MessagePack简介及使用
什么是MessagePack
官方msgpack官网用一句话总结:
It’s like JSON.
but fast and small.
简单来讲,它的数据格式与json类似,但是在存储时对数字、多字节字符、数组等都做了很多优化,减少了无用的字符,二进制格式,也保证不用字符化带来额外的存储空间的增加。以下是官网给出的简单示例图:

图上这个json长度为27字节,但是为了表示这个数据结构,它用了9个字节(就是那些大括号、引号、冒号之类的,他们是白白多出来的)来表示那些额外添加的无意义数据。msgpack的优化在图上展示的也比较清楚了,省去了特殊符号,用特定编码对各种类型进行定义,比如上图的A7,其中前四个bit A就是表示str的编码,而且它表示这个str的长度只用半个字节就可以表示了,也就是后面的7,因此A7的意思就是表示后面是一个7字节长度的string。
有的同学就会问了,对于长度大于15(二进制1111)的string怎么表示呢?这就要看messagepack的压缩原理了。
MessagePack的压缩原理
核心压缩方式可参看官方说明messagepack specification
概括来讲就是:
- true、false 之类的:这些太简单了,直接给1个字节,(0xc2 表示true,0xc3表示false)
- 不用表示长度的:就是数字之类的,他们天然是定长的,是用一个字节表示后面的内容是什么,比如用(0xcc 表示这后面,是个uint 8,用oxcd表示后面是个uint 16,用 0xca 表示后面的是个float 32)。对于数字做了进一步的压缩处理,根据大小选择用更少的字节进行存储,比如一个长度<256的int,完全可以用一个字节表示。
- 不定长的:比如字符串、数组、二进制数据(bin类型),类型后面加 1~4个字节,用来存字符串的长度,如果是字符串长度是256以内的,只需要1个字节,MessagePack能存的最长的字符串,是(2^32 -1 ) 最长的4G的字符串大小。
- 高级结构:MAP结构,就是k-v 结构的数据,和数组差不多,加1~4个字节表示后面有多少个项
- Ext结构:表示特定的小单元数据。也就是用户自定义数据结构。
我们看一下官方给出的stringformat示意图
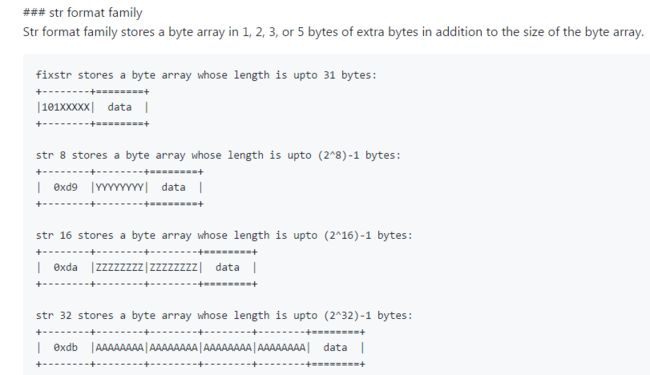
对于上面的问题,一个长度大于15(也就是长度无法用4bit表示)的string是这么表示的:用指定字节0xD9表示后面的内容是一个长度用8bit表示的string,比如一个160个字符长度的字符串,它的头信息就可以表示为D9A0。
这里值得一提的是Ext扩展格式,正是这种结构才保证了messagepack的完备性,因为实际的数据接口中自定义结构是非常常见的,简单的已知数据类型和高级结构map、array等并不能满足需求,因此需要一个扩展格式来与之配合。比如一个下面的接口格式:
{
"error_no":0,
"message":"",
"result":{
"data":[
{
"datatype":1,
"itemdata":
{//共有字段45个
"sname":"\u5fae\u533b",
"packageid":"330611",
…
"tabs":[
{
"type":1,
"f":"abc"
},
…
]
}
},
…
],
"hasNextPage":true,
"dirtag":"soft"
}
}怎么把tabs中的子数据作为一个整体写入itemdata这个结构中呢?itemdata又怎么写入它的上层数据结构data中?这时Ext出马了。我们可以自定义一种数据类型,指定它的Type值,当解析遇到这个type时就按我们自定义的结构去解析。具体怎么实现后面我们在代码示例的时候会讲到。
MessagePack的源码
github地址
从这里也能看到它对各种语言的支持:c、java、ruby、python、php...
感兴趣的可以自己阅读,比较简单易懂,这里不再赘述,下面重点讲一下具体用法。
android studio中如何使用MessagePack
首先需要在app的gradle脚本中添加依赖
compile 'org.msgpack:msgpack-core:0.8.11'java版本用法的sample可以在源码的/msgpack-java/msgpack-core/src/test/java/org/msgpack/core/example/MessagePackExample.java中看到。
值得一提的是官方的说明文档还停留在1.x版本,建议大家直接去看最新demo。
通过MessagePack这个facade获取用户可用的对象packer和unpacker。
1. 数据打包
主要有两种用法:
-
通过 MessageBufferPacker将数据打包到内存buffer中
MessageBufferPacker packer = MessagePack.newDefaultBufferPacker(); packer .packInt(1) .packString("leo") // pack arrays int[] arr = new int[] {3, 5, 1, 0, -1, 255}; packer.packArrayHeader(arr.length); for (int v : arr) { packer.packInt(v); } // pack map (key -> value) elements packer.packMapHeader(2); // the number of (key, value) pairs // Put "apple" -> 1 packer.packString("apple"); packer.packInt(1); // Put "banana" -> 2 packer.packString("banana"); packer.packInt(2); // pack binary data byte[] ba = new byte[] {1, 2, 3, 4}; packer.packBinaryHeader(ba.length); packer.writePayload(ba); packer.close();以上分别展示了对基本数据类型、array数组、map、二进制数据的打包用法。
- 通过 MessagePacker将数据直接打包输出流
首先通过packExtensionTypeHeader将自定义数据类型的type值和它的长度写入,这里指定这段数据的type=1,长度就是转为二进制数据后的长度,这里官方demo里有个错误,写了固定长度10,其实是有问题的,这里进行了修正写入extData的实际长度。然后用writePayload方法将byte[]数据写入。结束。可能这个Demo的展示还有点不太好理解,我们就上面的json样式进行进一步说明:假设我要将tabs下的数据样式定义为一个扩展类型,怎么去写呢?File tempFile = File.createTempFile("target/tmp", ".txt"); tempFile.deleteOnExit(); // Write packed data to a file. No need exists to wrap the file stream with BufferedOutputStream, since MessagePacker has its own buffer MessagePacker packer = MessagePack.newDefaultPacker(new FileOutputStream(tempFile)); // 以下是对自定义数据类型的打包 byte[] extData = "custom data type".getBytes(MessagePack.UTF8); packer.packExtensionTypeHeader((byte) 1, extData.length()); // type number [0, 127], data byte length packer.writePayload(extData); packer.close();
首先定义一个这样的数据结构:
然后指定TabsJson对象的type ExtType.TYPE_TAB=2,官方对自定义数据类型的限制是0~127。public class TabsJson { public int type; public String f = ""; }
然后对TabsJson对象进行初始化和赋值:
然后构造MessagePacker进行写入TabsJson tabsjson = new TabsJson(); tabsjson.type = 199; tabsjson.f = "abc";
packer1的作用就是将tabsjson对象打包成二进制数据,然后我们将这个二进制数据写到packer中。搞定。那解包的时候怎么做呢,后面我们会讲到。private static void packTabJson(TabsJson tabsJson, MessagePacker packer) throws IOException { MessageBufferPacker packer1 = MessagePack.newDefaultBufferPacker(); packer1.packInt(tabsJson.type); packer1.packString(tabsJson.f); int l = packer1.toByteArray().length; packer.packExtensionTypeHeader(ExtType.TYPE_TAB,l); packer.writePayload(packer1.toByteArray()); packer1.close(); }
这样通过自定义数据结构层层打包就完美解决了上面关于怎么将数据打包为复杂json样式的问题了。
必须注意打包结束后必须进行close,以结束此次buffer操作或者关闭输出流。2. 数据解包
两种用法与上面打包是对应的:
- 直接对二进制数据解包
需要注意的是解包顺序必须与打包顺序一致,否则会出错。也就是说协议格式的维护要靠两端手写代码进行保证,而这是很不安全的。MessageUnpacker unpacker = MessagePack.newDefaultUnpacker(bytes); int id = unpacker.unpackInt(); // 1 String name = unpacker.unpackString(); // "leo" int numPhones = unpacker.unpackArrayHeader(); // 2 String[] phones = new String[numPhones]; for (int i = 0; i < numPhones; ++i) { phones[i] = unpacker.unpackString(); // phones = {"xxx-xxxx", "yyy-yyyy"} } int maplen = unpacker.unpackMapHeader(); for (int j = 0; j < mapen; j++) { unpacker.unpackString(); unpacker.unpackInt(); } unpacker.close(); - 对输入流进行解包
以上例子展示了对自定义数据类型的完整解包过程,最后不要忘记关闭unpacker。FileInputStream fileInputStream = new FileInputStream(new File(filepath)); MessageUnpacker unpacker = MessagePack.newDefaultUnpacker(fileInputStream); //先将自定义数据的消息头读出 ExtensionTypeHeader et = unpacker.unpackExtensionTypeHeader(); //判断消息类型 if (et.getType() == (ExtType.TYPE_TAB)) { int lenth = et.getLength(); //按长度读取二进制数据 byte[] bytes = new byte[lenth]; unpacker.readPayload(bytes); //构造tabsjson对象 TabsJson tab = new TabsJson(); //构造unpacker将二进制数据解包到java对象中 MessageUnpacker unpacker1 = MessagePack.newDefaultUnpacker(bytes); tab.type = unpacker1.unpackInt(); tab.f = unpacker1.unpackString(); unpacker1.close(); } unpacker.close();
除此之外用户还可以自定义packconfig和unpackconfig,指定打包和解包时的配置,比如内存缓存byte[]数据大小等等。3. 其他杂谈
如果想省去如此繁琐的pack、unpack动作,而又想用messagepack,可以做到么?当然可以,我们可以利用java bean的序列化功能,将对象序列化为二进制,然后整个写入到messagepack中。
比如以上的TabsJson对象,在android中我们实现Parcelable接口以达到序列化的目的
打包和解包过程是这样的public class TabsJson implements Parcelable { public int type; public String f = ""; public TabsJson () { } protected TabsJson(Parcel in) { this.type = in.readInt(); this.f = in.readString(); } @Override public void writeToParcel(Parcel dest, int flags) { dest.writeInt(this.type); dest.writeString(this.f); } @Override public int describeContents() { return 0; } public static final CreatorCREATOR = new Creator () { @Override public TabsJson createFromParcel(Parcel in) { return new TabsJson(in); } @Override public TabsJson[] newArray(int size) { return new TabsJson[size]; } }; }
MessageBufferPacker packer = MessagePack.newDefaultBufferPacker();
Parcel pc = Parcel.obtain();
tabsjson.writeToParcel(pc, Parcelable.PARCELABLE_WRITE_RETURN_VALUE);
byte[] bytes = pc.marshall();
//先写入数据长度
packer.packInt(bytes.length);
//写入二进制数据
packer.writePayload(bytes);
packer.close();
pc.recycle();
//解包
MessageUnpacker unpacker = MessagePack.newDefaultUnpacker(packer.toByteArray());
byte[] bytes1 = new byte[unpacker.unpackInt()];
unpacker.readPayload(bytes1);
Parcel pp = Parcel.obtain();
pp.unmarshall(bytes1,0,bytes1.length);
pp.setDataPosition(0);
TabsJson ij = TabsJson.CREATOR.createFromParcel(pp);
pp.recycle();
unpacker.close();这种方式虽然省去了自己手写打包和解包的过程,但是不推荐使用。
笔者对第一部分示例的json数据,同一个itemdata数据段两种方式打包后文件大小对比如下:
| parcel方式 | 直接操作 | Json数据 | |
|---|---|---|---|
| 数据大小(byte) | 3619 | 2644 | 4090 |
可见parcel方式在压缩效率上比原始的json数据格式并无较大提升,因此不建议使用。
一句话总结一下Messagepack,简单好用,掌握原理后可以想怎么用怎么用。是比Json更轻便更灵活的一种数据协议。
作者:爱唱歌的王小猫
链接:http://www.jianshu.com/p/8c24bef40e2f
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。