下,全缩减同步花费的时间为Tsync。 如果有R个副本,则需要一个纪元的时间
对于非分布式(标准)SGD:
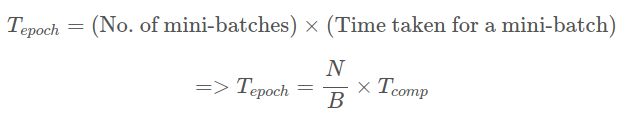
对于同步SGD:
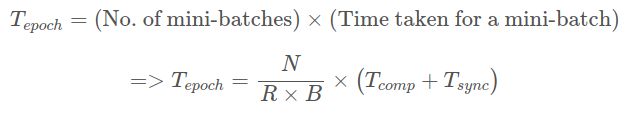
因此,要使分布式环境比非分布式环境显着受益,我们需要
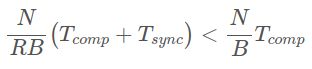
或等效
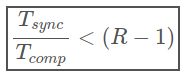
可以对导致上述不平等的三个因素进行调整,以从分布式算法中获取越来越多的收益。
- 通过在高带宽(快速)网络上连接节点,可以减少Tsync。
- 可以通过增加批大小B来增加Tcomp。
- 可以通过在网络上连接更多节点并具有更多副本来增加R。
希望这篇文章足够清晰,能够在深度学习的背景下传达分布式计算的中心思想。 尽管同步SGD非常流行,但是还有其他分布式算法也很常用(例如异步SGD及其变体)。 但是,更重要的是能够以并行方式考虑深度学习方法。 请意识到,并非所有算法都可以立即并行进行。 有些需要近似以打破原始算法给出的理论保证。 算法设计者/实施者必须以有效的方式解决这些近似问题。
原文:https://medium.com/intel-student-ambassadors/distributed-training-of-deep-learning-models-with-pytorch-1123fa538848
扩展阅读:MPI Reduce and Allreduce