编辑原理系列学习:编译器简介及Lexical analyzer
一、编译器简介
(1)概念
简单地说,编译器是一个程序,输入、输出均为字符串,其中输入字符串就是所谓的源程序,输出字符串就是目标程序。请对此有一个概念,我们编写好的程序就是以字符串形式线性地传入编译器,所以在编译器学习中我们讨论的对象就是字符串string。
(2)编译器与解释器
在介绍编译器时通常都会讲到另一种语言处理器:解释器。解释器直接利用用户提供的输入执行源程序中指定的操作,逐个语句地执行源程序。下面用图直观地解释编译器和解释器的区别:
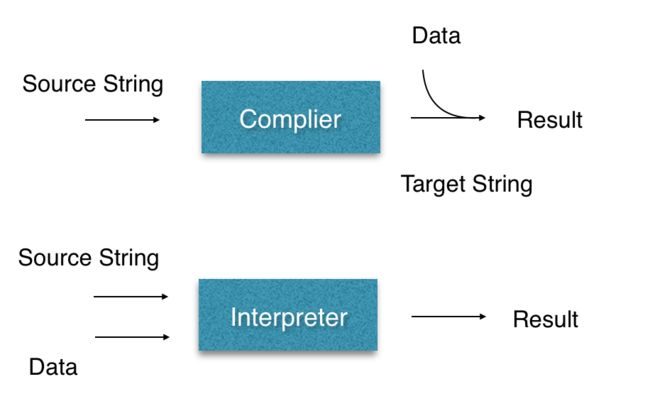
因此,编译器通常被描述为off-line,而解释器是on-line的。
(3)编译器结构
编译器的编译过程可分为五个步骤,以下对每个步骤的功能进行简要描述,并拿英语的学习进行类比以加深理解:
1. Lexical Analysis:将输入的string翻译成complier speak(token);
— 相当于英语学习中的理解句子中单词意思和角色;
2. Paring:由token在程序中的角色分析字符串结构,根据语法生成树
— 相当于英语学习中分析句子的结构:主谓宾等;
3. Semantic Analysis:分析string 的meaning,进行类型识别等操作
— 相当于英语学习中理解句子含义;
4. Optimization:不改变语义情况下,对某个指标进行提升;如常数折叠等;
— 相当于用改动句子某些结构,使句子更加精炼等;
5. Code Generation:产生目标机器语言。
在《编译原理 技术与工具》这本书中,将编译器的结构更加细分,分为了Lexical Analyzer、Syntax Analyzer(也就是paring)、Semantic Analyzer、Intermediate Code Generation、Code Optimizer以及Code Generator。相比之下,其实就是多了一个中间代码生成。在中间代码生成的过程中,有一种称为三址码(three-address code)的中间表示形式。这种中间表示的每个指令具有三个运算分量,形式为:
R3 = R1 op R2, op指的是某一操作,Ri为运算分量。
(4)说明
由于我参考的教材主要是《编译原理 技术与工具》英文版,参考视频为斯坦福大学的Compliers公开课,所以大多数概念以及某些说明、解释还是会用英文表示。请大家见谅。
二、Lexical Analyzer
Lexical analyzer的作用是将输入的字符串翻译成编译器能够明白的语言:Complier speak,就好像我们学习英语,在拿到一句英语句子时,我们会对句子中的单词进行辨析,在脑海中会形成我们所能理解的中文,然后再进行后续的工作。编译器的lexical analysis就相当于我们对英语句子的单词辨析,其结果是形成编译器所能理解的“中文”:Token。Token的组成为
(1)Token class
Token class(可简称class),是一个字符串集合,元素为表征“单词”类型的字符串。这种类型是一种广义的类型,有identifier、integer、keyword、whitespace、’(’ 、’)’ 、’.’ 、’;’ 等。
1.Identifier:
strings of letters or digits, starting with a letter.
2.Integer:
a non-empty string of digits.
3.Keywords:
“else” or “if” or “begin” or …
4.Whitespace:
a non-empty string of blanks, newlines and tabs.
注意:左括号、右括号、点、分号等是各自单独为一类的,即为单元素字符串集合。
(2)Lexeme
subStr,即原字符串中的子字符串,也称lexeme。通常我们会用一个指针或者索引代替,该指针或索引指向一个symbol table,table中存放变量名、变量类型以及编译器为之分配的内存地址等信息。
由上述,可以知道,lexical analysis 的目标就是将输入字符串分割,这种分割是从左到右的,每一次分割辨识一个token,这个token可以表明相应的lexeme在字符串中扮演的角色。因此在这个过程中有两件事是需要做的:
1. Recognize substrings corresponding to tokens.
(substring == lexeme)
2. Identify the token class of each lexeme.
在分割字符串过程中,需要从左到右进行扫描。由于每一次分割识别一个token,对于一个字符组合到底是不是一个identifier还是一个keyword,我们往往需要上下文进行判断。如当我扫描到一个字符组合“if”,这时并不能立刻下结论说它是一个keyword,还需要判断“f”的下一个字符c,对于C/C++,如果c为whitespace或者“(”,那么我们可以说“if”是一个keyword;如果c为一个字母或者数字,如“ifx”,那么“if”就应该是一个identifier中的一部分。在这个判断的过程中,我们通过往前看(即往字符串的下一位或者下几位看)而获得结果,这个“往前看”,就是所谓的Lookahead,这是lexical analysis中常用到的方法。在执行过程中,我们应该尽量让这个lookahead的次数最小化,如给这个次数一个常数边界。
三、Regular Language
(1)Language
Let ∑ denotes a set of characters, a language over ∑ is a set of finite-length strings of characters drawn from ∑ .
即, ∑ ={characters},Language L ={strings|c ∈ string ∧ c ∈ ∑ ∧ strlen(string) != infinite}
(2)Regular Language
这是一个字符串的集合,用于指定编程语言的lexical structure,即指定其token class。对于绝大多数的词法分析,Regular language具有足够的表达能力来完成任务,而且足够的高效,它的花销是输入字符串长度的线性函数。这就是我们使用regular language的原因。
(3)Regular Expression
Regular expression是regular language的标准表示,用于指定regular language,它是一种syntax。也就是说,它是用来指定语言的,在之后的自动机学习中,我们将会看到另一种指定语言的方式。
1. 两个原子表达式
single character
⇒ ’c’ ={“c”}
epsilon
⇒ ϵ = {’’}(注意,空串不是空集)
2. 三个复合表达式
Union
⇒ A+B={a | a ∈ A} ∪ {b | b ∈ B}
Concatenation
⇒ AB = {a++b | a ∈ A ∧ b ∈ B}(表示拼接)
Iteration
⇒ simple Iteration: Ai =AA…A(i个A拼接)
⇒ Kleene star Iteration: A∗ = ⋃i≥0 Ai
⇒ Kleene plus Iteration: A+ = ⋃i≥1 Ai
(4)Meaning Function
这里稍微介绍一下meaning function。Function大家都知道,表示的是一个映射。Meaning function表示一个从syntax到semantics的映射,也就是将expression映射到language(set of strings)上。其实meaning function的作用很简单,就是用来区分syntax和semantics的,即区分expression和language。
用L表示meaning function,则上面提到的五个表达式可重写为:
⇒ L( ϵ ) = { “” }
⇒ L(‘c’) = { “c”}
⇒ L(A+B) = L(A) ∪ L(B)
⇒ L(AB) = {a++b | a ∈ L(A) ∧ b ∈ L(B)}
⇒ L( A∗ ) = ⋃i≥0 L(Ai)
为什么需要区分呢?
首先是理解的问题。我们看复合表达式中的union,等号左边A、B是syntax,到了右边就神奇地变成集合了,难免在理解上造成混淆。
此外,其实很多时候syntax到semantics的映射不是一对一的,而是多对一,这也是要区分的原因之一。
最后,小结一下,
L(Regular expression) = Regular language,
regular expression用来描述定义token:s 属于 L(R),s就是substring,即lexeme。